Per ottimizzare la supply chain, occorre essere in grado di anticipare le esigenze future del mercato, attraverso una previsione della domanda. A questa conclusione si era giunti già nel corso del Novecento: le previsioni, però, erano concepite per adattarsi alle limitate capacità dei computer dell'epoca; alcuni metodi previsionali, addirittura, erano pensati per calcoli eseguiti a mano. L'accesso a risorse di calcolo più potenti ha radicalmente cambiato la prospettiva: uno dei vantaggi più immediati è la maggiore accuratezza, accompagnata da una migliore
espressività delle previsioni. Benché possa sembrare strano, però, l'aspetto più importante da un punto di vista logistico è un altro: l'avvento delle
previsioni probabilistiche. Combinando l'approccio probabilistico con gli strumenti all'avanguardia offerti dal machine learning (algoritmi e software corrispondenti), la supply chain quantitativa riesce ad affrontare un ventaglio di problemi molto più ampio rispetto ai metodi tradizionali di previsione e ottimizzazione logistica.
Previsioni tradizionali: caratteristiche e limiti
Con il termine "previsioni tradizionali" facciamo riferimento alle
previsioni medie, periodiche, equispaziali, di serie temporali. Sebbene il loro interesse pratico dal punto di vista della moderna ottimizzazione logistica sia piuttosto limitato, questo tipo di previsione rimane di gran lunga il più usato per la gestione logistica e la pianificazione della domanda; inoltre, la sua importanza storica ha contribuito a plasmare diversi metodi di gestione delle scorte, che ne hanno ereditato tutti i limiti.
Vediamo in dettaglio quali sono le previsioni di questo tipo:
- previsione media: la previsione tenta di individuare il valore medio della domanda futura; una previsione ben bilanciata ha il 50% della massa della domanda futura superiore alla previsione, e l'altro 50% inferiore alla domanda futura. Possiamo provare matematicamente che stimare la media equivale a minimizzare l'errore dei minimi quadrati;
- previsione periodica: la domanda futura è suddivisa in una serie di periodi, come giorni, settimane, mesi o anni. La previsione prende la forma di un vettore reale. Le dimensioni del vettore sono comunemente definite orizzonte. Ad esempio, se la previsione riguarda le prossime 10 settimane, il periodo è la settimana, mentre l'orizzonte è 10;
- previsione equispaziale: si ipotizza che i periodi abbiano proprietà uniformi e che siano di durata identica. L'ipotesi può considerarsi valida per i periodi di giorni o settimane, ma è meno corretta per i periodi di mesi o anni. Nonostante l'approssimazione, il processo numerico dei periodi non differenzia fra i vari periodi e dà per scontato che l'uniformità sia totale;
- previsione delle serie temporali: si ipotizza che i dati storici presentino un formato omogeneo rispetto alla previsione che verrà prodotta. I dati storici sono modellati come vettore reale relativo allo stesso periodo selezionato per la previsione. La lunghezza del vettore di input è limitata dalla profondità dei dati storici disponibili.
A volte, la stima media è sostituita dalla
mediana. In questo caso, una previsione ben bilanciata ha il 50% di possibilità di essere superiore o inferiore alla domanda futura, indipendentemente dalla massa della domanda. Ottimizzare uno stimatore al fine di ottenere il valore mediano migliore equivale a minimizzare l'errore medio assoluto (errore dei minimi quadrati per la media). Per quanto ci riguarda, non fa differenza se le previsioni sono medie o mediane, né se il parametro è l'errore medio assoluto percentuale o una sua variante ponderata. Per maggiore semplicità, quindi, faremo riferimento a tutte le previsioni di questo tipo come "previsioni tradizionali", raccogliendo sotto lo stesso ombrello anche le loro varianti meno comuni.
Le previsioni di questo tipo sono talmente radicate nel mondo della logistica, che non è facile fare un passo indietro e rendersi conto di quali implicazioni possano avere. Abbiamo anche sperimentato come molte delle soluzioni software più popolari non facciano altro che inglobare le previsioni tradizionali nella propria architettura, ad esempio in database che contengono 52 colonne, una per ogni settimana dell'anno. In questo modo, sono gli stessi software a sbarrare la strada a intere categorie di ottimizzazione logistica.
L'incertezza c'è, ma nessuno ne parla
La domanda futura porta con sé un grado elevato di incertezza, che non è possibile ridurre. Molti degli eventi che colpiscono i mercati capitalistici non possono essere ricondotti tra i ranghi di un modello deterministico: un'azienda non può prevedere, per esempio, quando il competitor deciderà di abbassare i propri prezzi e conquistare così nuove quote di mercato; né prevedere che in un porto cinese si verifichi un incidente industriale, che rallenterà le consegne da un importante fornitore; e neanche prevedere se una nuova tecnologia, sviluppata all'interno dell'azienda stessa, si rivelerà superiore al sistema attualmente in uso.
Detta così, l'incertezza sembra un fattore evidente e ovvio, ma è curioso che le previsioni tradizionali ignorino totalmente il problema, invece che affrontarlo: nell'ottica delle previsioni tradizionali, anzi, il problema sembra non esistere affatto. Nella pratica esistono tecniche per valutare l'accuratezza delle previsioni, come il backtesting, ma si tratta di procedimenti esterni che non hanno quasi nulla a che vedere con il processo di previsione.
Ignorando l'incertezza, le previsioni non sono semplicemente in grado di esprimere alcune situazioni. Facciamo l'esempio di un grossista che abbia come clienti diverse reti di vendita al dettaglio, piuttosto importanti. Un determinato prodotto potrebbe sembrare associato a una domanda piuttosto stabile, poiché viene ordinato ogni settimana in quantità che restano più o meno le stesse nel corso del tempo. Tuttavia, studiando meglio la struttura della domanda, si capisce che gli ordini provengono da una sola rete di vendita. Se questa decidesse improvvisamente di non rivolgersi più al grossista per acquistare quel prodotto, la domanda crollerebbe a zero, trasformando le giacenze ancora rimaste nel magazzino del grossista in stock morto. Quindi, anche se la domanda media proiettata per il prodotto può essere elevata, esiste un rischio reale che la domanda precipiti improvvisamente a zero. A livello di modelli matematici, questo rischio non può essere espresso semplicemente riducendo la domanda. In sintesi, le previsioni tradizionali non riescono a riprodurre una situazione come questa, che potrebbe avere due evoluzioni diametralmente opposte.
Errori sistematici conosciuti nell'evoluzione della domanda
Adottare un approccio basato sulle serie temporali per prevedere la domanda significa dare per scontato che i dati storici a nostra disposizione riflettano correttamente la domanda. Nella pratica, però, le cose stanno quasi sempre diversamente, poiché la domanda del mercato è osservata solo indirettamente. Potrebbe sembrare un aspetto di poco conto, ma in realtà si tratta di un nodo cruciale: lo storico degli ordini cliente è solo un'approssimazione della domanda del mercato, e non rappresenta la domanda reale, che in una certa misura rimane comunque sconosciuta. Ad esempio, se un'azienda si trova in una situazione di rottura di stock, i clienti si rivolgono a qualcun altro per trovare ciò di cui hanno bisogno. Le quantità acquisite attraverso canali alternativi per mitigare gli effetti di una rottura di stock non vengono tenute in conto nello storico delle vendite, generando così un errore sistematico.
Gli errori sistematici sono molto frequenti. Anche quando tutte le richieste dei clienti vengono registrate, in tempo o meno, gli errori sistematici sono comunque presenti. Prendiamo per esempio un magazzino regionale che serve una serie di punti vendita al dettaglio: ogni giorno, ogni punto vendita invia al magazzino un ordine di rifornimento. Gli ordini non tengono conto delle scorte disponibili nel magazzino; è responsabilità del magazzino fare del proprio meglio per servire tutti i punti vendita, sulla base delle scorte fisicamente presenti. In una situazione di questo tipo, se un ordine non può essere elaborato il giorno 1, verrà rimandato al giorno 2, quando le quantità da riordinare saranno ancora maggiori, aggravando così la rottura di stock. Si crea però un'altra disfunzione: di fronte a una rottura di stock, i punti vendita tendono a ordinare molto di più di quanto non farebbero in condizioni normali, perché continuano a riordinare le stesse quantità, visto che non sono state ricevute. Quindi, anche se tutti gli ordini sono registrati, non si può dire che le quantità totali ordinate riflettano correttamente la domanda. La situazione viene ulteriormente complicata dalla rottura di stock del magazzino, che a sua volta genera nuove rotture di stock a livello di punto vendita, che di certo non vengono registrate dai clienti che percorrono i corridoi del negozio.
Considerando i moderni mezzi statistici a nostra disposizione, il problema non è tanto l'esistenza degli errori sistematici, quanto piuttosto l'incapacità delle previsioni tradizionali di rifletterli. Il metodo delle serie temporali non è semplice, è semplicistico. Inoltre, i dati di input, elaborati in un modello che prevede un vettore reale associato ai periodi passati, non è in grado di catturare le eventuali informazioni disponibili a proposito di questi errori. Di conseguenza, per ridimensionare il problema, le previsioni tradizionali ricorrono a una fase di pre-elaborazione, che utilizza ricorsivamente il procedimento previsionale stesso per "riempire i buchi" nei periodi in cui è certo che la domanda sia soggetta a un errore sistematico (es. sostituendo gli zeri corrispondenti a una rottura di stock con i valori della domanda previsti inizialmente per quel periodo). In questo modo, però, l'azienda accumula previsioni sbagliate su previsioni doppiamente sbagliate: prima di tutto, fare previsioni su previsioni è un ottimo modo per ottenere risultati imprecisi; inoltre, procedere in questa direzione significa complicare ulteriormente la preparazione dei dati, che è già di per sé la fase più complicata nell'elaborazione di un modello quantitativo.
Le previsioni non devono riguardare solo la domanda
Il metodo previsionale basato sulle serie temporali è stato così preponderante nella storia della logistica, che ha finito per diventare quello che si dice un
martello d'oro: se tutto quello che abbiamo è un martello, allora tutto il resto è un chiodo. La domanda futura è però solo uno dei tanti elementi che è necessario prevedere, e la previsione con le serie temporali è solo uno dei possibili approcci.
Anche i lead time sono di fondamentale importanza. Le scorte tenute a magazzino da un'azienda sono appropriate solo se le quantità immagazzinate sono sufficienti a coprire la domanda per il periodo del lead time. Tenere più scorte è inutile, perché per allora il magazzino sarà stato rifornito. Eppure, i lead time hanno comportamenti complessi. Ipotizzare che il lead time di un fornitore sia di 7 giorni solo perché così è scritto nel contratto è un atteggiamento poco efficiente e addirittura pericoloso: poco efficiente, perché i fornitori tendono a negoziare lead time che ritengono di poter sostenere anche in circostanze avverse (anche nel peggiore dei casi), ma nella pratica non è affatto raro osservare fornitori che superano di gran lunga i lead time contrattuali; pericoloso, perché se un fornitore non rispetta mai i propri lead time contrattuali, il resto della supply chain continuerà a "fingere" che vada tutto bene e non tenterà di mitigare i problemi causati dal fornitore.
Insomma, anche i lead time vanno previsti. Proprio come la domanda, anch'essi possono essere previsti a partire dai dati storici e anch'essi seguono schemi di comportamento complessi dal punto di vista statistico, come la stagionalità che viene talvolta usata per rifinire le previsioni. Ad esempio, i produttori con sede in Cina hanno spesso lead time che si allungano anche di 3 o 4 settimane a ridosso del Capodanno lunare, quando le fabbriche rimangono chiuse per la festività.
Oltre a domanda e lead time, esistono molti altri elementi della supply chain che richiedono una previsione di qualche tipo. Vediamo qualche esempio:
- resi dei clienti: nell'e-commerce dedicato all'abbigliamento, i clienti arrivano a restituire buona parte dei prodotti ordinati. In Germania, ad esempio, è abitudine dei clienti ordinare più paia di scarpe in numeri diversi, per poi restituire il numero che non calza bene. In molti casi, le quantità restituite superano il 30% delle quantità inizialmente ordinate. È quindi buona norma prevedere anche le quantità dei resi;
- beni ricevuti inservibili: i rivenditori alimentari, che hanno a che fare con prodotti fragili e deperibili, ricevono spesso partite in cui buona parte della merce non supera i controlli di qualità. Ad esempio, metà dei cestini di fragole ricevuti da un magazzino potrebbero essere eliminati seduta stante perché considerati non più adatti alla vendita. Quando si invia un ordine di acquisto a un fornitore, è importante tenere conto della parte di merce prevista che non passerà i test di qualità. È quindi essenziale prevedere anche quanta parte dei prodotti ordinati verrà eliminata;
- imprecisioni nei registri elettronici: nel commercio al dettaglio, l'inventario a livello di punto vendita è spesso poco accurato. Capita spesso, infatti, che i clienti danneggino, rubino o semplicemente spostino i prodotti all'interno del negozio, creando così delle discrepanze tra le scorte inserite nei registri elettronici e le scorte fisiche realmente presenti sugli scaffali. Queste discrepanze possono essere previste a partire dai dati storici sulle correzioni delle scorte eseguite dopo un conteggio delle quantità presenti.
Ogni settore presenta poi problemi più specifici, per cui occorre elaborare una previsione o una qualche stima statistica predittiva. È quindi importante identificare tali problemi, altrimenti la supply chain continuerebbe a funzionare secondo regole che potrebbero essere appropriate o meno, senza avere la possibilità di confrontare e migliorare tali regole.
Previsioni generalizzate con il machine learning
Negli ultimi decenni, il settore del machine learning, che possiamo definire come un incrocio tra informatica e statistica, ha fatto passi da gigante. Ancora lontano dall'aver raggiunto il massimo delle proprie potenzialità, il machine learning sta crescendo a ritmi sempre più sostenuti, grazie alle recenti scoperte in materia di apprendimento profondo, e può già vantare numerose implementazioni software, nonché tecniche quantitative per estrarre e sfruttare conoscenze contenute in set di dati di qualsiasi tipo. Non è nostro intento trattare qui le caratteristiche del machine learning, ma è comunque importante capire a cosa serve nell'ambito della supply chain quantitativa.
Il machine learning ci offre un metodo per gestire in modo sistematico quantità anche significative di dati. Avere più dati non rende le cose più difficili: al contrario, agevola il procedimento. Questo passaggio, controintuitivo rispetto alle previsioni tradizionali, è però fondamentale: molti professionisti della supply chain, quando si trovano di fronte a un problema, sono tentati di suddividerlo in parti più piccole e meglio gestibili. Quando si ricorre al machine learning, invece, una quantità minore di dati si traduce in un carico di lavoro maggiore per l'esperto di dati, che deve fare in modo che gli algoritmi funzionino nonostante un set di dati limitato. Gli algoritmi di machine learning, tutti, sono pensati per funzionare meglio con dati più numerosi. Molte delle applicazioni di maggior successo del machine learning (come ad esempio il riconoscimento vocale o la traduzione automatica) sono arrivate a risultati soddisfacenti iniziando a elaborare set di dati più ampi rispetto ai primi tentativi.
Una volta raccolti abbastanza dati, il machine learning ci offre numerosi metodi che richiedono pochissimo sforzo per iniziare a generare diversi tipi di previsione. Creare un sistema che non necessitasse di aggiustamenti manuali nella pipeline dei dati è stato a lungo un "chiodo fisso" sia dei circoli accademici, sia degli sviluppatori software; al momento, molti dei moderni metodi di machine learning richiedono un livello di aggiustamento manuale quasi pari allo zero. Anzi, gli addetti ai lavori sono sempre più scettici riguardo agli approcci che richiedono più di qualche regolazione superficiale: questo punto di vista ha permesso alcuni dei maggiori successi in tema di machine learning e, in particolare, di apprendimento profondo. Certo, anche se gli algoritmi di machine learning non necessitano di grossi aggiustamenti per mano umana, la preparazione dei dati richiede invece uno sforzo notevole, sforzo che comunque non ha nulla a che vedere con gli algoritmi utilizzati in una fase successiva.
Suggeriamo quindi ai professionisti della logistica di diffidare delle soluzioni statistiche predittive che offrono anche solo la possibilità di rifinire manualmente le previsioni: una funzionalità di questo tipo indica infatti che la soluzione non tiene conto delle scoperte più importanti acquisite in materia di machine learning. In pratica, è quasi una garanzia che la soluzione sarà soggetta agli stessi limiti che affliggevano i sistemi basati su regole in uso qualche decennio fa, che si sono rivelati un vero incubo a livello di manutenzione.
Uno dei vantaggi dei progressi del machine learning è che generare diversi tipi di previsione non richiede uno sforzo molto maggiore che produrre previsioni tradizionali. Il grosso del lavoro consiste nel preparare i dati e, in seguito, organizzare l'azienda in modo da allineare l'attività ai risultati ottenuti e trarre il massimo dalle nuove tipologie di previsione disponibili.
La supply chain quantitativa si avvale del machine learning per sfruttarne il potenziale predittivo nell'ambito della logistica, laddove possibile. Invece che focalizzarsi su semplici previsioni della domanda, la supply chain quantitativa punta a confrontare tutte le fonti di incertezza nella supply chain: lead time, difetti di produzione, variazioni del mercato, ecc. Insomma, la supply chain quantitativa fa largo uso di tecnologie di machine learning, che consentono di generare diversi tipi di previsione, al fine di rispondere perfettamente alle esigenze della supply chain. Si tratta di un approccio ben diverso rispetto a quello tradizionale, che tenta di costringere previsioni della domanda mensili o settimanali a trovare una soluzione a problemi non strettamente connessi tra loro.
Previsioni probabilistiche: ovviare all'incertezza
Quando consideriamo problemi complessi relativi alla supply chain, abbiamo a che fare con un certo grado di incertezza, che non possiamo eliminare: in questi casi, è auspicabile prevedere non solo lo scenario futuro più probabile, ma anche le altre possibili alternative. La previsione probabilistica non è altro che la formalizzazione più comune, a livello statistico, di questo assunto, perché genera una stima statistica per ogni possibile scenario; questo stimatore generalizzato prende la forma di una distribuzione di probabilità associata a ogni possibile scenario. La previsione probabilistica può quindi essere considerata come una variante piuttosto estrema dell'analisi what if, dove vengono considerate tutte le alternative possibili.
Nonostante questo sembri un metodo piuttosto teorico, è in realtà semplice e facilmente gestibile. Consideriamo una previsione probabilistica della domanda: invece che calcolare un singolo valore che rappresenti il valore atteso per la domanda media futura, calcoliamo una lista di probabilità, che comprende la possibilità che si verifichi una domanda pari a 0 unità, a 1 unità, a 2 unità, a 3 unità, ecc. Per visualizzare tutte le probabilità, il sistema più comune consiste nell'utilizzare un istogramma, dove ogni rettangolo rappresenta la probabilità associata a un determinato livello di domanda. Le probabilità prese tutte insieme vengono definite
distribuzione di probabilità.
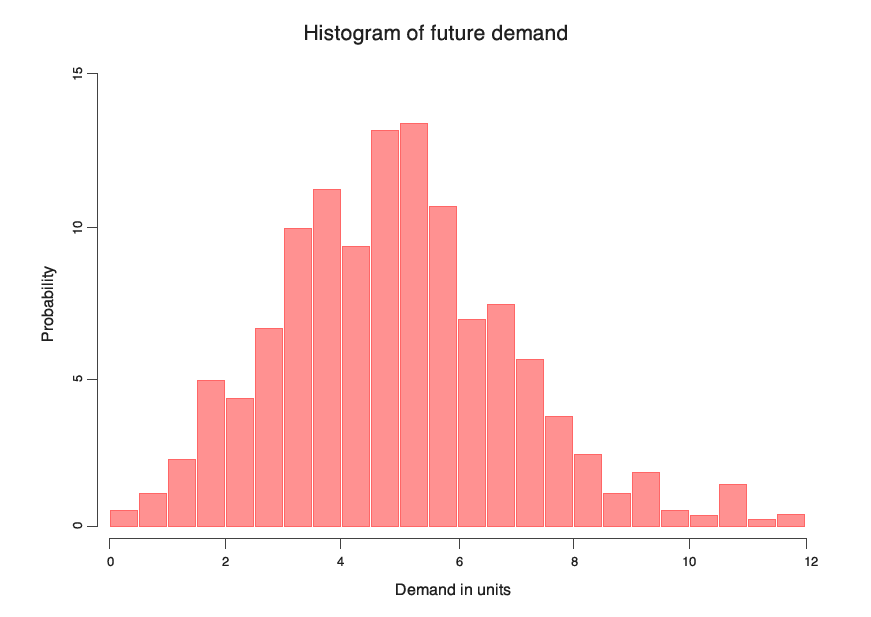
Le distribuzioni previsionali di probabilità, ossia le previsioni probabilistiche, sono una generalizzazione delle previsioni tradizionali medie o mediane. Sebbene a prima vista possano sembrare più complesse, le previsioni probabilistiche sono in realtà un metodo statistico ormai consolidato e già applicato nei campi più diversi. Ad esempio, quasi tutti i progressi in termini di machine learning che stanno facendo dei veicoli a guida autonoma una realtà sono basati su una prospettiva probabilistica (e, più precisamente, una prospettiva bayesiana, ma non entreremo ora nei dettagli). La previsione probabilistica è stata inoltre ampiamente discussa in una serie di pubblicazioni scientifiche dedicate all'argomento e applicata in numerose implementazioni software già disponibili.
La supply chain quantitativa preferisce la previsione probabilistica. Infatti, nella logistica non sono le situazioni medie a comportare un costo per l'azienda, ma quelle estreme: una domanda inaspettatamente alta causa una rottura di stock, mentre una domanda inaspettatamente bassa porta ad accumulare scorte eccessive. Le previsioni probabilistiche affrontano il problema analizzando le probabilità che si verifichi ognuno dei possibili scenari, inclusi quelli più problematici: in questo modo, diventano la chiave di volta per una gestione del rischio strutturata in ambito logistico e consentono di mitigare i problemi in modo redditizio. La supply chain si basa infatti su una serie di compromessi: per non avere rotture di stock, bisogna avere scorte infinite, il che ovviamente è fuori discussione. Senza le previsioni probabilistiche, confrontare il costo delle scorte rispetto al costo di una rottura di stock si riduce a un indovinello.
Uno dei piccoli svantaggi delle previsioni probabilistiche è che tendono a richiedere risorse di calcolo ben più imponenti rispetto alle previsioni tradizionali. In particolare, se è possibile implementare un metodo di previsione tradizionale (es. lo smorzamento esponenziale) in Microsoft Excel, molti dei metodi probabilistici, se non tutti, richiedono capacità di calcolo che vanno molto al di là di quelle di un semplice foglio di calcolo. Con l'avvento del cloud, però, le risorse di calcolo sono diventate decisamente più economiche rispetto al passato: alcune piattaforme cloud offrono già prezzi al pubblico inferiori ai $10 per 1000 ore di calcolo su un server single core di alto livello a 2GHz. Nella pratica, però, per poter approfittare di questa potenza di calcolo a così basso costo, il software che supporta le previsioni probabilistiche deve essere concepito fin dall'inizio per poter funzionare all'interno di una piattaforma cloud.
Ancora una volta, la maggior parte degli algoritmi di previsione probabilistica deriva dalle scoperte avvenute nel campo del machine learning. Tuttavia, anche i filtri antispam delle nostre caselle di posta elettronica sono stati resi possibili dal machine learning; e, proprio come non c'è bisogno di essere un esperto di machine learning per usare il filtro antispam, non c'è bisogno di essere un esperto di machine learning neanche per ottimizzare le prestazioni della supply chain attraverso tecnologie di questo tipo. Come dicevamo prima, due degli aspetti principali del machine learning sono il ruolo centrale dell'automazione e la (quasi) eliminazione di tutti gli aggiustamenti manuali sui modelli statistici.
