Оптимизация цепей поставок во многом зависит от умения предсказывать потребности рынка в будущем. Таким образом, прогнозирование спроса еще в начале XX века стало считаться ключевой составляющей процесса оптимизации цепей поставок. Однако классическое прогнозирование опиралось на ограниченные вычислительные ресурсы. Некоторые из первых методов прогнозирования даже подразумевали проведение расчетов вручную. Доступ к огромным вычислительным ресурсам кардинально изменил подходы к прогнозированию. С одной стороны, прогнозы стали точнее, а с другой —
они дают более актуальную информацию. Как ни странно, именно актуальность информации в прогнозе определяет эффективность цепей поставок. Современные прогнозы называются
вероятностными. Благодаря сочетанию вероятностного подхода и современных инструментов, таких как машинное самообучение (как алгоритмов, так и ПО), количественная оптимизация цепей поставок позволяет решать более широкий набор задач, нежели устаревшие методики, опирающиеся на классические прогнозы.
Классические прогнозы и их ограничения
Под "классическими" прогнозами мы понимаем прогнозы
среднестатистические, периодические и равномерно распределенные по временным рядам. Прогнозы данного типа и по сей день широко распространены в сфере планирования цепей поставок и спроса. Сегодня очевидно, что они представляют ограниченный интерес для оптимизации цепей поставок, однако исторически они привели к созданию многих методик работы с цепями поставок. Проще говоря, классические прогнозы являются основой множества методик управления цепями поставок. Как следствие, такие методики страдают от тех же ограничений, что и сами классические прогнозы.
Рассмотрим особенности классического подхода к прогнозированию:
- Среднестатистические прогнозы : Прогнозы выдают среднестатистическое значение уровня спроса в будущем, то есть, если прогноз хорошо сбалансирован, то 50% спроса в будущем будут превышать спрогнозированное значение, а остальные 50% будут ниже ожидаемого спроса. Математически доказывается, что прогнозирование среднестатистического значения эквивалентно ошибочной минимизации по методу наименьших квадратов.
- Периодические прогнозы : Будущий спрос разбивается на периоды: дни, недели, месяцы или года. Прогноз принимает форму действительнозначного вектора. Размер такого вектора обычно называют горизонтом. Например, при прогнозировании на 10 недель периодом является неделя, а горизонтом — 10.
- Равномерно распределенные прогнозы : Считается, что периоды обладают одинаковыми свойствами, в частности, они имеют одну и ту же длительность. Такое предположение допустимо для дней и недель, однако с месяцами и годами ситуация сложнее. Несмотря на приближение, численный процесс периодов не позволяет различать их и подразумевает однородность.
- Временные ряды : Предполагается, что фактические данные имеют тот же формат, что и создаваемый прогноз. В частности, фактические данные представляются в виде действительнозначного вектора, связанного с тем же периодом, что и вектор прогнозирования. Длина входящего вектора ограничена количеством доступных фактических данных.
Иногда среднестатистическая оценка заменяется на
усредненную . В таком случае значения сбалансированного прогноза с 50% вероятностью будут выше или ниже уровня спроса в будущем, независимо от массы спроса. Оптимизация оценки для получения лучшего усредненного значения является эквивалентом минимизации средней абсолютной ошибки — для среднестатистических прогнозов это была ошибка по методу наименьших квадратов. В рамках настоящей дискуссии неважно, идет ли речь о среднестатистических или усредненных прогнозах, о средней абсолютной ошибке в процентах (MAPE) или о взвешенной MAPE. Таким образом, для простоты мы называем все подобные прогнозы «классическими», помещая все варианты с незначительными различиями в одну категорию.
Прогнозы подобных типов настолько прижились в цепях поставок, что для того, чтобы качественно оценить их эффективность, потребуются значительные усилия. Многие ведущие системы ПО "основаны" на классических прогнозах, что отражается даже в их архитектуре: например, таблицы в их базах данных содержат по 52 столбца, каждый из которых соответствует определенной неделе в году. Именно поэтому такие системы просто не могут реализовать некоторые типы оптимизации цепей поставок.
Неопределенность — основная проблема
Уровень будущего спроса не определен, и ничего с этим не поделать — большинство событий, которые так или иначе влияют на свободный рынок, просто невозможно смоделировать. Ни одна компания не может предсказать, когда конкурент снизит цены, чтобы отвоевать клиентов. Ни одна компания не может предвидеть крупную аварию в каком-нибудь порту Китая, из-за которой ключевой поставщик будет доставлять товары с опозданием. Ни одна компания не может сказать, окажется ли новая технология, разрабатываемая своими силами, эффективнее той, что используется в данный момент.
И все же, хотя неопределенность хода развития рынка кажется очевидной, если работать с историческим данными, классические прогнозы практически полностью ее игнорируют, вместо того чтобы учесть должным образом. При классическом прогнозировании нет никаких сомнений относительно будущего. На практике точность прогнозов можно оценивать с помощью таких методов, как ретроспективное тестирование, однако это внешние процессы, которые практически никак не связаны с прогнозированием.
Из-за игнорирования неопределенности многие ситуации просто могут быть не отражены в прогнозах. Например, оптовый поставщик обслуживает пару крупных розничных сетей. Какой-нибудь отдельно взятый товар может пользоваться стабильным спросом, так как его заказывают в примерно одинаковом количестве каждую неделю. Однако если углубиться в структуру спроса, станет ясно, что заказы поступают лишь от одной сети. Это означает, что если эта сеть откажется от данного товара, спрос упадет до нуля, что приведет к скоплению неликвидов у оптовика. Таким образом, даже если ожидается достаточно высокий среднестатистический спрос на товар, существует реальный риск полного падения спроса. Этот риск нельзя смоделировать просто занизив среднестатистический спрос. Классические прогнозы не могут смоделировать такие полярные ситуации одновременно, когда, с одной стороны, требуется
больше товара, а с другой —
продажи останавливаются.
Известные ошибки в истории спроса
Использование временных рядов при прогнозировании спроса предполагает, что имеющиеся данные о спросе в прошлом отражают его надлежащим образом. На практике такое предположение редко соответствует истине, потому что изменения спроса на рынке наблюдаются лишь косвенно. Эта небольшая деталь крайне важна: история клиентских заказов — это лишь примерное отражение спроса на рынке, так как фактический спрос, в какой-то степени, непознаваем. Например, когда компания сталкивается со случаями дефицита товара, клиенты начинают искать нужный товар у других поставщиков. Товары, полученные по альтернативным каналам для сглаживания последствий дефицита, не включаются в историю продаж, что приводит к появлению ошибок в данных.
Такие ошибки повсеместны. Даже когда все запросы клиентов учитываются, независимо от того, был ли их заказ выполнен вовремя или нет, ошибки все равно остаются. Предположим, региональный склад обслуживает несколько розничных магазинов. Каждый магазин ежедневно отправляет на склад заказ на пополнение запасов. Заказы не учитывают доступность товара на складе: за надлежащее распределение товаров между магазинами отвечает склад, и он работает исходя из того, что есть в наличии. Таким образом, если заказ на пополнение не может быть выполнен в первый день, он остается на второй день. Вполне возможно, что заказ будет расти, а проблемы с дефицитом товаров не будут решены, что создает проблемы в работе склада. Однако данный процесс приводит к возникновению еще одной ошибки : в случае дефицита товара магазины заказывают гораздо больше, чем обычно, потому что они продолжают заказывать один и тот же товар, пока он не будет доставлен. Таким образом, несмотря на то, что все запросы фиксируются, общий объем заказанных товаров не отражает спрос надлежащим образом. На практике ситуация осложняется последствиями дефицита товара на складе, который приводит к нехватке товаров в магазинах. Случаи дефицита товаров в магазине не фиксируются клиентами, которые их посещают.
Если принять во внимание, какие инструменты статистического анализа доступны сегодня, становится ясно, что проблема не столько в самом существовании ошибок, сколько в неадекватной обработке ошибок классическими системами прогнозирования. Прогнозирование по временным рядам не простое, но примитивное. Входящие данные в формате действительнозначного вектора, связанного с прошедшими периодами, не отражают доступную информацию об ошибках. Как следствие, для устранения последствий данной проблемы при использовании классических прогнозов требуется предварительная подготовка данных , во время которой система прогнозирования сама "исправляет недочеты" в те периоды, когда данные о спросе неверны, то есть происходит замена нулевого спроса , полученного вследствие дефицита товара, на значения, спрогнозированные системой для выбранных дат. Таким образом, компания строит прогнозы на прогнозах, делая их вдвойне неэффективными. Во-первых, создание прогнозов на основе других прогнозов приводит к значительному снижению точности прогнозирования . Во-вторых, фаза подготовки данных , которая и так является самым сложным этапом количественного моделирования, становится еще сложнее .
Спрос — не единственная цель прогнозирования
Прогнозирование с помощью временных рядов так долго доминировало в сфере управления цепями поставок, что оно часто становилось причиной проблемы
золотого молотка : если у вас есть молоток, то все, что попадется под руку — гвоздь. Уровень будущего спроса является лишь одним из многих параметров, которые необходимо прогнозировать, а временные ряды — лишь одна из многих методик, которые можно использовать при прогнозировании.
Огромную важность имеет время выполнения заказов. Уровень запасов в компании можно считать адекватным только в том случае, если их хватит только на то, чтобы удовлетворить спрос до прихода новой партии. Увеличение запасов не является обязательным благодаря своевременному пополнению. Однако время выполнения заказов само по себе является сложным параметром. Предположим, что время выполнения заказов одним поставщиком составляет 7 дней — так прописано в договоре, однако это время и неэффективно, и опасно. Неэффективно, потому что поставщики обычно указывают время выполнения заказа, которое им подойдет даже в неблагоприятных обстоятельствах. На практике же поставщики часто выполняют свои обязательства гораздо быстрее. Опасность же заключается в том, что если поставщик постоянно срывает договорные сроки поставки товаров, все остальные элементы цепи поставок будут "делать вид", что все идет, как надо, и перестанут пытаться сгладить последствия задержек указанного поставщика.
Таким образом, время выполнения заказов необходимо прогнозировать. Как и спрос, время выполнения заказов можно прогнозировать по фактическим данным, и, как и спрос, время выполнения заказа зависит от таких статистических факторов , как сезонность , которые используются для оптимизации прогнозов. Например, время выполнения заказов поставщиками из Китая каждый год увеличивается на 3–4 недели во время празднования Китайского Нового года — это следствие того, что в это время фабрики не работают.
Существуют и другие элементы цепей поставок, помимо времени выполнения заказов и спроса, которые необходимо так или иначе прогнозировать. В частности, можно перечислить следующее:
- Возвраты — в модных интернет-магазинах клиент может вернуть большую часть заказанных товаров. Например, в Германии клиенты часто покупают несколько пар туфель, а затем возвращают те размеры, которые не подошли. Есть множество случаев, когда более 30% изначально заказанных товаров возвращается продавцу. Таким образом, необходимо прогнозировать объемы возвратов.
- Непригодные к использованию товары — в розничной торговле продуктами питания очень часто значительная часть товаров, прибывающих на склад, не проходит контроль качества, так как они очень хрупкие или имеют небольшой срок годности. Например, половина коробок с клубникой по прибытии на склад могут быть сразу же утилизированы, потому что поврежденный товар невозможно будет продать. При передаче заказов на закупку поставщикам крайне важно учитывать, сколько товара, предположительно, не пройдет контроль качества. Именно в таких случаях важно прогнозировать, какая доля товара окажется непригодной к использованию.
- Неточности в электронных записях — в розничной торговле точность описания запасов на уровне магазина часто достаточно низкая. Покупатели могут повредить, украсть или просто переставить товар на полках, из-за чего появляются расхождения между запасами, зафиксированными в электронной форме, и реально доступными в магазине. Расхождения между реальными запасами и электронными записями можно предсказать за счет истории сопоставления запасов, которая создается при ревизиях.
В различных отраслях необходимо прогнозировать или проводить статистическую оценку различных аспектов. Крайне важно определить такие аспекты, потому что в противном случае цепи поставок будут работать по правилам, которые могут оказаться недопустимыми — именно поэтому необходимо иметь возможность протестировать и оптимизировать эти правила.
Универсальное прогнозирование и машинное самообучение
За последние десятилетия сфера машинного самообучения, которая находится на стыке информатики и статистики , проделала огромный путь. Сегодня машинное самообучение продолжает стремительно развиваться благодаря недавним прорывам в области глубинного обучения , и все это еще далеко не предел возможностей данной отрасли. В машинном самообучении для извлечения и обработки информации из наборов данных разных видов задействуются большие объемы ПО и знания о количественной оптимизации. В данной статье не рассматривается машинное самообучение как таковое, однако важно понимать его значение для количественной оптимизации цепей поставок.
Машинное самообучению представляет собой метод систематической обработки практически любого достаточно крупного корпуса данных. Увеличение объема данных не осложняет задачу, а напротив, делает ее решение проще. Это крайне важное утверждение, и оно не имеет смысла с точки зрения классического прогнозирования. Когда сотрудники, занимающиеся цепями поставок, сталкиваются с серьезным затруднением, они часто стремятся сузить проблему, чтобы ее было проще решить. При машинном самообучении меньший объем данных практически всегда подразумевает увеличение нагрузки на аналитика , который должен настроить алгоритмы для эффективной работы, несмотря на ограничения наборов данных. Все алгоритмы машинного самообучения лучше работают с большими объемами данных. Есть мнение, что большинство самых крупных успехов в сфере машинного самообучения, в том числе системы распознавания речи или машинного перевода, были наконец достигнуты благодаря обработке больших объемов данных по сравнению с первыми попытками.
Как только собрано достаточное количество актуальных данных, системы машинного самообучения предлагают множество методов создания самых разных прогнозов, участие аналитика в которых сводится к минимуму или вовсе не требуется. Разработчики ПО и ученые на протяжении многих лет стремились избавить потоки данных от ручной корректировки за счет алгоритмов машинного самообучения. Сегодня самым современным системам машинного самообучения требуется крайне незначительная ручная корректировка . В целом, те, кто занимается машинным самообучением, все с большим скептицизмом относятся к подходам, которые требуют хоть сколько-нибудь значительной ручной корректировки. Это обусловлено успехами в сфере машинного самообучения и в особенности в глубинном обучении. Обратите внимание: алгоритмам машинного самообучения корректировка практически не нужна, но для подготовки данных потребуется приложить заметные усилия. Однако эти усилия необходимы, независимо от того, какой из алгоритмов машинного самообучения будет использоваться в итоге.
Таким образом, мы призываем скептически относиться к прогностическим статистическим системам, в которых даже просто есть возможность ручной корректировки прогнозов. Наличие подобной функции показывает, что система спроектирована без учета важнейших наработок машинного самообучения. На практике это означает, что система наверняка будет страдать от тех же проблем, что и устаревшие компьютерные системы на основе правил — несколько десятилетий назад стало ясно, что обслуживать их просто невозможно.
Ключевым преимуществом прогнозирования с помощью алгоритмов машинного обучения в цепях поставок является то, что для создания прогнозов различных типов потребуется не больше усилий, чем для создания традиционных прогнозов спроса. Почти все усилия концентрируются на подготовке данных , а затем на оптимизации структуры компании для получения максимальной выгоды от прогнозов.
Машинное самообучение используется при количественной оптимизации цепей поставок для создания прогнозов, когда это необходимо и экономически оправдано. Вместо того чтобы уделять внимание только прогнозированию спроса, специалисты по количественной оптимизации стремятся работать со всеми неопределенными параметрами цепей поставок : временем выполнения заказов, дефектной продукцией , изменениями рынка и т. д. При количественной оптимизации используются алгоритмы машинного самообучения, которые позволяют создавать самые разные виды прогнозов, подходящие для разных цепей поставок. Такой подход значительно отличается от классического, когда еженедельные или ежемесячные прогнозы спроса используются для решения сторонних задач.
Вероятностное прогнозирование и борьба с неопределенностью
Если неопределенность невозможно снизить, как это обычно и бывает при прогнозировании в сложных цепях поставок, желательно рассчитать не только наиболее вероятный вариант развития событий, но и альтернативы. Вероятностное прогнозирование является самым популярным способом статистической формализации данной идеи. При нем создается статистическая оценка всех возможных вариантов развития событий. Такая обобщенная оценка принимает форму распределения вероятностей всех возможных вариантов развития событий. Вероятностное прогнозирование может считаться крайним случаем использования вопроса «а что, если?» , при котором рассматриваются все сценарии.
Несмотря на то, что вероятностное прогнозирование может показаться достаточно сложным в теории подходом, на самом деле он достаточно простой и эффективный. Возьмем, к примеру, вероятностный прогноз спроса. Вместо того чтобы рассчитывать единственное значение, как при прогнозировании среднестатистического спроса, мы создадим список вероятностей того, что уровень спроса будет равен 0, 1, 2, 3 единицам товара и т. д. Для визуализации всех вероятностей чаще всего используется гистограмма , где каждый сегмент отражает вероятность конкретного уровня спроса. Все вместе эти вероятности составляют
распределение вероятностей .
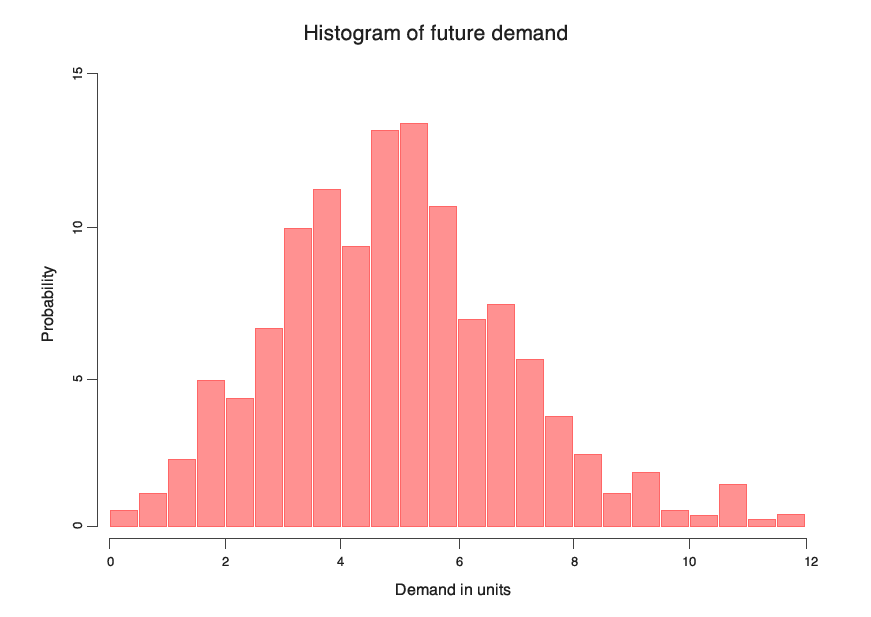
Прогнозирование распределения вероятностей, то есть вероятностное прогнозирование, представляет собой обобщение традиционных среднестатистических и усредненных прогнозов. Данный подход может показаться сложным, однако он хорошо известен и часто используется во многих сферах. Например, почти во всех последних достижениях в области глубинного обучения, благодаря которым автомобили с автопилотом становятся реальностью, используется вероятностный подход (точнее будет сказать байесов подход, однако здесь о нем речь идти не будет). Вероятностное прогнозирование широко известно в мире: на эту тему опубликованы тысячи научных работ и создано множество компьютерных программ.
Именно вероятностное прогнозирование желательно использовать при количественной оптимизации цепей поставок. В цепях поставок убытки связаны не со среднестатистическими, а с крайними ситуациями : чрезмерно высокий спрос приводит к дефициту товара, чрезмерно низкий — к скоплению неликвидов. Вероятностное прогнозирование решает данную проблему напрямую — рассчитывается вероятность возникновения всех возможных ситуаций, включая проблемные. Вероятностное прогнозирование — краеугольный камень структурного управления рисками в цепях поставок. Такие прогнозы позволяют экономически эффективно решать возникающие проблемы. В цепях поставок главное — найти компромисс : для исключения случаев дефицита товара нужен бесконечный его запас, однако такое решение, безусловно, не оправдано экономически. Без вероятностных прогнозов сопоставление расходов на содержание запасов с убытками из-за дефицита товара превращается в пустые догадки.
Небольшим недостатком вероятностных прогнозов является большая потребность в вычислительных ресурсах по сравнению с простыми методами прогнозирования. В частности, даже если использовать модель классического прогнозирования (например, экспоненциальное сглаживание), которая может быть заложена в Microsoft Excel, для реализации большинства, если не всех моделей вероятностного прогнозирования требуется больше вычислительных ресурсов, чем можно получить из табличных файлов. С появлением облачных технологий вычислительные ресурсы значительно подешевели: на данный момент некоторые платформы предлагают 1000 часов вычислений на высокотехнологичном одноядерном сервере с частотой 2 ГГц меньше, чем за 10 долларов США. На практике для эффективного использования таких недорогих вычислительных ресурсов требуется специальное ПО для вероятностного прогнозирования, изначально создававшееся для облачных вычислений.
Большинство алгоритмов вероятностного прогнозирования были получены благодаря открытиям, сделанным в обширной сфере машинного самообучения. Для использования технологий машинного обучения в оптимизации цепей поставок не нужно быть экспертом в данной области — вы ведь пользуетесь фильтром для спама в электронной почте, который также работает на алгоритмах машинного самообучения. Как уже говорилось выше, двумя ключевыми аспектами машинного самообучения являются установка на автоматизацию и (почти полное) устранение ручной корректировки статистических моделей.
