クォンタイルグリッドと予測
クォンタイルグリッドは、在庫が絡むケースで、古典的な予測方法を超えて、遥かな進歩を遂げています。将来についてより多くの情報を配信するので、クォンタイル予測よりも優れています。
 従来の予測手法は、特にコマースでは十分に機能しません。この問題の根本的な原因は単純です。将来は不確実です。クラシック予測は将来の需要を正しく予測しようとし、そして、その予測に失敗します。「正しい」将来の需要が予測可能である事を期待して、やみくもに古典的な予想が可能だと考えるのは妄想でしかありません。クォンタイルグリッドは、この問題に対して、完全に異なる立場をとります。Lokadは、クォンタイルグリッドで、指定された製品に、1つだけの将来需要値を予測するのでなく、需要全体の確率分布を予測します:0個の場合の需要確率、1個の場合、2個の場合など。この情報は非常にリッチであり、古典的な予想よりも非常に収益性の高い方法で活用できます。
従来の予測手法は、特にコマースでは十分に機能しません。この問題の根本的な原因は単純です。将来は不確実です。クラシック予測は将来の需要を正しく予測しようとし、そして、その予測に失敗します。「正しい」将来の需要が予測可能である事を期待して、やみくもに古典的な予想が可能だと考えるのは妄想でしかありません。クォンタイルグリッドは、この問題に対して、完全に異なる立場をとります。Lokadは、クォンタイルグリッドで、指定された製品に、1つだけの将来需要値を予測するのでなく、需要全体の確率分布を予測します:0個の場合の需要確率、1個の場合、2個の場合など。この情報は非常にリッチであり、古典的な予想よりも非常に収益性の高い方法で活用できます。
非統計のすすめ
あなたが統計学者でないなら、この文を読んでいる間、「クォンタイルグリッド」と呼ばれるやり方に懸命に従って行く事で、ビジネスに何のチャンスが生まれるのかと訝しく思うかもしれません。博士論文のタイトルに実践的な予測手段よりも、現代的統計というタイトルを付けた方がいいように聞こえます。この用語が威圧的だと思われる場合、頭の中で「クォンタイルグリッド」を「実際に役に立つ予測」に置き変えて下さい。Lokad を使用している企業の大半は、統計的なスキルは何も持っていません。あなたの受信トレイに付属しているスパムフィルタは、高度な統計情報を使用していますが、受信トレイを使用する上で、博士号を取る必要はありません。Lokadは、これと、ほぼ同じようなコマースを行っています。我々は、会社により利益をもたらすために、高度なメカニズムの知識を活用していますが、その背後にある技術について、実際にそんな事を殆ど気にする必要がないように進化しています。以下で、Lokadの舞台裏で何が起きているのかを説明していますが、我々の予測エンジンに何を入れるのか?を完全に理解していない場合でも、ベイズ確率推論を熟知せずにスパムフィルタを使用しているように、Lokadを使う事が出来きますので安心して下さい。コマースの予測を再考する。
多くのベンダーは、ARIMA、ボックス•ジェンキンス、ホルト・ウィンタースのような 「高度な」予測方法を使っている事を自慢しますが、それらは、半世紀以上も古い方法で:今日の冷蔵庫が持っているよりも処理能力が劣る、当時の強力な企業コンピュータを使って考案されました。これらのメソッドを発明した人は非常に賢い人ですが、当時のコンピューティング・リソースを使う以外の方法がなかったので、少ない計算を処理するモデルを優先しました。今日、我々は非常に少ないコストで、予測課題に大量の計算能力を使用することができます。
ARIMA、ボックス・ジェンキンス、ホルト・ウィンタースのようなメソッドは、今日の冷蔵庫が持っているよりも処理能力が劣る、コンピュータを使って考案されました。
クラウド・コンピューティング・プラットフォームを使用した場合、1000時間の計算にかかるコストが、50ドル未満ということを心にとめておいて下さい。明らかに、このことは、予測の全く新しい展望を開き、まさに、これこそLokadが広く探求してきた視点です。
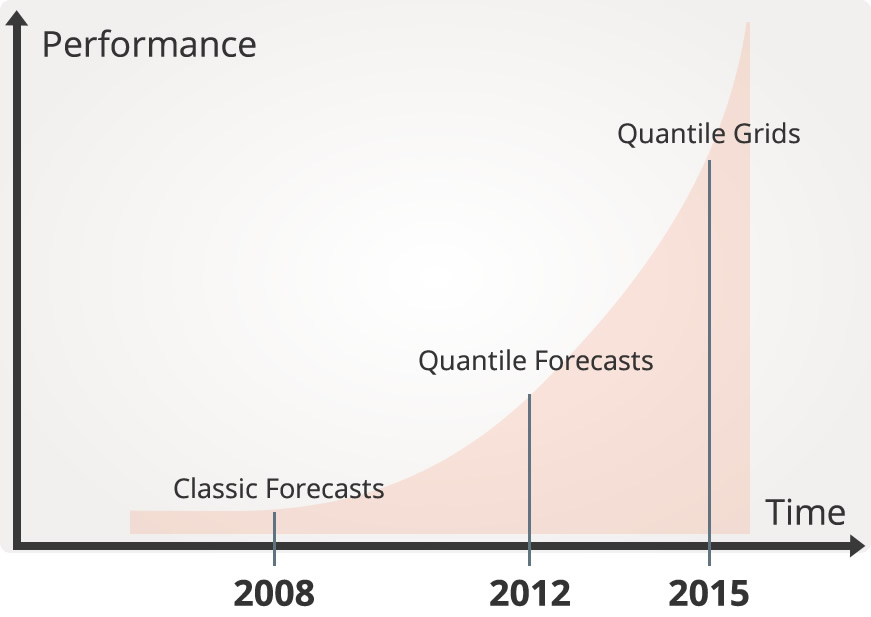
クォンタイルグリッドは、Lokadの予測技術の3番目のバージョンですが、全貌を知るために数年前に戻ってみましょう。当社は、予測技術の最初のバージョンとして2008年に古典的な予測を行う事からスタートしました。一部のLokadチームの3年間にわたる多大なR&D活動にもかかわらず、古典的なアプローチは行き止まりである事が判明しました。我々は、古典的な予測で、顧客を深く感動させる事が出来ませんでした。他の予測ベンダーの顧客の体験について詳細を調べてみると、彼らの予測技術でもって、少しでも顧客を満足させた企業が一つもない事が分かりました。Lokadに固有な問題ではなく、予測業界全体が機能不全に陥っている事に気づき:それに対して、行動する事を決めたのです。
2012年、予測技術の第2バージョンである、 クォンタイル予測をリリースしました。 簡単に言えば、クォンタイル予測は、古典的な予測を悩ませているNo1の問題に対処しました:古典的な予測は、問題を正しく捕えてもいません。確かに、企業の課題は、両極端を避ける事で:つまり、在庫切れを引き起こす高い需要と、デッド在庫を引き起こす予想外の低い需要の極端なケースです。将来の需要を、ビジネス観点からごく僅かな「期待」とすると、その真ん中で何が起きるのでしょうか。平均値または中央値予測を行う古典的な予測は、完全にこれらの「極端」な状況を無視して、平均的なケースにのみ焦点を当てます。当然のことながら、古典的な予測は、在庫切れとデッド在庫の両方を防止する事に失敗します。クォンタイル予測は、関心のあるシナリオ、つまり在庫切れを避ける事に、正面から直接向きあって、この課題にアプローチし、まさにこの問題に正確に答える努力をしています。2012年に、突然、多くの満足する顧客を持ち始めました。 Lokadの歴史の中で初めて、会社設立後、3年以上たった後、やっと、役に立てる素晴らしい製品を持つ事ができました。
2015年にLokadは、予測技術の3番目のバージョンであるクォンタイルグリッドをリリースしました。クォンタイル予測は、すでに古典的な予想を超える劇的な進歩でしたが、まだ弱点がありました。我々は、数十のクォンタイル予測技術を展開して、より多くの経験を得る中で、たった「一つ」のビジネスシナリオに対して予測を行う考えは完全ではない事に気づきました。なぜ、この1つだけのシナリオなのか?なぜ、第2または第3のシナリオではないのか?複数のシナリオを手動で管理するのは、面倒である事が証明され、全てのシナリオを一度に予測する必要がある事に気づきました。コンピューティングの観点から見ると、かなり多くの費用がかかりました。すべての製品に、(ほとんど)すべての単一要求レベルに対して、それぞれの確率を計算することになります。関連する計算量は驚異的に見えますが、コンピューティング・リソースの価格も年々下がってきています。5年前に、コストがかかりすぎると心配しましたが、今は、非常に手頃な価格になりました。
2015年にLokadは、その予測技術の3番目のバージョンである、クォンタイルグリッドをリリースしました。大量の計算を必要としますが、クラウド・コンピューティング・リソースの価格低下のおかげで、今や、クォンタイルグリッドは手頃な価格になりました。
需要の確率分布全体を掴む

将来の需要は不明です。ただ一つの値で将来の需要を表現する試みは、単純であると言えます。なぜなら、この値がどれほど素晴らしくても、全てを物語る事が出来ないからです。将来の需要の正確なレベルを予測することができる「魔法」のシステムだとしても、やはり、妄想に過ぎません。人は、間違った予想を扱おうとする場合、この予測の「修正」を試みる事を非常に魅力的に感じるかもしれません。残念ながら、統計的予測は大いに反直感的で、現実に何度も修正すべきものは存在ません:従来の需要に対する予測値は、完璧で有効な値の一つにすぎません。システムは、将来の需要に対して可能性の高い値を出す為に潜在的に微調整が必要になっており、実際その程度のものです。会社は、将来の需要に対する、ごくわずかな可能性のある値を取得するにとどまり、本来、期待していた事業活動の押し上げには繋がりません。
クォンタイルグリッドは全く異なったアプローチを取ります:Lokadは、すべての製品に対して、将来の需要に対する単一レベルの確率を計算します。将来の需要を知っているような妄想を持つ代わりに、クォンタイルグリッドは、直接、様々な将来の可能性に対して、確率を示します。例えば、2週間のリードタイムを持つ、時々売れるような製品について考えてみると、次の2週間(通常、予測範囲は、リードタイムと一致する必要がある)にわたる需要分布は、以下のようになります:
| デマンド | 確率 |
|---|---|
| 0 ユニット | 55% |
| 1 ユニット | 20% |
| 2 ユニット | 14% |
| 3 ユニット | 7% |
| 4 ユニット | 3% |
| 5 ユニット | 0% (丸められ) |
完全に確率的観点から将来を考えることは複雑ですが、全てのビジネス幹部が、正式な方法ではなくとも、常に行っている事を実際に表現しており、彼らは、最も重要なシナリオに対処する際、特定の結果の確率を計算し、賭け対熟考対策の間のヘッジを行うのです。
予測エンジンの観点から、「最も重要」なシナリオがどうなるのか事前にわからないので、論理的な解決策は、少し酷な方法ですが、すべての可能性のあるシナリオを処理する方法をとっています。
クォンタイルグリッドは全く異なったアプローチを取ります:Lokadは、すべての製品に対して、将来の需要に対する単一レベルの確率を計算します。
しかし、予測する千の製品を持つビジネス(我々の顧客の中には対処すべき数百万のSKUを持っている)を前提とすると、Lokadは、製品毎に100のシナリオに関連した確率を計算し、クォンタイルグリッドは、実用的とは思えないような、100,000件のエントリを持つ巨大なリストを生成する事になります。我々は、以下のセクションで、この点について解説します。
すべての購入決定において、単純に、「アナグラム」に対する式は、将来の需要対現在の購入決定に依存するといった、大ざっぱな計算ができます。そして、一つ一つの決定は、将来の需要の全レベルに対応した確率に基づいているので、点数化する事ができます。
サプライチェーンの決定の優先順位付け
需要予測は、一般的に、コマースに発注したり、工業環境での生産バッチをトリガーしたりする為の、サプライチェーンの決定を行う為に使用します。将来のアナグラムに関連したすべての確率を持つなら、購入決定の為の完全な優先順位リストを構築することが可能です。実際、すべての購入決定において、単純で大ざっぱな計算が可能で、「アナグラム」式:需要をDとし、購入をPとすると、金融成果はXになります。言うまでもなく、Lokadは、この短い式を書く支援の為に存在しており、殆どのビジネスで、売上総利益率から在庫のコストと在庫切れコストを差し引くという簡単な式に要約できます。結果として、一旦この式を手に入れると、すべてのサプライチェーンの「Zユニットの製品から1ユニットを購入」のような意思決定をする上で、成果を、一つ一つの将来の可能性に対する確率と比較検討することができます。こうする事で、すべての可能な意思決定「スコア」が計算出来ます。
すべての決定を点数化すると、リストの先頭に最も利益の高い選択を置いて、すべての決定をランク付けすることが可能です。我々はこのリストを**マスター購入優先度リスト**と名付けています。これは、すべての製品を、多数行に表示したリストです。確かに、Zユニットの製品から1ユニットを購入するが、購入決定のトップ(別名:最も緊急な購入)にランクされていますが、その間に、その他の製品が色々なユニットで購入されると、Zユニットの製品から次の1ユニットを購入するのは、最も緊急な購入の20番目になるかも分かりません。
マスターリストは、非常に簡単な質問に答えます。ある会社が在庫に使える余分な1ドルを持っているとすると、この1ドルは、最初にリストされるべきでしょうか?このドルは、会社に最大のリターンを与えるアイテムとしてリストする必要があります。この特定のアイテムが取得された後、同じ質問を繰り返す事が出来ます。しかし、この場合、一旦余分なアイテムを取得した後は、在庫内に同じアイテムが積み上げられると、リターンが激減するので、購入すべき最も収益性の高い次のアイテムは別のものである可能性が高くなります。確かに、少ない在庫が反転して、より多くの在庫になり、デッド在庫に立ち往生してしまう確率が高くなります。これらの問題は当然「アナグラム」式に反映され、リストの優先順位付けの結果に反映されます。
サービスレベルの微調整よりもベターな事

「最適な」サービスレベルーつまり ― 在庫切れしない所望の確率を見つけ出すのは、非常に困難な問題です。これは、サービスレベルが、会社の財務業績と間接的にのみ関連しているので複雑な問題です。事実、幾つかの製品が、サービスレベルを1%あげるにはとても高くつく事が証明されると、資源が容易に入手可能な場合、むしろ、同一の投資レベルで、1%でなく10%のサービスレベルが向上する他の製品に割り当る事になります。
マスター購入優先順位リストとして使用してされクォンタイルグリッドでは、内部的な優先順位付け自体に反映するサービスレベルを気にする必要すらありません。利益率の高い製品のサービスレベルを、安く高める事が出来れば、この製品は、当然、リストの一番上に登ります。逆に、製品が激しく不安定な販売に苦しんでいる場合、サービスレベルを向上させる試みは、非常に高価になり、この製品は、在庫が危険なほど低い場合、または、非常に不安定な需要パターンにもかかわらず会社がデッド在庫にしない保障している場合のみリストの一番上に上昇します。
優先リストはまた、現金の制約の問題も解決します。現金がそれ程多くない会社であっても、優先順位リストは、扱いやすいオプションを提供します。ほんの少しの現金しかなければ、製品の在庫レベルを維持する為に、絶対に必要な補充の為だけに、リストの最上部にあるものだけを買う事ができます。余分な現金を持っている場合は、会社は、在庫リスクを制御しながら、会社の成長を牽引するアイテムに着目して在庫を増やす選択肢を持ちます。
サプライチェーンの制約を投入
企業は、SKUレベルで、またはオーダーレベルで、最小注文数量などの供給制約に頻繁に、対処しなければなりません。時には、ユニットはコンテナなどのような大きな単位にする必要があります。このような制約は、上記で説明したように、マスター購入優先順位リストを介して、1つのワークフロープロセスに組み込む事が出来:購入の優先順位の提案を提供するだけでなく、その注文制約に適合する推奨アイテムをも提供します。
プロセスは、ビジネスの実際の制約タイプに依存します。例えば、出荷容器について考えてみましょう。Lokadは、購入ラインがリストの順に処理されると仮定し、各サプライヤーが、他のサプライヤーから独立して出荷すると仮定すると、サプライヤーごとの累積体積を計算することができます。これらの累積的なボリュームに基づいて、目的コンテナの容量までリストの順に処理するプロセスは非常に簡単な事です。
同様に、SKUに、最小発注数量制約がある場合も、制約が満たされる前に全行をリストから取り除いたり、制約が満たされると先頭行にして、容量を表示したりするのは簡単な事です。Nユニットを最小値に設定して購入させようとする事は、SKUの競争力を低下させます。すなわち、最小注文量によって、在庫リスクを増加するように意図した動作であり、SKU は最低ランクとしてリストされます。
特に、このアプローチは、古典的アプローチとクォンタイル予測に悪い影響をもたらした、長年の課題に対処します:示唆した再注文量が、注文制約より多いまたは少ない場合にどうすべきか?一部のユニットを削除する必要がある場合、どの製品を最初に削除すべきか?ユニットを追加する必要がある場合は、どの製品をより多く購入する必要があるのか?古い予測メソッドは、これらの質問に対して、満足できる答えを提供しませんでした。優先購入リストを使うと、これらのニーズに答えるのはリストの順序に従った1製品のみになります。