La agregación de datos es el proceso de combinación de varias líneas de una tabla a través de funciones especiales llamadas
agregadores. Cada vez que se necesita realizar sumas, promedios, cuentas o medianas, los cálculos se realizan a través de agregadores. La agregación también proporciona un modo de combinar datos originados en diferentes tablas. Envision ofrece una sintaxis rica para respaldar todos esos escenarios. En esta sección, detallamos e ilustramos el modo en que funcionan los agregadores con Envision.
Un script ilustrativo
En esta sección utilizamos, una vez más, el
conjunto de datos de ejemplo, al que debería poder acceder desde la ruta
/sample en su cuenta de Lokad. El script a continuación es moderadamente complejo e ilustra algunos de los patrones de agregación de datos disponibles en Envision. La agregación de datos puede tener lugar tanto fuera como dentro de los mosaicos. Le recomendamos que lea
Haciendo cálculos con Envision primero, ya que le será útil para comprender los contenidos de esta sección.
read "/sample/Lokad_Items.tsv" as Items
read "/sample/Lokad_Orders.tsv" as O
read "/sample/Lokad_PO.tsv" as PO
expect O.Quantity : number
show label "Aggregating data" a1f1 tomato
oend := max(O.Date)
obegin := oend - 365
totalPurchased := sum(PO.NetAmount)
totalSold := sum(O.NetAmount) when date >= obegin
show table "Total purchased" a2c2 with
totalPurchased unit:"$"
show table "Sold over 1 year" d2f2 with
totalSold unit:"$"
VolumeSold = sum(O.NetAmount)
UnitSold = median(O.Quantity)
show table "Top sellers" a3f4 tomato with
Name
VolumeSold as "Sold" unit:"$"
UnitSold as "Median"
order by VolumeSold desc
avgRet := avg(distinct(O.Date) by O.ClientCode)
avgQty := avg(sum(O.Quantity) by [O.ClientCode, O.Date])
show table "Average client returns" a5c5
with round(avgRet)
show table "Average backet quantity" d5f5 with
avgQty
O.Brand = Brand
show table "Top Suppliers" a6f7 tomato with
Supplier
distinct(Category) as "Categories"
sum(O.NetAmount) as "Sold" unit:"$"
mode(O.Brand) if (O.Brand != "Fellowes") as "Most frequent brand sold"
group by Supplier
order by sum(O.NetAmount) desc
Le sugerimos que, para empezar, copie y pegue el script anterior en su cuenta de Lokad y que lo ejecute una vez para observar el panel de información resultante. Si todo funciona, debería ver el panel de información que se ilustra a continuación.
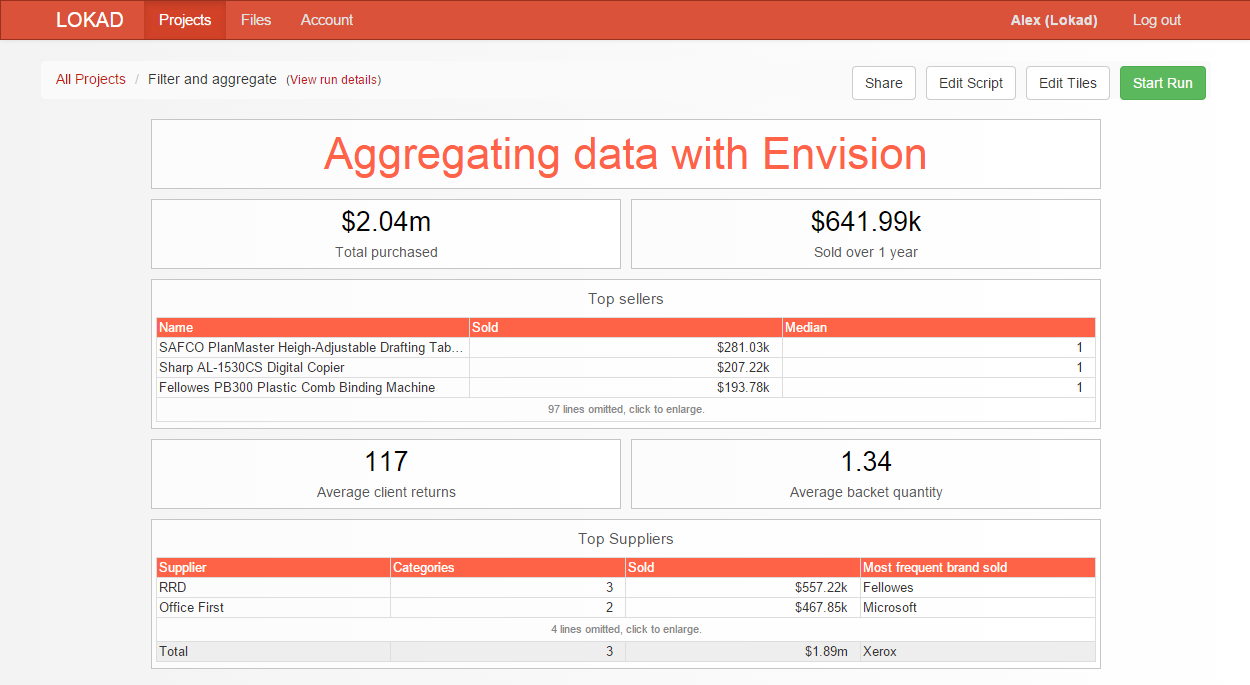
Escalares para agregaciones de un solo valor
Una variable que no tiene afinidad con ningún "artículo" en Envision se denomina variable escalar (la variable no está unida a ninguna línea específica de la tabla
Items). Pensando en la analogía de Excel, las variables de Envision son similares a las columnas de Excel por defecto: esas variables son vectores y contienen varios valores al mismo tiempo (de hecho, un valor por artículo). Si embargo, también es posible tener variables que se comportan como una sola celda de Excel, y que contienen solo un valor: esas son las variables escalares. El script anterior ilustra el modo en que es posible calcular dos variables escalares; las líneas pertinentes se copian a continuación para que resulte más claro.
totalPurchased := sum(PO.NetAmount)
totalSold := sum(O.NetAmount) when date >= obegin
show table "Total purchased" a2c2 with
totalPurchased unit:"$"
show table "Sold over 1 year" d2f2 with
totalSold unit:"$"
Es posible resaltar varios aspectos en estas pocas líneas de código. En primer lugar, las dos asignaciones en las líneas 1 y 2 se llevan a cabo utilizando
:=, el operador de asignación escalar. Cuando se utiliza el operador
:= en lugar del operador de asignación simple
=, significa que la agregación debería dar como resultado un solo valor que es independiente de los artículos.
En segundo lugar, las variables
totalPurchased y
tableSold comienzan con nombres en minúscula. Si bien los nombres de las variables no distinguen entre mayúsculas y minúsculas en Envision, el modo en que se escriben estas dos variables en este caso no es arbitrario. Como práctica de codificación, le recomendamos utilizar la minúscula para la primera letra de las variables que contienen valores escalares. En cambio, los nombres de las tablas y los nombres de las columnas deberían comenzar con letra mayúscula. Siguiendo estas directrices hará que su script sea más legible y más fácil de depurar.
En tercer lugar, la agregación escalar se produce por defecto dentro de la instrucción
show table si la tabla tiene una sola columna. Por ejemplo, las líneas 1 y 4 podrían combinarse en una sola instrucción
show table, como se ilustra a continuación.
show table "Total purchased" a2c2 with
sum(PO.NetAmount) unit:"$"
Las variables escalares numéricas también pueden utilizarse para realizar cálculos arbitrarios, como cualquier variable numérica en Envision. Por ejemplo, si bien podría no tener mucho sentido desde un punto de vista comercial, el siguiente cálculo podría agregarse al final del script de Envision una vez que se hayan definido las variables
totalPurchased y
totalSold:
mySum := (totalSold - totalPurchased) / 2
show table "My Sum" with mySum
Agregaciones multivalor
Envision también respalda la posibilidad de realizar agregaciones multivalor, generalmente agregando los datos a una determinada tabla y proyectando el resultado en las líneas de otra tabla. Así, la agregación es el método más frecuente para combinar datos que provienen de diferentes tablas. En particular, uno de los casos de uso más frecuentes consiste en tomar una tabla histórica, es decir, una tabla también indexada en una columna
Date, y agregar esta tabla a un vector alineado con la tabla
Items.
El script mostrado más arriba ilustra este patrón con una tabla que muestra los artículos más vendidos, es decir, los artículos pedidos de acuerdo con sus respectivos volúmenes de ventas, colocando los valores mayores al principio. Las líneas pertinentes del script se copian a continuación para que resulte más claro.
VolumeSold = sum(O.NetAmount)
UnitSold = median(O.Quantity)
show table "Top sellers" a3f4 tomato with
Name
VolumeSold as "Sold" unit:"$"
UnitSold as "Median"
order by VolumeSold desc
Las líneas 1 y 2 están realizando agregaciones de un modo que es muy similar a las agregaciones escalares que hemos visto en la sección anterior. Sin embargo, las asignaciones se llevan a cabo con el signo igual
= en lugar del operador
:= utilizado para las asignaciones escalares. Como resultado, tanto
VolumeSold como
UnitSold son vectores que forman parte de la tabla
Items. Como resultado, estas variables son similares a las columnas en Excel, y contienen un valor por artículo.
Tanto
sum como
median son funciones especiales llamadas agregadores en Envision. Existen muchos otros agregadores en Envision, como
avg,
min,
max,
first,
last, etc. Para ser concisos, no veremos todos los agregadores disponibles en Envision en esta sección; no obstante, si desea más información, puede consultar nuestra
lista completa de agregadores.
El resultado de estas dos agregaciones se muestra en la tabla definida con las líneas 3 a 7. Los vectores
VolumeSold y
UnitSold se enumeran como argumentos después de la palabra clave
with, y sus valores se muestran en la tabla. Por último, en la línea 7, la instrucción
order by indica que la tabla debería ordenarse comenzando con los artículos que tienen los valores
VolumeSold mayores.
Los lectores que estén familiarizados con la sintaxis
GROUP BY en SQL podrán preguntarse cómo sabe Envision qué agrupamiento debería utilizarse al calcular la
sum en la línea 1. Por defecto, Envision realiza un agrupamiento utilizando las columnas que funcionan como "claves" del lado derecho de la asignación. En el caso de una variable que pertenece a la tabla
Items —la tabla cuyo nombre está implícito—, la columna que actúa como clave (primaria) es la columna
Id. Esto explica por qué se obtiene una agregación por artículo al utilizar el signo
=.
Grupos de agregación explícita con by
Hasta aquí, las agregaciones que hemos llevado a cabo se valían de los patrones de agregación implícita de Envision. Sin embargo, el comportamiento de todos los agregadores puede modificarse con una palabra clave opcional
by que se utiliza para especificar explícitamente el agrupamiento aplicable. Ilustremos el modo en que se utiliza la palabra clave
by
VolumeSold = sum(O.NetAmount)
SameVolumeSold = sum(O.NetAmount) by Id // Same!
La línea 2 se asigna a un segundo vector llamado
SameVolumeSold, pero los valores de este vector son estrictamente idénticos a los del vector
VolumeSold en la línea 1. De hecho, en la línea 1, también se utiliza (aunque implícitamente) la opción
by Id. Intuitivamente, cuando se utiliza la opción
by, es como si los grupos se crearan primero de acuerdo con el objetivo de agrupamiento y luego como si el agregador se calculara para cada grupo por separado.
La opción
by ofrece la posibilidad de componer agregaciones bastante complejas, como se ilustra en el script al principio de esta sección. Veamos las dos líneas de script en las que se realizan las agregaciones a través de opciones
by.
avgRet := avg(distinct(O.Date) by O.ClientCode)
avgQty := avg(sum(O.Quantity) by (O.ClientCode, O.Date))
El agregador
distinct cuenta el número de valores distintos observados dentro de cada grupo. En la línea 1, primero se agrupan las líneas de la tabla
O (pedidos) de acuerdo con sus respectivos valores
ClientCode y luego se cuenta la cantidad de fechas de pedido distintas para cada cliente. Intuitivamente, esta agregación puede interpretarse como el recuento de la cantidad de veces que ha regresado cada cliente. Luego, este resultado se agrega nuevamente en un solo valor escalar con el agregador
avg que contiene la agregación interna
distinct.
El escalar
avgQty puede interpretarse como la cantidad de unidades compradas por cesta. El cálculo comienza con una instrucción
sum() by; sin embargo, después de la opción
by, no tenemos una sino dos variables separadas por comas y enumeradas entre paréntesis:
(O.ClientCode, O.Date). Esta sintaxis debería interpretarse del siguiente modo: crear un grupo para cada par de
ClientCode y
Date. Desde una perspectiva de negocios, estamos tratando a todas las unidades compradas el mismo día como parte de la misma cesta, lo cual es una aproximación razonable para la mayoría de las situaciones. Por último, la llamada externa a
avg genera el promedio final en todos los agregados
sum calculados para todos los pares.
En términos más generales, la opción
by respalda una cantidad arbitraria de variables después de la sintaxis
sum(foo) por (arg1, arg2, …, argN). En la práctica, sin embargo, es bastante raro encontrar situaciones en las que tenga sentido agrupar de a más de 4 variables por vez. Además, el orden de los argumentos no afecta los grupos resultantes utilizados para calcular los agregados.
Agregación explícita dentro de una tabla con group by
A veces, a través de la agregación, es posible elaborar una nueva tabla que sea más relevante para ser utilizada dentro del panel de información que la tabla original no agregada. Por esta razón, Envision también respalda la posibilidad de agregar datos directamente desde la instrucción de declaración del mosaico. El modo más directo de visualizar esta capacidad de Envision es agregar los datos que se mostrarán en una tabla. Esto es precisamente lo que hacemos en el script al principio de esta página. Observemos nuevamente el las líneas pertinentes copiadas a continuación.
O.Brand = Brand
show table "Top Suppliers" a6f7 tomato with
Supplier
distinct(Category) as "Categories"
sum(O.NetAmount) as "Sold" unit:"$"
mode(O.Brand) if (O.Brand != "Fellowes") as "Most frequent brand sold"
group by Supplier
order by sum(O.NetAmount) desc
La instrucción
show table va desde la línea 2 hasta la línea 8 y, más específicamente, la agregación se especifica en la línea 7 con la instrucción
group by, que tiene la misma semántica que la opción
by que hemos visto en la sección anterior. En este punto, tal vez se pregunte por qué Envision no utiliza la palabra clave
by en lugar de
group by si la semántica es la misma. El
if en la línea 6 es un filtro de agregador, del que hablaremos en la sección siguiente.
La respuesta es simple: es posible utilizar la opción
by dentro de la lista de expresiones utilizadas después de
with para un determinado mosaico (esta situación, sin embargo, no se ilustra aquí). Así,
group by permite diferenciar entre una instrucción
by que es parte de una expresión pasada al mosaico y una instrucción
group by que se aplica a un mosaico en conjunto. En otras palabras, el
group by se aplica a todas las expresiones enumeradas después de la palabra clave
with, a diferencia de la instrucción
by, que solo tiene impacto local.
Cuando se utiliza
group by, todas las expresiones pasadas al mosaico después de la palabra clave
with deberían ofrecer la posibilidad de ser agregadas. Por ejemplo, el script de una sola línea a continuación es incorrecto, porque
Name no ofrece un patrón de agregación, mientras que se especifica
group by Supplier.
show table "WRONG!" with Name group by Supplier
Sin embargo, si modificamos este script introduciendo un agregador, por ejemplo
distinct, nuestro script de Envision se vuelve válido.
show table "CORRECT!" with distinct(Name) group by Supplier
La única excepción a esta regla es la agregación del objetivo mismo. En el script al comienzo de esta sección, tenemos una instrucción
group by Supplier en la línea 7. En la línea 3, la variable
Supplier aparece sin ningún agregador; aun así, el script sigue siendo válido, precisamente porque el agrupamiento tiene lugar de acuerdo con la variable
Supplier.La necesidad de exponer un agregador también aplica para la instrucción
order by en la línea 8. De hecho, la tabla se agrega primero por proveedor, y solo después se ordena de acuerdo con la columna
Id, a menos que se especifique otro tipo de ordenamiento. Como resultado, Envision necesita calcular un valor por grupo para ordenar todos esos grupos. Esto es exactamente lo que sucede con la instrucción
group by sum(O.NetAmount).
Si bien ilustramos
group by con el mosaico
table, esta sintaxis no es específica del mosaico
table, y es posible utilizar el mismo patrón con la mayoría de los demás mosaicos. Por ejemplo, sería posible extender el script que aparece al principio de esta página con un mosaico
barchart agregado por
Brand.
show barchart "Sales by brand" with
sum(O.NetAmount)
group by Brand
El
group by también respalda el agrupamiento múltiple, es decir, el agrupamiento por vectores múltiples o expresiones múltiples, con una sintaxis idéntica a la de la opción
by que hemos comentado anteriormente.
Filtros de agregación
Los agregadores de Envision también admiten
filtros a través de la palabra clave
if. El script a continuación ilustra el uso de un filtro de este tipo en la línea 6:
O.Brand = Brand
show table "Top Suppliers" a6f7 tomato with
Supplier
distinct(Category) as "Categories"
sum(O.NetAmount) as "Sold" unit:"$"
mode(O.Brand) if (O.Brand != "Fellowes") as "Most frequent brand sold"
group by Supplier
order by sum(O.NetAmount) desc
Aquí, la marca
Fellowes se excluye explícitamente del reporte a través del filtro
if. Los filtros son útiles dentro de la instrucción mosaico porque ofrecen la posibilidad de filtrar cada columna por separado. En cambio, un filtro
where posicionado fuera de la instrucción mosaico hubiera filtrado todas las líneas seleccionadas de la tabla
O de modo indiferente para todas las columnas.
Los filtros también pueden utilizarse dentro de una línea:
TwoAndMore = sum(O.1) if (O.Quantity >= 2)
