Не прекращайте учебу с
LOKAD TV
/sample в вашей учетной записи Lokad. Сценарий, приведенный ниже, достаточно сложен. Он содержит некоторые структуры агрегации данных, доступные в Envision. Агрегация данных может происходить как вне ячеек, так и внутри них. Для понимания материалов, изложенных в данном разделе, рекомендуется сначала прочитать статью «Выполнение расчетов с помощью Envision».
read "/sample/Lokad_Items.tsv" as Items read "/sample/Lokad_Orders.tsv" as O read "/sample/Lokad_PurchaseOrders.tsv" as PO expect O.Quantity : number show label "Aggregating data" a1f1 tomato oend := max(O.Date) obegin := oend - 365 totalPurchased := sum(PO.NetAmount) totalSold := sum(O.NetAmount) when date >= obegin show table "Total purchased" a2c2 with totalPurchased unit:"$" show table "Sold over 1 year" d2f2 with totalSold unit:"$" VolumeSold = sum(O.NetAmount) UnitSold = median(O.Quantity) show table "Top sellers" a3f4 tomato with Name VolumeSold as "Sold" unit:"$" UnitSold as "Median" order by VolumeSold desc avgRet := avg(distinct(O.Date) by O.Client) avgQty := avg(sum(O.Quantity) by [O.Client, O.Date]) show table "Average client returns" a5c5 with round(avgRet) show table "Average backet quantity" d5f5 with avgQty O.Brand = Brand show table "Top Suppliers" a6f7 tomato with Supplier distinct(Category) as "Categories" sum(O.NetAmount) as "Sold" unit:"$" mode(O.Brand) if (O.Brand != "Fellowes") as "Most frequent brand sold" group by Supplier order by sum(O.NetAmount) descДля начала рекомендуем вам скопировать сценарий выше в свою учетную запись Lokad и выполнить его, чтобы получить соответствующую панель управления. Если все сделано правильно, должна появиться панель управления, показанная ниже.
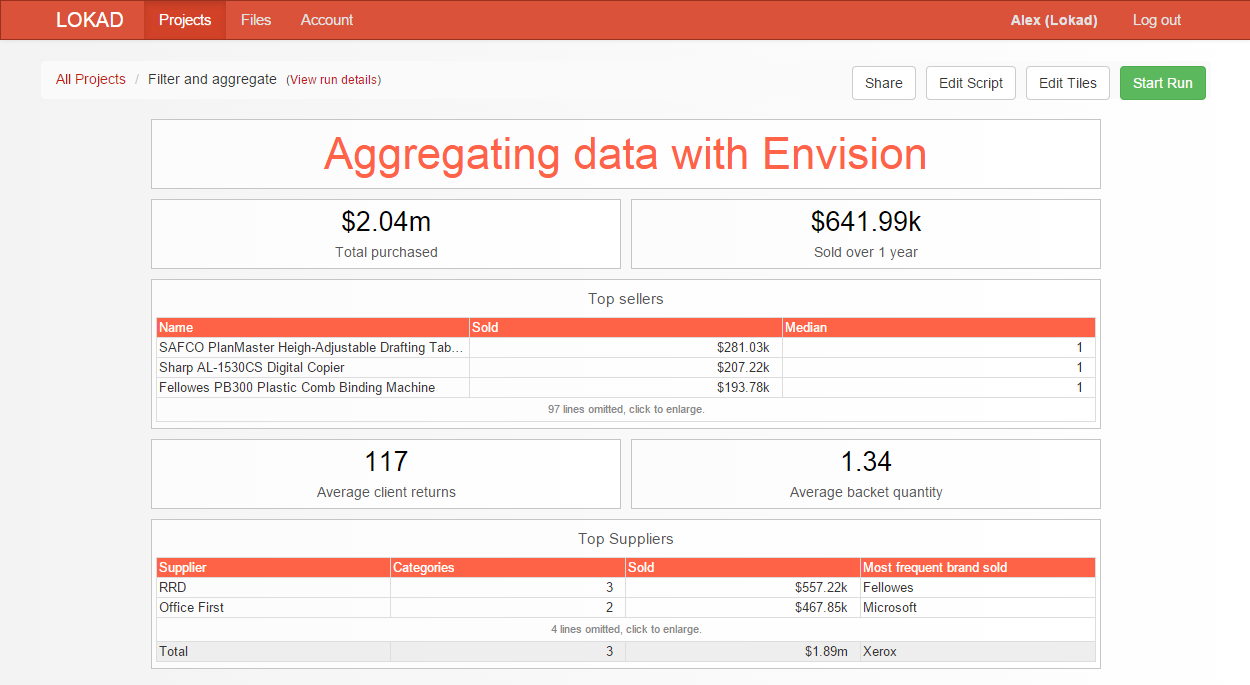
Items). По аналогии с Excel переменные Envision изначально похожи на столбцы в таблицах Excel: эти переменные являются векторами и содержат множество значений (по одному значению на наименование). Тем не менее некоторые переменные могут вести себя как отдельные ячейки Excel и содержать только одно значение. Это и есть скалярные переменные. Сценарий, приведенный выше, показывает, как можно рассчитать две скалярных переменных. Для удобства повторим соответствующие строки ниже.
totalPurchased := sum(PO.NetAmount) totalSold := sum(O.NetAmount) when date >= obegin show table "Total purchased" a2c2 with totalPurchased unit:"$" show table "Sold over 1 year" d2f2 with totalSold unit:"$"В этих строках кода можно выделить некоторые аспекты. Во-первых, две операции присваивания в строках 1 и 2 реализуются с помощью оператора скалярного присваивания
:=. Если оператор := используется вместо простого оператора присваивания =, значит, по итогам агрегации данных будет получено одно значение, не зависящее от наименований.
Во-вторых, переменные totalPurchased и tableSold начинаются с маленькой буквы. Несмотря на то что регистр не играет какой-либо роли в Envision, в данном случае такое написание не является случайным. Для удобства программирования рекомендуется записывать с маленькой буквы имена переменных, которые содержат скалярные значения. Имена таблиц и столбцов, наоборот, лучше начинать с заглавных букв. Благодаря такой записи кода сценарии будет проще читать и искать в них ошибки.
В-третьих, скалярная агрегация происходит по умолчанию в пределах оператора show table, если в таблице содержится только один столбец. Например, строки 1 и 3-4 могут быть представлены в виде одного оператора show table, как показано ниже.
show table "Total purchased" a2c2 with sum(PO.NetAmount) unit:"$"Подобно любым другим числовым переменным в Envision склярные числовые переменные также можно использовать для произвольных расчетов Например, после того как переменные
totalPurchased и totalSold будут заданы, в конце сценария Envision можно добавить следующие расчеты, даже если они не имеют большого значения с коммерческой точки зрения:
mySum := (totalSold - totalPurchased) / 2 show table "My Sum" with mySum
Date, и преобразовании ее в вектор, соответствующий данным в таблице Items.VolumeSold = sum(O.NetAmount) UnitSold = median(O.Quantity) show table "Top sellers" a3f4 tomato with Name VolumeSold as "Sold" unit:"$" UnitSold as "Median" order by VolumeSold descВ строках 1 и 2 агрегация выполняется примерно так же, как в случае со скалярной агрегацией, которую мы рассмотрели в предыдущем разделе. Однако операции присваивания выполняются с помощью знака равенства
=, а не оператора скалярного присваивания :=. Таким образом, VolumeSold и UnitSold — векторы, которые являются частью таблицы Items. Таким образом, эти переменные получаются очень похожими на столбцы в Excel, и они содержат по одному значению на наименование. sum и median — это специальные функции, которые в Envision называются агрегаторами. В Envision существует множество других агрегаторов, например avg, min, max, first, last и др. Для краткости мы не будем рассматривать все доступные в Envision агрегаторы в данном разделе, однако для получения более подробной информации можно ознакомиться с полным списком агрегаторов.VolumeSold и UnitSold, указаны как аргументы после ключевого слова with, и их значения отображаются в таблице. Наконец, в строке 7 оператор order by показывает, что значения в таблице должны располагаться в убывающем порядке VolumeSold.GROUP BY в SQL, возможно, захотят узнать, как Envision понимает, какую группировку нужно использовать при расчете sum в строке 1. По умолчанию Envision выполняет группировку с помощью столбцов, которые работают как «ключи» справа от операций присваивания. В случае с переменными, которые принадлежат таблице Items (имя которой не указано), в роли (первичного) ключа выступает столбец Id. Это объясняет, почему при использовании знака = производится агрегация по одному наименованию.byby, которое используется для открытого указания соответствующего способа группировки. Продемонстрируем, как работает ключевое слово by:
VolumeSold = sum(O.NetAmount) SameVolumeSold = sum(O.NetAmount) by Id // Same!Строка 2 присвоена второму вектору с именем
SameVolumeSold, однако значения этого вектора точно такие же, как у вектора VolumeSold в строке 1. На самом деле, параметр by Id используется в строке 1, только в ней он скрыт. Если используется параметр by, то эффект получается такой же, как если бы, во-первых, группы создавались в соответствии с типом группировки, и, во-вторых, агрегаторы рассчитывались отдельно для всех групп.
Параметр by позволяет создавать достаточно сложные схемы агрегации, как показано в первом сценарии на этой странице. Посмотрим еще раз на две строки кода, где агрегация выполняется с помощью параметра by.
avgRet := avg(distinct(O.Date) by O.Client) avgQty := avg(sum(O.Quantity) by [O.Client, O.Date])Агрегатор
distinct рассчитывает количество отдельных значений, присутствующих в каждой группе. В строке 1 строки таблицы O (Заказы) сначала группируются в соответствии со значениями таблицы Client, после чего рассчитывается число отдельных дат заказа для каждого клиента. Таким образом, данный тип агрегации можно понимать как расчет числа повторных обращений для каждого клиента. Затем данный результат повторно агрегируется в виде одиночного скалярного значения с помощью агрегатора avg, который содержит внутреннюю операцию агрегацииdistinct.avgQty можно рассматривать как количество единиц товара, приобретенных за каждую покупку. Расчеты начинаются с оператора sum() by, однако после параметра by мы получаем не одну, а две переменные, разделенные запятыми и перечисленные в скобках: [O.Client, O.Date]. Такую структуру можно понимать следующим образом: создание группы для каждой пары переменных Client и Date. С коммерческой точки зрения, мы обрабатываем все единицы товара, приобретенные в один день, как одну покупку, что вполне допустимо в большинстве случаев. Наконец, внешний вызов к агрегатору avg позволяет рассчитать окончательное среднее значение для всех агрегатов sum, рассчитанных для всех пар.by поддерживает произвольное число переменных, перечисленных следующим образом sum(foo) by [arg1, arg2, …, argN]. На практике случаи, когда необходимо выполнять группировку данных одновременно по более, чем 4 переменным, довольно редки. Кроме того, порядок аргументов не влияет на окончательные группы, используемые для расчета агрегатов.group byO.Brand = Brand show table "Top Suppliers" a6f7 tomato with Supplier distinct(Category) as "Categories" sum(O.NetAmount) as "Sold" unit:"$" mode(O.Brand) if (O.Brand != "Fellowes") as "Most frequent brand sold" group by Supplier order by sum(O.NetAmount) descОператор
show table находится в строках 2–8, а агрегация задана в строке 7 с помощью оператора group by, который имеет точно такое же значение, что и параметр by, который мы рассмотрели ранее. Возможно, вам не совсем понятно, почему здесь используется ключевое слово group by, а не by, если их значение одинаково. Параметр if в строке 6 является фильтром агрегатора, и он рассматривается в следующем разделе.by можно использовать в списке выражений после ключевого слова with для отдельной ячейки (такая ситуация на данной странице не показана) Таким образом, group by отличается от оператора by. Последний является частью выражения, содержащегося в ячейке, тогда как group by применяется ко всей ячейке в целом. Иными словами, оператор group by применяется ко всем выражениям, перечисленным после ключевого слова with, в отличие от оператора by, который имеет только локальный эффект.group by все выражения, перечисленные в ячейке после ключевого слова with должны иметь возможности для агрегации. Например, код в строке 1 ниже неприемлем, потому что Name не дает возможности для агрегации по параметру group by Supplier.
show table "WRONG!" with Name group by SupplierЕсли мы изменим сценарий и введем, например, агрегатор
distinct, то наш сценарий Envision будет работать.
show table "CORRECT!" with distinct(Name) group by SupplierЕдинственное исключение из этого правила — агрегация непосредственно целевых значений. В сценарии в начале данного раздела мы указали оператор
group by Supplier в строке 7. В строке 3 переменная Supplier указана без какого-либо агрегатора, однако сценарий работает именно потому, что группировка происходит в соответствии с переменной Supplier.order by существует в строке 8. Действительно, агрегация таблицы сначала происходит по поставщику, и только затем она сортируется по столбцу Id, если не указан другой тип сортировки. В результате Envision требуется рассчитать одно значение для каждой группы, чтобы отсортировать все эти группы. Это как раз то, что произошло с оператором group by sum(O.NetAmount).group by с помощью ячейки table, однако данный синтаксис можно использовать не только в ячейке table, но и в большинстве других ячеек. Например, можно расширить сценарий, приведенный в начале данной статьи, с помощью ячейки barchart, в которой агрегация происходит по параметру Brand:
show barchart "Sales by brand" with sum(O.NetAmount) group by BrandОператор
group by также поддерживает множественную группировку, то есть группировку по нескольким векторам или нескольким выражениям, с помощью синтаксиса идентичного оператору by, который мы рассматривали ранее.if. В сценарии ниже показано использование такого фильтра в строке 6:
O.Brand = Brand show table "Top Suppliers" a6f7 tomato with Supplier distinct(Category) as "Categories" sum(O.NetAmount) as "Sold" unit:"$" mode(O.Brand) if (O.Brand != "Fellowes") as "Most frequent brand sold" group by Supplier order by sum(O.NetAmount) desc
Fellowes открыто исключается из отчета с помощью фильтра if. Фильтры полезно использовать в операторах ячеек, потому что они дают возможность фильтровать каждый столбец по-отдельности. Напротив, использование фильтра where, расположенного вне оператора ячейки, приведет к фильтрованию всех выбранных строк таблицы O без учета столбцов.TwoAndMore = sum(O.1) if (O.Quantity >= 2)
