使用分位数网格预测
2016 年 5 月更新:概率预测的表现优于分位数网格(第 4 代预测引擎)。
任何时候只要涉及到库存,使用分位数网格会比使用传统预测法获得根本上的改善。由于分位数网格能够提供有关未来需求的更多信息,因此这种方法也比分位数预测更出色。
 传统预测法的效果较差,尤其是在商业领域。其根本原因很简单:未来是不确定的。传统预测试图预测出一个正确的有关未来需求的值,它们没能做到这一点。不顾一切地想修复传统预测从而预测出“正确”的未来需求,这简直就是妄想。而分位数网格对此问题持有截然不同的态度。借助分位数网格,Lokad 并非只是为指定产品预测出一个有关未来需求的值,而是提供有关需求的完整概率分布:0 需求的概率,需要 1 件产品的概率,需要 2 件产品的概率等等。这些信息更丰富,并且可以按照比传统预测更有利的方式加以利用。
传统预测法的效果较差,尤其是在商业领域。其根本原因很简单:未来是不确定的。传统预测试图预测出一个正确的有关未来需求的值,它们没能做到这一点。不顾一切地想修复传统预测从而预测出“正确”的未来需求,这简直就是妄想。而分位数网格对此问题持有截然不同的态度。借助分位数网格,Lokad 并非只是为指定产品预测出一个有关未来需求的值,而是提供有关需求的完整概率分布:0 需求的概率,需要 1 件产品的概率,需要 2 件产品的概率等等。这些信息更丰富,并且可以按照比传统预测更有利的方式加以利用。
针对非统计学家的简介
在您阅读这些文字时,如果您不是统计学家,您可能会好奇您的公司是不是也有可能通过“分位数网格“执行任何切合实际的处理。这就好像是一篇博士论文的标题使用“现代统计会”比使用“实用的预测方法”要好一样。如果您觉得这个词吓到您了,那么可以在心里用“真正有用的预测“来代替“分位数网格“,这样是完全可以的。绝大部分使用 Lokad 的公司都不具备统计学方面的技能。和您的收件箱有关的垃圾邮件过滤器也利用了高级统计学,但并非只有博士才懂得使用收件箱。Lokad 在商业领域的运作与此大体相同。我们利用先进的机器学习来提高贵公司的盈利性,其技术背景先进,事实上您不必对此过多关注。下文将介绍 Lokad 的技术背景,但是请放心,即便您没有完全理解我们的预测引擎,您同样可以使用 Lokad,这就和您不熟悉贝叶斯概率推理但会使用垃圾邮件过滤器差不多是一个道理。 针对商业领域的再思考
很多供应商鼓吹他们使用的是"高级"预测法,例如 ARIMA、博克思-詹金斯法和 Holt-Winters 法,这些方法实际上存在有半个世纪之久了;在这些方法问世的那个年代,最强大的企业计算机的处理能力还不如当今的大部分冰箱。这些方法的发明者自然是异常聪明的,但他们不得不勉强应对那个年代的计算资源,因此会偏爱只需极少运算就能得出计算结果的模式。而在当今,我们只需要花极少的成本,就可以使用巨大的计算能力执行预测。
ARIMA、博克思-詹金斯法和 Holt-Winters 法,这些方法实际上存在有半个世纪之久了;在这些方法问世的那个年代,最强大的企业计算机的处理能力还不如当今的大部分冰箱
请别忘了,在使用云计算平台时,1000 小时的计算能力只需要花不到 50 美元的成本。显而易见,这为预测开辟了全新视角,而 Lokad 正是对这一视角进行了广泛的挖掘探索。
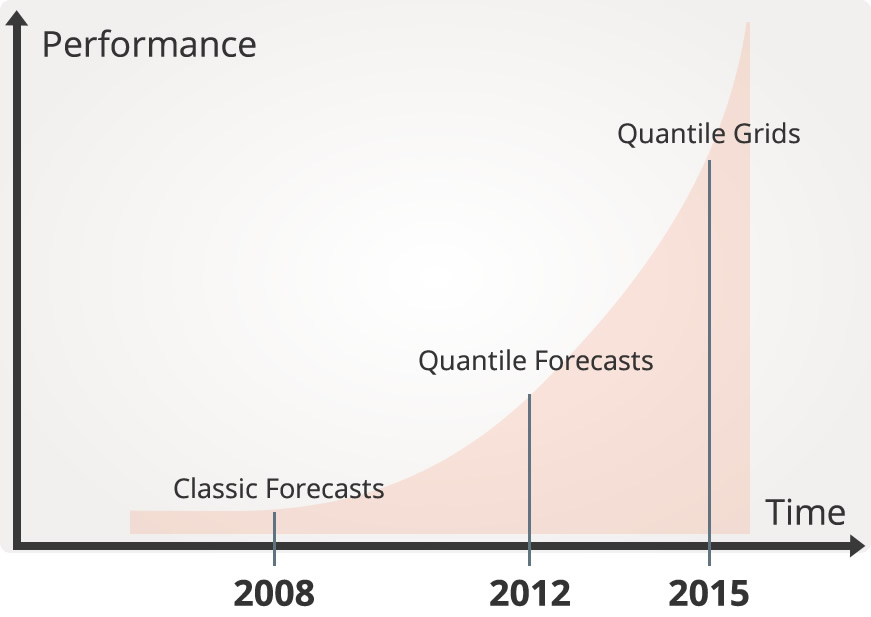
分位数网格是 Lokad 预测技术的第三个版本,我们来回顾一下前几年的情况以便进行全面了解。在 2008 年我们开始将传统预测作为预测技术的第一个版本,尽管 Lokad 团队在研发方面付出了 3 年的巨大努力,但最后还是证明这种传统方法是一个死胡同。没有任何一个客户对传统预测结果满意过。在我们进一步了解到客户与其他预测供应商的合作经历后,发现没有哪一家公司曾对他们所用过的预测技术满意。这个问题并非只有 Lokad 才有,于是我们意识到整个预测行业都处于机能失调状态;所以决定要有所作为。
2012 年,Lokad 发布了预测技术的第二个版本 - 分位数预测。简单地说,分位数预测解决了传统预测存在的第一个问题:传统预测没有着眼于正确的问题。实际上,公司的挑战在于避免两个极端:意料之外的导致缺货的高需求,以及意外之外的导致库存积压的低需求。位于二者之间的未来需求为“预期”需求,从商业角度说其意义不大。但传统预测(也就是平均数或中间数预测)则完全忽略了这些“极端“情况,只专注于平均情况。因此传统预测无法防止缺货和库存积压也就不足为奇了。而分位数预测则是直面这一挑战,直接着眼于相关情况,也就避免缺货、并且力求为这个问题提供准确的答案。于是从 2012 年起,我们突然开始收获越来越多对我们满意的客户。在公司成立 3 年之后,Lokad 终于头一回有了成就。
2015 年,Lokad 发布了预测技术的第三个版本 – 分位数网格。虽然分位数预测大大优于传统预测,但仍存在不足之处。随着分位数预测技术的不断发展,我们的经验也越来越丰富,于是意识到为“一种“业务方案提供一项预测的观点看似合理,但并不全面。为什么只有这一种方案?为什么没有第二种乃至第三种方案?手动管理多个方案枯燥乏味,并且我们认识到所有方案应当同时预测。从计算角度说,成本明显高出许多:针对每种产品,我们要计算其在(几乎)每种需求水平的相应概率。但尽管计算量惊人,这几年来计算资源的价格直线下降。早在 5 年之前还被认为成本太高的资源,现在则完全负担得起了。
2015 年,Lokad 发布了预测技术的第三个版本 – 分位数网格。尽管计算异常密集,但由于云计算资源价格的直线下降,现在也负担得起分位数网格的成本了。
获取需求的完整概率分布

未来的需求是不确定的。任何妄图用一个值表现未来需求的尝试都是无知的,不论这个值多好,都无法体现全面的情况。如果有一个“神奇“的系统能够预测未来需求的准确水平固然好,但这同样是妄想。人们在尝试处理不准确的预测时,往往会倾向于“修复“这一预测。但遗憾的是,统计预测很大程度上是反直观的,而且现实就是常常没有可修复的对象:预测出来的值是有效值之一,并且也是未来需求的一种可能结果。系统经过微调是可以生成有关未来需求的可能性更高的值,但也就仅此而已。您的公司最终得到的也不过是一个可能性略高一点的未来需求值,并不能按原本预期的那样推动商业活动。
分位数网格则采取截然不同的方法:针对每种产品,Lokad 会计算其在未来每种需求水平上的相应概率。分位数网格不会尝试保持未来需求是已知的这样一种假象,而是直接表现与未来多种可能情形相关的概率。举个例子,如果我们考量一种偶尔销售且交付周期为 2 周的产品,该产品在接下来 2 周(一般预测水平线必须匹配交付周期)内的需求分布如下:
| 需求 | 概率 |
|---|---|
| 0 件 | 55% |
| 1 件 | 20% |
| 2 件 | 14% |
| 3 件 | 7% |
| 4 件 | 3% |
| 5 件 | 0%(四舍五入) |
完全从概率角度思考未来看似复杂,但实际上每一位企业高管都在这么做,虽然用的是不太正式的方式:权衡产生特定结果的几率,同时留好退路,以便在处理最恰当的方案时做好万全准备。
从预测引擎的角度说,由于我们事先不知道“最恰当“的方案是什么,那么合乎逻辑的解决方案就是处理一切可能的方案,虽然这种方法有点过激。
分位数网格则采取截然不同的方法:针对每种产品,Lokad 会计算其在未来每种需求水平上的相应概率。
但是,假设企业要预测一千种产品(我们有些客户甚至要处理数百万个 SKU),并且 Lokad 要为每种产品计算 100 种方案的相关概率,那么分位数网格将产生多达 10 万个条目的巨大列表,这对于处理是不实际的。下文将对此进行说明。
对于每种采购决策,我们可以写出简单的粗略计算,“结果“公式取决于未来需求与当前采购决策的比较。然后便可根据未来每种需求水平的相应概率对每种决策记分。
确定供应链决策的优先级
需求预测常用于驱动供应链决策,例如下采购订单、触发工业场合中的生产批次。在得出与未来所有结果相关的所有概率后,即可构建所有采购决策的完整优先级表。 
实际上,对于每种采购决策,我们可以写出简单的粗略计算,“结果“公式:假设需求为 D 件,我们采购了 P 件,那么财务结果就是 X。用不着说,Lokad 自然会帮助您写出这种简洁公式,对于大部分企业而言,这可以归结为毛利润 – 库存成本 –缺货成本。因此,在得出该公式后,对于每种供应链决策(例如“采购 1 件产品 Z“,将根据未来每种可能的概率来权衡结果。这样我们就可以计算出每种可能的决策的“分数“。
在对每种决策记分后,即可对所有决策排名,并将利润最高的方案置于列表最上方。我们称这样的列表为**总采购优先级表**。在列表中,每种产品出现在多行。采购 1 件产品 Z 可能为排在首位的采购决策(也即最急迫的采购),但购买下一件产品 Z 可能排在第 20 位,中间存在多件要采购的其他产品。
总列表回答了一个非常简单的问题:如果公司有多余的一美元要花在存货上,那么最先要花到哪里?这一美元自然是要花到带给公司最高回报的产品上了。在购置这件产品后,又可以重复相同的问题。但这一次,在另外购置这件产品后,下一个要采购的最有利可图的产品很可能是别的产品,因为在库存中堆放多件相同产品会发生收益递减。
事实上,存货越多,存货周转越少,库存积压的概率就越高。这些问题当然都会反映在“结果“公式以及生成的列表优先级中。
胜过调整服务水平

确定出"最佳"服务水平(即所期望的不发生缺货的概率)是一件很难的事。这个问题非常复杂,因为服务水平与公司的财务业绩只存在间接的关系。事实上,对于某些产品,进一步提高服务水平可能花费代价太高,因此,如果资源容易获取,他们宁可分配给其他产品,这样相同的投资水平将不只提高 1% 而是 10% 的服务水平。
如果将分位数网格用作总采购优先级表,那么甚至不必关注服务水平,因为这些服务水平会自然而言地体现在优先级中。如果一种高利润产品的服务水平只需花费不大即可提高,这种产品自然会居于列表最上方。反之,如果一种产品销售非常不稳定,并且为了提高服务水平而做出所有努力的代价过高,那么只有在存货极少并且公司保证即便需求模式极其不稳定也不会沦为积压库存时,这种产品才会上升到列表的最上方。
优先级表也解决了资金限制的问题。不论贵公司的资金情况如何,优先级表都会为您提供易于处理的方案。如果资金非常有限,贵公司可以只购买位于列表最上方的产品,只维持亟需补货的产品的库存量。如果有闲置的多余资金,那么贵公司可以增加库存,将重点放到既能推动最大增长,同时也能掌控库存风险的项目上。
注入供应链限制
公司必须经常处理供应限制,例如 SKU 级别或订单级别的最小订货量。有时产品件数需要进行大批量收集(例如集装箱)。借助如上所述的总采购优先级表,此类限制可以很容易地整合到工作流程中。这样不仅可以提供优先级分明的采购建议,而且可以提出与订购限制相符的建议。
所要遵循的具体流程取决于企业的实际限制类型。我们不妨以集装箱运输为例。Lokad 可以计算每个供应商的累积量,只要采购明细是按列表顺序处理并且每个供应商是彼此独立发货的。根据这些累积量,可以很简单地完成列表项目往下延伸直至达到目标集装箱容量的过程。
同样,如果给定的 SKU 存在最小订货量限制,在这种情况下,也可以很容易地从列表中移除达到限制前存在的所有行,并在符合限制后将数量直接报告给第一行。通过强制至少采购 N 件,该 SKU 的竞争力将下降,即 SKU 在列表中的排名下降,这与实施最小订货量时库存风险增加的既定行为不谋而合。
具体地说,这种方法完全解决了长期以来困扰传统预测和分位数预测的难题,例如:建议的再订货量高于或低于订购限制时怎么办?如果需要移除某些项目,那么最先应补上哪些产品?如果要增加项目,哪些产品应增大采购量?对于这些问题,旧有的预测方法未能提供满意的答案。而如果使用采购优先级表,则按照列表顺序来就可以了。