La capacité d'une entreprise à anticiper les besoins du marché ciblé est décisive en matière d'optimisation logistique. Ainsi, dès le début du XXe siècle, la prévision de la demande apparaît comme la pierre angulaire de toute démarche de cet ordre. L'approche classique des prévisions était cependant initialement limitée par les capacités de calcul disponibles et certaines méthodes reposaient même sur des calculs manuels. L'accès à des ressources informatiques de plus en plus importantes a profondément modifié la façon d'aborder les prévisions, qui sont désormais plus précises et plus significatives. Même si cela peut-être paraître contre-intuitif, c'est ce dernier aspect qui est à l'origine des améliorations les plus sensibles en matière de performance logistique. Ce type de prévisions perfectionnées est aussi appelé « prévisions probabilistes ». En combinant cette approche probabiliste aux outils modernes offerts par le deep learning (algorithmes et équivalents logiciels), la Supply Chain Quantiative est en mesure de traiter une plus large gamme de problèmes que les méthodologies logistiques axées à l'origine sur les prévisions classiques.
Les prévisions classiques et leurs limites
Nous désignons par « prévisions classiques » les « prévisions moyennes, périodiques réalisées à intervalles réguliers sous forme de séries chronologiques ». Ce type spécifique de prévisions reste largement utilisé dans le monde de la logistique et de la planification de la demande. Même si son intérêt pratique pour l’optimisation logistique est limité de nos jours, son importance historique a façonné de nombreuses méthodologies, qui reposent plus spécifiquement sur les prévisions classiques et héritent par conséquent de leurs limites.
Détaillons cette approche classique des prévisions :
- Moyenne : la prévision vise à estimer la « moyenne » de la demande future ; c’est-à-dire que dans une prévision équilibrée 50 % de la masse de la demande future est au-dessus de la valeur prévue et 50 % en dessous. Il est possible de prouver mathématiquement que cette estimation de la moyenne est équivalente à la minimisation de l’erreur par moindres carrés.
- Périodique : la demande future est divisée en « périodes » — jours, semaines, mois ou années. La prévision prend la forme d’un vecteur dont les valeurs sont des réels. La taille de ce vecteur est généralement appelée « horizon ». Par exemple, pour des prévisions 10 semaines à l'avance, la période est la semaine et l’horizon est 10.
- Réalisées à intervalles réguliers : les périodes sont considérées comme uniformes et identiques en durée. Cette hypothèse est valide pour les périodes qui correspondent aux jours et aux semaines, mais l'est pas réellement pour les mois et les années. Malgré cette approximation, le traitement numérique des périodes ne les différencie pas et les considère comme totalement uniformes.
- Série chronologique : le format de l’historique des données est considéré comme homogène avec la prévision produite. L’historique des données est modélisé par un vecteur de réels relatif à la même période que celle sélectionnée pour la prévision. La longueur du vecteur d’entrée est limitée par la profondeur de l’historique.
Parfois, l’estimateur moyen est remplacé par la « médiane ». Dans le cas de cette dernière, une prévision équilibrée a 50 % de chances d’être au-dessus ou en dessous de la demande future, quelle que soit la masse de la demande. L’optimisation d’un estimateur en vue d’obtenir la meilleure médiane est équivalente à la minimisation de l’erreur absolue moyenne (erreur par moindres carrés pour la moyenne). Pour le présent article, il n’est pas utile de différencier les prévisions moyennes et médianes, ni un indicateur qui repose sur le pourcentage d’erreur absolue moyenne et un indicateur qui repose sur les versions pondérées de cette dernière. Ainsi, pour plus de simplicité, toutes ces prévisions sont appelées « classiques », terme qui rassemble toutes les variantes mineures.
Ces types de prévisions sont tellement ancrés dans le monde de la logistique, qu’il est très difficile de prendre du recul et d’en envisager toutes les implications. Pour l’anecdote, ces prévisions classiques sont codées en dur dans plusieurs solutions logicielles bien connues, qui contiennent donc des tables de base de données à 52 colonnes, une pour chaque semaine de l’année. À cause de ce procédé, l'architecture même de ces solutions logicielles ignore tout un pan de l’optimisation logistique.
L’incertitude, problème numéro 1 et pourtant tabou
La demande future est associée à un degré important et irréductible d’incertitude : la plupart des événements qui influencent les marchés capitalistes ne peuvent tout simplement par être modélisés de façon déterministe. Votre entreprise ne peut prévoir quand son concurrent va baisser ses prix et soudainement reconquérir des parts de marché. Elle ne peut pas anticiper l’accident industriel qui a lieu dans un port en Chine et empêche son fournisseur principal de la livrer à temps. Elle ne peut même pas pronostiquer si la nouvelle technologie développée en interne s’avérera meilleure que la technologie actuelle.
Pourtant, même si cette incertitude irréductible sur le futur du marché semble évidente avec un peu de recul, les prévisions classiques ignorent presque entièrement le problème, au lieu de le résoudre. En effet, du point de vue des prévisions classiques, il n’y a aucune incertitude. En pratique, l’exactitude des prévisions peut être estimée via des techniques comme la backtesting, mais il s’agit d’un processus externe largement décorrélé du processus de prévision.
Comme l’incertitude est ignorée, de nombreuses situations ne peuvent simplement pas être exprimées dans les prévisions. Prenons l’exemple d’un grossiste qui travaille avec quelques grands réseaux de vente au détail. Un produit donné peut être associé à une demande très stable, car la même quantité est commandée chaque semaine. Cependant, les commandes viennent toutes d’un seul réseau de vente au détail. Par conséquent, si le grossiste venait à être rayé de la liste des fournisseurs de ce produit pour ce réseau, la demande deviendra nulle et un stock mort apparaîtra immédiatement de son côté. Par conséquent, même si la demande moyenne prévue est forte, le risque de disparition de celle-ci est réel. Ce dernier ne peut être modélisé en abaissant la demande moyenne. Les prévisions classiques ne sont pas adaptées pour exprimer une telle situation bimodale : un mode « toujours plus » et un mode « interruption ».
Biais connus de l’historique de la demande
La prévision de la demande envisagée chronologiquement fait l’hypothèse que l’historique de la demande reflète correctement cette dernière. En pratique, cependant, cette hypothèse se vérifie rarement, car la demande est observée indirectement. Cette question est subtile et pourtant essentielle : l’historique des commandes client n’est qu’une approximation de la demande, celle-ci étant, dans une certaine mesure, impossible à connaître exactement. Par exemple, lors d’une rupture de stock, les clients se fournissent ailleurs. Dans ce cas, les quantités achetées via des canaux alternatifs ne se retrouvent pas dans l’historique des ventes, ce qui génère des biais.
Ces derniers sont très répandus. Même si toutes les demandes des clients étaient consignées, que ces demandes aient été satisfaites ou non, des biais persisteraient. Prenons par exemple un entrepôt régional qui fournit un ensemble de magasins de vente au détail. Chaque magasin envoie quotidiennement une commande de réapprovisionnement à l’entrepôt. Les magasins ne prennent pas en compte les stocks disponibles dans ce dernier, qui se doit de traiter les commandes équitablement en fonction des produits disponibles. Si la commande d’un magasin ne peut être satisfaite le jour 1, une commande identique est déplacée au jour 2. Celle-ci est alors potentiellement un peu plus importante, tandis que la rupture de stock n’est pas résolue. Ce processus crée un autre artefact : lors d’une rupture de stock, les magasins commandent plus que d’habitude, car les quantités commandées et non livrées s’ajoutent. Ainsi, même si tous les mouvements sont enregistrés, les quantités commandées ne peuvent être considérées comme des reflets exacts de la demande. En pratique, les conséquences d’une rupture de stock compliquent encore plus la situation, car les magasins se retrouvent eux aussi en rupture de stock. La demande des clients qui viennent en magasin et ne trouvent pas les produits voulus n’est alors pas enregistrée.
Avec les outils statistiques disponibles aujourd’hui, le problème ne vient pas tant des biais, mais du fait que les prévisions classiques ne sont pas en mesure de les prendre en compte. En réalité, la perspective chronologique sur les prévisions de la demande n’est pas simple, elle est simpliste. De plus, les données d’entrée modélisées comme un vecteur de réels associé aux périodes passées ne peut refléter les informations possiblement disponibles sur ces biais. Pour résoudre le problème, les prévisions classiques passent généralement des étapes préalables, qui utilisent récursivement le processus de prévision lui-même pour « combler les écarts » apparus pendant les périodes de demande biaisée, en remplaçant, par exemple, les zéros générés par une rupture de stock par les valeurs de la demande prévue à l'origine pour la période concernée. Mais, ce faisant, l’entreprise fait des prévisions qui reposent sur des prévisions, ce qui s’avère doublement inefficace. Tout d’abord, ces prévisions à partir de prévisions sont souvent très erronées. De plus, elles compliquent les étapes de préparation des données, qui est déjà la partie la plus compliquée de la modélisation quantitative.
Les prévisions représentent plus que la future demande
Les prévisions chronologiques ont tellement dominé la logistique qu’est souvent apparu le problème du marteau de Maslow : « si le seul outil que vous avez est un marteau, vous tendez à voir tout problème comme un clou ». La demande future n’est qu’un des nombreux éléments qui doivent être prévus et les prévisions chronologiques ne représentent pas la seule approche possible.
Les délais d'approvisionnement sont primordiaux, l’inventaire d’une entreprise n’étant utile que si les quantités en stock suffisent à répondre à la demande sur la durée du délai d'approvisionnement. Il est inutile de stocker plus de marchandises, car celles-ci sont réapprovisionnées au bout de ce délai. Cependant, les délais d'approvisionnement ont un fonctionnement compliqué. Le délai d'approvisionnement indiqué dans le contrat d’un fournisseur n’est pas forcément correct et l’utilisation de cette valeur dans les prévisions est à la fois inefficace et dangereuse. Inefficace, car les fournisseurs ont tendance à négocier des délais d'approvisionnement qu’ils seront capables de tenir en toutes circonstances, même dans le pire scénario. En pratique, les délais d'approvisionnement constatés sont largement inférieurs aux valeurs contractuelles. Dangereuse, car si un fournisseur ne respecte pas le délai contractuel de façon régulière, le reste de la supply chain continue de fonctionner avec l’hypothèse initiale, comme si de rien n’était, et aucune mesure n’est prise pour limiter les conséquences de ces retards.
Par conséquent, les délais d'approvisionnement doivent eux aussi être prévus. Tout comme la demande, les délais d'approvisionnement peuvent être prévus à partir de l’historique des données et sont caractérisés par des particularités statistiques, telles que la saisonnalité, utilisables pour affiner les prévisions. Par exemple, les délais d'approvisionnement de fabricants chinois augmentent potentiellement de 3 à 4 semaines chaque année autour du Nouvel An chinois, car les usines ferment à cette période.
De plus, au-delà des délais d'approvisionnement et de la demande, de nombreux autres éléments logistiques requièrent des prévisions. Par exemple :
- Retours client: dans le secteur de la mode en ligne, les clients sont susceptibles de renvoyer une grande partie de leurs commandes. Par exemple, en Allemagne, les clients commandent souvent plusieurs paires du même modèle de chaussures et renvoient les pointures qui ne conviennent pas. Les quantités renvoyées dépassent souvent 30 % de la commande initiale. Ainsi, les quantités renvoyées doivent également faire l’objet de prévisions.
- Marchandises reçues inutilisables’ : dans la distribution de produits alimentaires, la marchandise est fragile et périssable. Il n’est pas rare qu’une partie non négligeable des marchandises reçues par les entrepôts ne passe pas les contrôles qualité. Par exemple, la moitié des barquettes de fraises reçues par un entrepôt peut être jetée immédiatement, car considérée comme invendable. Lors du passage des commandes aux fournisseurs, il est important de prendre en compte la part de marchandise qui ne passera pas les contrôles qualité. Des prévisions de la quantité de marchandise rejetée sont donc également utiles.
- Erreurs de données’ : dans la distribution, les données de stock au niveau de chaque magasin sont souvent imprécises. En effet, les clients peuvent abîmer, voler ou simplement déplacer des produits dans le magasin, ce qui crée des incohérences entre les données des niveaux de stock et le stock réellement disponible en magasin. Les incohérences entre le stock réel et sa version numérique sont prévisibles à partir de l’historique des corrections apportées suite aux inventaires.
En fonction du secteur, plusieurs autres problèmes nécessitent des prévisions ou une estimation statistique prédictive. Il est indispensable d’identifier ces problèmes, sinon la supply chain continue de fonctionner sur des bases qui ne sont pas forcément pertinentes, sans envisager de les remettre en question ou de les améliorer.
Prévisions généralisées grâce au deep learning
Au cours des dernières décennies, le domaine du deep learning, qui peut être considéré comme la croisée des chemins entre informatique et statistiques, a énormément progressé. Loin de stagner, il progresse encore, plus vite que jamais, grâce notamment aux dernières avancées du deep learning. Le deep learning rassemble un grand nombre d’implémentations logicielles et d’informations quantitatives pour extraire et exploiter les connaissances présentes dans divers types d’ensembles de données. Si le deep learning n'est lui-même pas le sujet de la présente rubrique, ses implications sont essentielles en matière de Supply Chain Quantiative.
Le deep learning offre une méthode de gestion systématique de presque tout ensemble de données de taille suffisamment importante. L’augmentation du volume de données ne complique pas le problème, au contraire elle le simplifie. Cette indication, contre-intuitive par rapport à l’approche logistique classique, est très importante. En effet, face à une difficulté d'ordre logistique, la plupart des professionnels ont tendance à essayer d’en réduire le périmètre afin d’en faciliter l’appréhension. Du point de vue du deep learning pourtant, un volume de données réduit donne plus de travail aux experts, qui doivent faire fonctionner l’algorithme malgré les limites de l’ensemble de données. Tous les algorithmes de deep learning, sans exception, sont conçus pour fonctionner de façon optimale avec de gros volumes de données. Ainsi, la plupart des succès du deep learning, notamment la reconnaissance vocale ou la traduction automatique, ont sans doute été réalisés grâce à la possibilité de traiter des ensembles de données bien plus volumineux que jusqu’à présent.
Une fois qu’un volume de données suffisant a été collecté, le deep learning offre plusieurs méthodes qui ne nécessitent presque pas de réglages et réalisent plusieurs types de prévisions. La suppression des réglages manuels sur les données traitées par deep learning est l’aboutissement de dizaines d’années d’efforts conjoints de la part des professionnels et universitaires du domaine. Désormais, la plupart des méthodes modernes de deep learning ne requièrent presque pas de réglages manuels. Les spécialistes sont d’ailleurs très sceptiques face à la durabilité des approches qui nécessitent plus que des ajustements superficiels. Cette orientation est à l’origine de nombreux succès du deep learning. Elle est particulièrement influente dans le domaine du deep learning. Attention : les algorithmes de deep learning ne nécessitent pas ou peu de réglages, mais la préparation des données, elle, exige beaucoup d’efforts — indépendants du type d’algorithme de deep learning utilisé ultérieurement.
Nous conseillons donc aux professionnels de la logistique de se méfier de toute solution statistique prédictive qui offre la possibilité d’ajuster les prévisions manuellement. Une telle fonctionnalité indique que la solution n’exploite pas l’avantage principal du deep learning. En pratique, la solution s'avérera surement être un cauchemar à gérer, comme les premiers systèmes informatiques qui reposaient sur un ensemble de règles.
Un des avantages clés apportés à la logistique prédictive par les avancées du deep learning est que l’établissement de plusieurs types de prévisions ne nécessite pas plus d’efforts que les prévisions classiques de la demande. Presque tous les efforts sont concentrés dans la phase de préparation des données, puis sur la mise en cohérence de l’organisation de l’entreprise pour tirer au mieux parti des prévisions nouvellement disponibles.
La Supply Chain Quantiative adopte le deep learning pour bénéficier, dès que possible, de la logistique prédictive. Au lieu de se concentrer uniquement sur les prévisions de la demande, la Supply Chain Quantiative cherche à prendre en compte toutes les sources d’incertitude de la chaîne d'approvisionnement : délais, défauts de production, évolutions du marché, etc. En coulisses, la Supply Chain Quantiative utilise largement les technologies de deep learning, qui permettent de générer plusieurs types de prévisions pour répondre précisément aux besoins logistiques de l’entreprise. Cette approche est très différente du point de vue classique, dans lequel des prévisions hebdomadaires ou mensuelles de la demande sont censées résoudre des problèmes sans grand rapport avec celles-ci.
Les prévisions probabilistes pour maîtriser l'incertitude
Face à l’incertitude irréductible généralement rencontrée lorsque l’on anticipe les événements qui vont se produire sur une chaîne d'approvisionnement complexe, il est tout à fait opportun de prévoir les issues les plus probables, mais également de nombreuses alternatives. Les prévisions probabilistes en représentent la formalisation statistique la plus courante. Elles fournissent une estimation statistique de toutes les issues possibles. Cet estimateur généralisé prend la forme d’une distribution de probabilités associée à ces dernières. Les prévisions probabilistes peuvent être considérées comme une variante extrême de la méthodologie du « et si ? » dans laquelle tous les scénarios sont envisagés.
Malgré leur aspect théorique, elles sont en fait très simples à utiliser. Prenons par exemple des prévisions probabilistes de la demande. Au lieu de calculer un seul chiffre qui représente la valeur attendue de la future demande moyenne, nous calculons une liste de probabilités : la probabilité d’observer une demande de 0, 1, 2, 3, etc. unité(s). Pour visualiser toutes les probabilités, l’approche la plus courante repose sur un histogramme, dans lequel chaque classe représente la probabilité associée à un niveau de demande spécifique. L’ensemble de ces probabilités forment une « distribution de probabilités ».
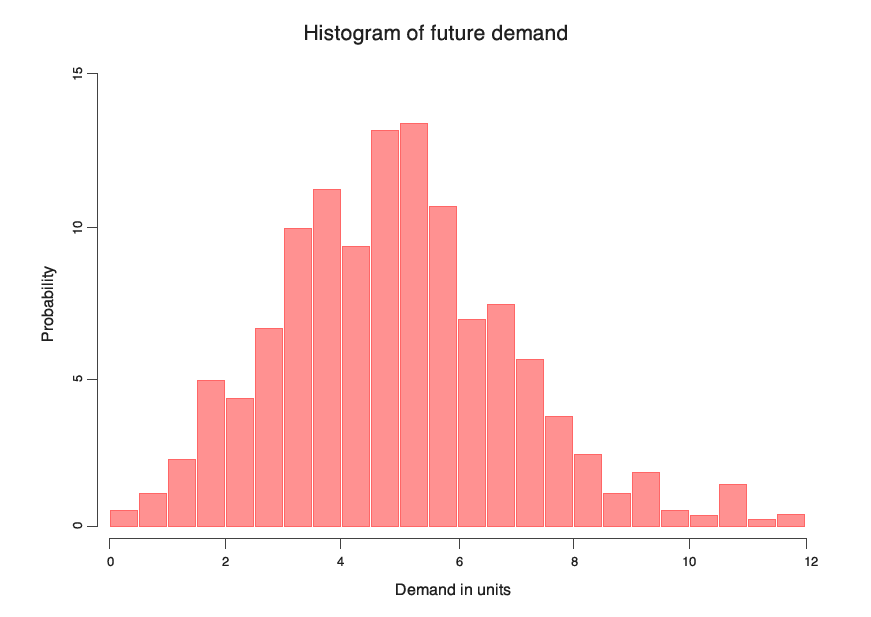
Les prévisions de distributions de probabilités, c’est-à-dire les prévisions probabilistes, généralisent les prévisions moyennes ou médianes traditionnelles. Elles peuvent sembler bien plus complexes que ces dernières, mais sont en fait très courantes, largement utilisées dans de nombreux domaines. Par exemple, presque tous les derniers progrès du deep learning, qui rendent possible le fonctionnement des véhicules autonomes, reposent sur une perspective probabiliste (une perspective bayésienne plus précisément). Les prévisions probabilistes sont bien connues : des milliers d’articles de recherche ont déjà été publiés sur le sujet et nombre d’implémentations logicielles les mettent en œuvre.
La Supply Chain Quantiative souligne le fait que la forme de prévision utilisée est probabiliste. En effet, en logistique, les situations coûteuses ne sont pas les situations moyennes, mais les situations extrêmes : une forte demande inattendue qui crée une rupture de stock ou, inversement, une baisse de la demande qui résulte en un excédent de stock. Les prévisions probabilistes font face au problème en établissant la probabilité de chaque situation possible, dont les situations problématiques. Elles sont les fondements de la gestion structurée des risques en logistique. Grâce à ces prévisions, il devient possible limiter de façon rentable les problèmes envisagés. La logistique est un jeu de compromis : éviter toute rupture de stock implique généralement un stock infini, ce qui n’est pas une option raisonnable. Sans prévisions probabilistes, la comparaison des coûts de stockage et des coûts de rupture de stock ne repose que sur des conjectures.
Un des inconvénients mineurs des prévisions probabilistes est que celles-ci ont tendance à consommer beaucoup plus de ressources informatiques que les méthodes de prévision simple. S’il est notamment faisable de mettre en œuvre un modèle classique de prévisions (lissage exponentiel par exemple) dans Microsoft Excel, la plupart des modèles de prévisions probabilistes nécessitent des ressources plus importantes que celles d’une feuille de calcul. Cependant, avec l’arrivée du cloud computing, les ressources de calcul n’ont jamais été si peu chères : certaines plates-formes proposent déjà des prix publics inférieurs à 10 $ pour 1 000 heures de calcul sur un serveur haut de gamme 2 GHz monocœur. En pratique, pourtant, pour bénéficier de cette puissance de calcul à faible coût, le logiciel de prévisions probabilistes utilisé doit être conçu pour fonctionner sur des plates-formes cloud.
La plupart des algorithmes de prévisions probabilistes sont effectivement issus des observations et résultats du vaste domaine du deep learning. Néanmoins, tout comme vous n’avez pas besoin d’être un expert en deep learning pour utiliser un logiciel de lutte contre le courrier indésirable — qui repose sur le deep learning — et protéger votre messagerie, vous n’avez pas besoin d’être un expert en deep learning pour améliorer les performances de votre chaîne d'approvisionnement grâce à ces technologies. Comme mentionné ci-dessus, les deux aspects clés de du deep learning sont justement l’automatisation et l’élimination (presque complète) des réglages manuels à effectuer sur les modèles statistiques.
