di Joannes Vermorel, Novembre 2020Una previsione viene definita probabilistica (anziché deterministica), quando contiene un insieme di probabilità associate a tutti i possibili risultati futuri, piuttosto che individuare un particolare risultato come "la" previsione. Le previsioni probabilistiche sono importanti in quelle situazioni in cui l'incertezza è inevitabile, cosa che si verifica quasi sempre quando si ha a che fare con sistemi complessi. Per le supply chain, le previsioni probabilistiche sono essenziali per produrre decisioni valide a fronte di condizioni future incerte. Queste previsioni affrontano al meglio, nello specifico, due aspetti chiave dell'analisi della supply chain: la domanda e il lead time. La prospettiva probabilistica si presta per natura alla prioritizzazione economica delle decisioni sulla base dei loro rendimenti attesi (ma incerti). Esiste una varietà di modelli statistici che forniscono previsioni probabilistiche. Da un punto di vista strutturale, alcuni sono più vicini alle loro controparti deterministiche, mentre altri sono molto diversi. La valutazione dell'accuratezza di una previsione probabilistica richiede metriche specifiche, differenti da quelle utilizzate per le previsioni deterministiche, così come l’utilizzo di previsioni probabilistiche richiede strumenti specifici che divergono da quelli utilizzati per le previsioni deterministiche.
Previsioni deterministiche e previsioni probabilistiche a confronto
L'ottimizzazione delle supply chain si basa sulla corretta anticipazione degli eventi futuri. A livello numerico, questi eventi sono anticipati attraverso
previsioni, che comprendono una grande varietà di metodi matematici utilizzati per quantificare proprio questi eventi futuri. A partire dagli anni '70, la forma di previsione più utilizzata è stata la previsione deterministica in serie temporali: una quantità misurata nel tempo – ad esempio la domanda (in unità) di un prodotto – viene proiettata nel futuro. La sezione passata delle serie temporali è il dato storico, mentre la sezione futura è la previsione.
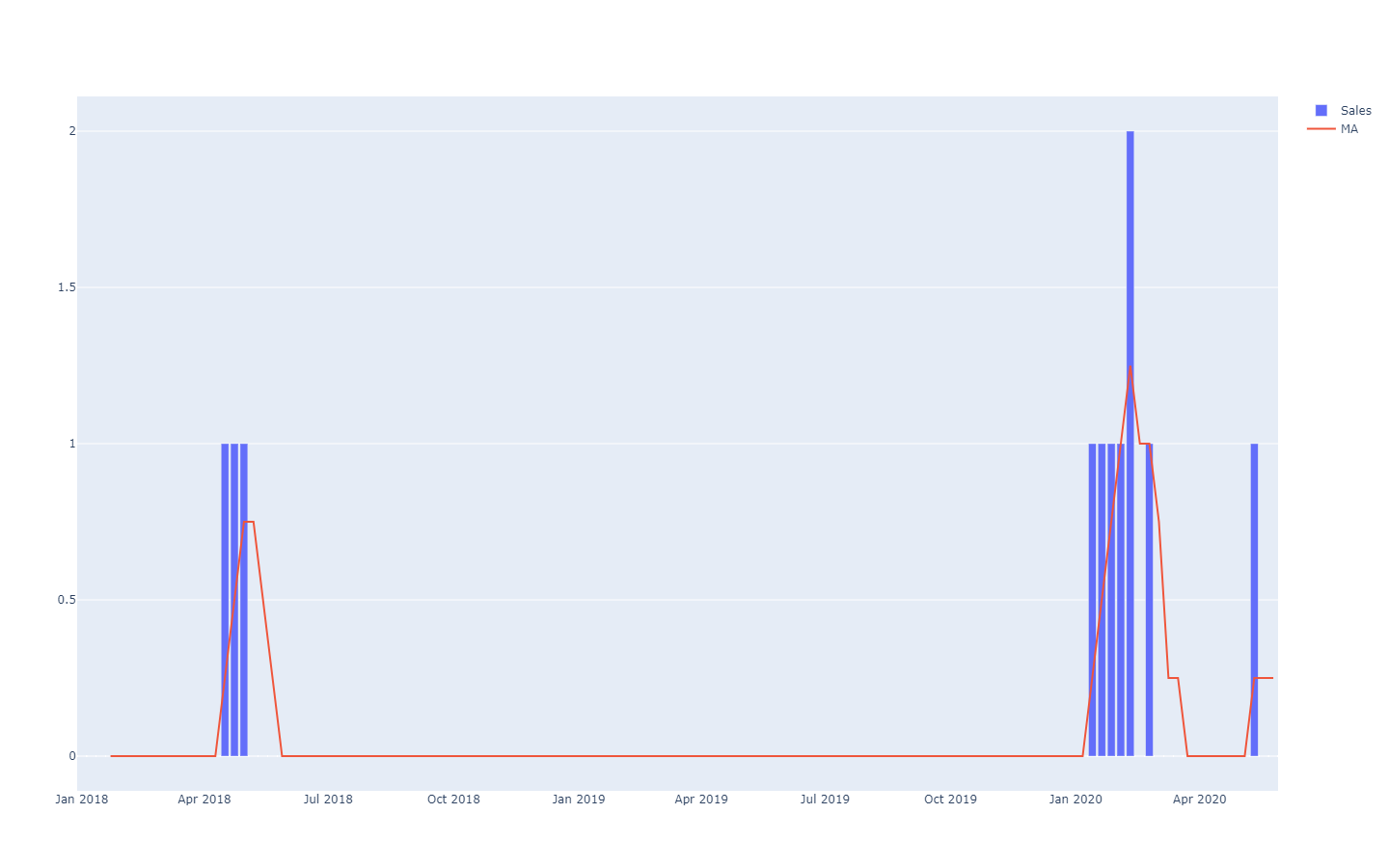
MA è l'acronimo di "media mobile", che non è particolarmente ben tollerata nelle serie temporali rade.Queste previsioni di serie temporali sono dette
deterministiche perché, per ogni punto di tempo futuro, la previsione fornisce un unico valore che ci si aspetta corrisponda il più possibile al risultato futuro. Anche se la previsione restituisce un solo valore, si sa che è improbabile che sia totalmente corretta. I risultati futuri si discosteranno dalla previsione. L'aderenza della previsione deterministica ai suoi risultati futuri è valutata quantitativamente attraverso metriche di accuratezza, come ad esempio l'errore quadratico medio (in inglese
Mean Squared Error, o MSE).
Le previsioni probabilistiche adottano invece una prospettiva diversa sull'anticipazione dei risultati futuri. Invece di produrre un solo valore come "migliore" risultato, la previsione probabilistica assegna una
probabilità a ogni possibile risultato. In altre parole, tutti gli eventi futuri rimangono possibili, ma non ugualmente probabili. Qui di seguito è riportata la rappresentazione di una previsione probabilistica di serie temporali che mostra l'"effetto fucile", che si osserva in genere nella maggior parte delle situazioni del mondo reale. Ritorneremo su questa rappresentazione in modo più dettagliato in seguito.
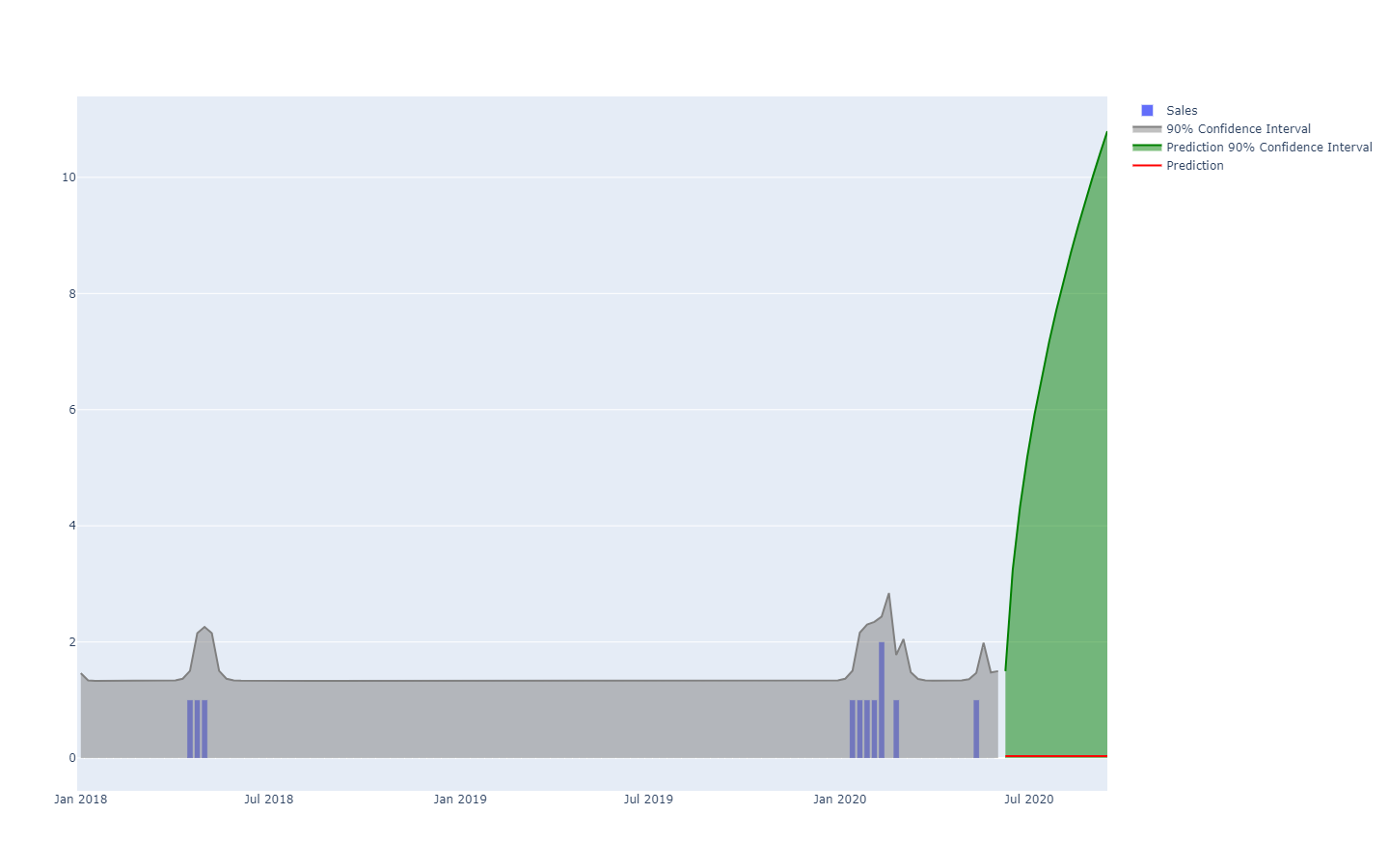
Una previsione probabilistica che illustra una situazione di grande incertezza.Le serie temporali, una quantità misurata nel tempo, sono probabilmente il modello di dati più conosciuto e utilizzato. Questo modello può essere pronosticato sia con mezzi deterministici che probabilistici. Tuttavia, esistono anche altri modelli, in genere più sofisticati, che si prestano a previsioni di entrambi i tipi. Ad esempio, un'azienda che ripara motori a reazione potrebbe voler anticipare l'elenco esatto dei pezzi di ricambio che saranno necessari per un'imminente operazione di manutenzione. Questa anticipazione può assumere la forma di una previsione, ma non sarà una previsione di serie temporali. La previsione deterministica associata a questa operazione consiste nell'elenco esatto dei pezzi di ricambio e delle quantità associate. Al contrario, la previsione probabilistica è la probabilità per ogni combinazione di parti (quantità incluse) che questa specifica combinazione sia quella necessaria per eseguire le riparazioni.
Inoltre, mentre il termine "previsione" enfatizza un'anticipazione di qualche tipo, l'idea può essere generalizzata a qualsiasi tipo di affermazione
statisticamente dedotta su un sistema, anche per le sue proprietà passate (ma sconosciute). La pratica della previsione statistica è emersa nel corso del XX secolo, prima dell'avvento della più moderna prospettiva di
apprendimento statistico, che racchiude tutte le estrapolazioni di dati che possono essere effettuate, indipendentemente dalla dimensione temporale. Per chiarezza, continueremo a usare il termine "previsione" nel seguito dell'articolo, anche se l'aspetto temporale equipara sempre il passato con il noto e il futuro con l'ignoto. Ad esempio, un'azienda potrebbe voler stimare le vendite che avrebbero avuto luogo in un negozio se un determinato prodotto non fosse stato esaurito in un determinato giorno. Il calcolo è utile per quantificare l'entità del problema in termini di qualità del servizio. Tuttavia, poiché l'evento è passato, la cifra "reale" delle vendite non sarà mai osservata. Ciononostante, supponendo che non sia stato ancora minimamente osservato, il calcolo statistico della domanda passata è un problema che si avvicina molto al calcolo della domanda futura.
Le previsioni probabilistiche sono più complete – dal punto di vista informativo – delle loro controparti deterministiche. Sebbene la previsione deterministica fornisca una "migliore ipotesi" sull'esito futuro, non dice nulla sulle alternative. Di fatto, è sempre possibile convertire una previsione probabilistica nella sua controparte deterministica attraverso la media, la mediana, la moda, ecc., della distribuzione delle probabilità. Non vale però il contrario: non è possibile, cioè, ricavare una previsione probabilistica da una deterministica.
Tuttavia, pur essendo statisticamente superiori alle previsioni deterministiche, le previsioni probabilistiche rimangono poco utilizzate nel campo della supply chain. Eppure, la loro popolarità è andata costantemente aumentando nel corso dell'ultimo decennio. Storicamente, le previsioni probabilistiche sono emerse più tardi, poiché richiedono molte più risorse di calcolo. Inoltre, il loro utilizzo ai fini della supply chain necessita di strumenti software specializzati, spesso non disponibili.
Esempi di utilizzo nella supply chain
L'ottimizzazione di supply chain consiste nel prendere la decisione "giusta" – al momento presente – che meglio affronterà una situazione futura che può essere stimata solo in modo imperfetto. Tuttavia, l'incertezza associata agli eventi futuri è, in larga misura, inevitabile. Pertanto, l'azienda ha bisogno che la decisione sia solida se l'anticipazione dell'evento futuro – la previsione – è imperfetta. Questo è stato fatto
in minima parte dalla metà del XX secolo attraverso l'analisi delle scorte di sicurezza. Come vedremo più avanti, però, oltre all'interesse storico, non c'è più motivo di privilegiare le scorte di sicurezza rispetto alle formule numeriche probabilistiche "native".
La prospettiva della previsione probabilistica assume una posizione radicale rispetto all'incertezza: l’approccio cerca infatti di
quantificare al massimo l'incertezza. Nella supply chain, i costi tendono a concentrarsi negli estremi statistici: è una domanda inaspettatamente alta a creare le rotture di stock ed è una domanda inaspettatamente bassa che crea il write-off delle scorte. Nel mezzo, l'inventario "ruota" senza problemi. Le previsioni probabilistiche sono, in poche parole, un tentativo di gestire queste situazioni a bassa frequenza e ad alto costo, onnipresenti nelle moderne supply chain. Le previsioni probabilistiche possono e devono essere viste come un ingrediente fondamentale di qualsiasi pratica di gestione del rischio all'interno della supply chain.
Molti aspetti delle supply chain sono particolarmente adatti alle previsioni probabilistiche, ad esempio:
- La domanda: indumenti, accessori, pezzi di ricambio, così come molti altri tipi di prodotti, tendono a essere associati a una domanda irregolare e/o intermittente. Il lancio di nuovi prodotti può rivelarsi un successo o un insuccesso. Le promozioni dei concorrenti possono cannibalizzare temporaneamente e in modo irregolare ampie porzioni di quote di mercato.
- I lead time: le importazioni dall'estero possono subire tutta una serie di ritardi in qualsiasi punto della supply chain (produzione, trasporto, dogana, ricezione, ecc.). Anche i fornitori locali possono presentare dei lead time più lunghi se riscontrano, ad esempio, un problema di rottura di stock. I lead time tendono ad essere distribuzioni "a coda pesante".
- Il rendimento (alimenti freschi): la quantità e la qualità della produzione di molti prodotti freschi dipendono da condizioni, come il meteo, che sono al di fuori del controllo dell'azienda. Le previsioni probabilistiche quantificano questi fattori per l'intera stagione e offrono la possibilità di andare oltre l'orizzonte di riferimento delle previsioni meteorologiche classiche.
- I resi (e-commerce): quando un cliente ordina lo stesso prodotto in tre taglie diverse, le probabilità che due di queste vengano restituite sono elevate. In generale, anche se vi sono forti differenze regionali, i clienti tendono a sfruttare le politiche di reso favorevoli (se esistenti). La probabilità di reso per ogni ordine dovrebbe essere valutata.
- I rottami (aviazione): i pezzi riparabili – spesso chiamati rotables – a volte non vengono riparati. In questo caso, il pezzo viene scartato, in quanto non è più idoneo ad essere montato su di un aereo. Sebbene in genere non sia possibile sapere in anticipo se un pezzo sopravviverà o meno alla riparazione, le probabilità che il pezzo venga rottamato dovrebbero essere stimate.
- Gli stock (vendita al dettaglio B2C): i clienti possono spostare, danneggiare o addirittura rubare le merci presenti in negozio. Pertanto, il livello delle scorte elettroniche è solo un'approssimazione della reale disponibilità sugli scaffali. Il livello delle scorte, così come percepito dai clienti, dovrebbe essere stimato attraverso una previsione probabilistica.
- etc.
Questo breve elenco dimostra che gli ambiti di applicazione di una previsione probabilistica superano di gran lunga gli ambiti tradizionali delle "previsioni della domanda". L'ottimizzazione ben congegnata di una supply chain richiede di tenere conto di tutte le fonti rilevanti di incertezza. Anche se a volte è possibile ridurre l'incertezza – come sottolinea il concetto della produzione snella – ci sono di solito dei compromessi economici e, di conseguenza, una certa quantità di incertezza rimane inevitabile.
Le previsioni, tuttavia, non sono altro che ipotesi studiate sul futuro. Anche se le previsioni probabilistiche possono essere considerate come opinioni a grana molto fine, non sono sostanzialmente diverse dalle loro controparti deterministiche a questo proposito. Il valore, per quanto riguarda la supply chain, delle previsioni probabilistiche sta nel modo in cui questa struttura a grana fine viene impiegata per fornire decisioni più redditizie. Nello specifico, non ci si aspetta che le previsioni probabilistiche siano più accurate delle loro controparti deterministiche, se si utilizzano metriche di accuratezza deterministica per valutare la qualità delle previsioni.
In difesa della variabilità
Nonostante ciò che molti approcci alla supply chain sostengono, la variabilità è destinata a rimanere, ed è per questo che la previsione probabilistica è necessaria. Il primo errore è considerare che la variabilità sia necessariamente un male per la catena di approvvigionamento: non lo è affatto. Il secondo errore è credere che la variabilità possa essere eliminata dalla progettazione: non può esserlo.
In molte situazioni, la variabilità ha conseguenze positive per le supply chain. Per esempio, dal punto di vista della domanda, la maggior parte dei settori, come ad esempio quello della moda, dei prodotti culturali, del lusso (soft luxury o hard luxury che sia), sono guidati dalla novità: si tratta di aziende "hit or miss". La maggior parte dei nuovi prodotti non sono dei veri e propri successoni (miss), ma quelli che hanno successo (hit) producono rendimenti elevatissimi. Una variabilità aggiuntiva è positiva, perché aumenta la probabilità di rendimenti notevoli, mentre gli aspetti negativi rimangono limitati (nel peggiore dei casi, l'intero inventario viene liquidato). L'incessante flusso di nuovi prodotti immessi sul mercato assicura il costante rinnovamento degli "articoli di successo", mentre i prodotti meno recenti vanno calando.
Dal punto di vista dell'offerta, una procedura di approvvigionamento che garantisce offerte a prezzi altamente variabili è superiore – a parità di condizioni – a una procedura alternativa che genera prezzi molto più stabili (ovvero meno variabili). Infatti, l'opzione a prezzo più basso viene selezionata mentre le altre vengono scartate. Non importa se il prezzo "medio" selezionato è basso, ciò che conta è scoprire le fonti con prezzi più bassi. Quindi, una buona procedura di approvvigionamento dovrebbe essere concepita per aumentare la variabilità, per esempio enfatizzando la ricerca di nuovi fornitori, invece di limitarsi a quelli già esistenti.
A volte, la variabilità può essere vantaggiosa per ragioni più impercettibili. Ad esempio, se un marchio è troppo prevedibile nelle proprie operazioni promozionali, i clienti identificano il modello e cominciano a posticipare l'acquisto a quando si aspettano che ci sia una promozione in arrivo. La variabilità – ma anche l'erraticità – delle attività promozionali attenua in qualche misura questo fenomeno.
Un altro esempio è la presenza di fattori di confusione all'interno della supply chain stessa. Se i nuovi prodotti vengono sempre lanciati sia con una campagna televisiva che con una radiofonica, diventa statisticamente difficile distinguere i rispettivi impatti di TV e radio. L'aggiunta di variabilità all'intensità di ciascuna delle campagne assicura che successivamente si possano estrapolare più informazioni statistiche da tali operazioni, che possono essere trasformate in insight per una migliore allocazione delle risorse di marketing.
Chiaramente, non tutta la variabilità è positiva. Il concetto di produzione snella sottolinea infatti che, sul lato della produzione della supply chain, la variabilità è dannosa, soprattutto quando si tratta di ritardi variabili. Infatti, è possibile che vi si possano accidentalmente insinuare processi LIFO (
last-in first-out), che a loro volta aggravano la variabilità del lead time. In queste situazioni, la variabilità accidentale dovrebbe essere eliminata, in genere attraverso un processo più efficiente, a volte con attrezzature o strutture migliori.
A ogni modo, la variabilità, anche quando è dannosa, è spesso inevitabile. Come vedremo nel prossimo paragrafo, le supply chain si adeguano alla legge dei piccoli numeri. È illusorio pensare che il livello degli stock in negozio possa essere previsto in modo affidabile – da un punto di vista deterministico – anche perché i clienti non sempre sanno cosa acquisteranno. Più in generale, ridurre la variabilità ha sempre un costo (e abbassarla ulteriormente costa ancora di più), mentre la riduzione marginale della variabilità porta solo rendimenti decrescenti. Pertanto, anche quando la variabilità può essere ridotta, molto raramente può essere completamente eliminata, a causa delle implicazioni economiche.
La legge dei piccoli numeri
La legge dei piccoli numeri della supply chain può essere definita come: i piccoli numeri prevalgono ovunque lungo la catena. Questa legge di osservazione è il risultato delle economie di scala e alcune altre forze che guidano la maggior parte degli aspetti strutturali delle supply chain:
- un fornitore che rifornisce decine di migliaia di unità di materiali al giorno ha probabilmente dei quantitativi minimi d'ordine (MOQ) o sconti in base alle quantità acquistate che impediscono di effettuare ordini di acquisto con una frequenza troppo elevata. Il numero di ordini di acquisto trasmessi in un dato giorno a un fornitore raramente rientra nell'ordine delle decine;
- una fabbrica che produce decine di migliaia di unità al giorno è probabile che operi attraverso lotti composti da migliaia di unità. È probabile inoltre che la produzione venga confezionata in pallet. Il numero di lotti in un dato giorno è al massimo un piccolo numero a due cifre;
- un magazzino che riceve decine di migliaia di unità al giorno è probabile che le riceva via camion, con ogni camion che scarica il suo intero carico nel magazzino. Il numero di consegne in un dato giorno raramente supera un numero a due cifre, anche per magazzini molto grandi;
- un negozio di vendita al dettaglio con decine di migliaia di unità in stock è in grado di ripartire il proprio assortimento in migliaia di referenze. Il numero di unità in magazzino per ogni prodotto supera molto raramente un numero a una sola cifra;
- e così via.
Ovviamente, è possibile gonfiare i numeri cambiando l'unità di misura. Ad esempio, se invece di contare il numero di pallet si conta il numero di
grammi di pallet, o il loro valore monetario in centesimi di dollaro, appariranno grandi numeri. Tuttavia, la legge dei piccoli numeri dovrebbe essere interpretata nel senso del contare le cose dal punto di vista della supply chain. Sebbene, in teoria, questo principio possa apparire abbastanza soggettivo, in pratica non è così, a causa delle ovvie e diverse pratiche delle moderne supply chain: pacchetti, scatole, pallet, contenitori, camion…
Questa legge è di grande rilevanza per le previsioni probabilistiche. In primo luogo, essa sottolinea che le previsioni
discrete dominano nelle situazioni relative alla supply chain, ovvero dove il risultato da anticipare (o decidere) è un
intero, piuttosto che un numero frazionato. Le previsioni probabilistiche sono particolarmente indicate per le situazioni
discrete, perché è possibile calcolare una probabilità per ogni risultato discreto. Al contrario, le previsioni deterministiche si scontrano con gli esiti discreti. Ad esempio, cosa significa che le vendite giornaliere attese di un prodotto sono di 1,3 unità? Le unità non sono vendute in modo frazionato. Mentre da questa affermazione si possono dedurre interpretazioni "discrete" più sensate, la sua controparte probabilistica (ad esempio, 27% di probabilità di 0 unità, 35% di probabilità di 1 unità, 23% di 2 unità, ecc.) è molto più diretta, perché tiene conto della natura discreta del fenomeno in questione.
In secondo luogo, anche se le previsioni probabilistiche possono sembrare radicalmente più impegnative in termini di risorse di calcolo, non è esattamente così nella pratica, proprio per la legge dei piccoli numeri. Infatti, tornando al caso delle vendite giornaliere di prodotti di cui si è parlato sopra, non ha senso valutare numericamente le probabilità che la domanda superi le 100 unità in un dato giorno. Queste probabilità possono essere arrotondate a zero o a qualsiasi altro piccolo valore arbitrario. L'impatto sulla precisione numerica del modello della supply chain rimane trascurabile. Come regola generale, è ragionevole considerare che le previsioni probabilistiche richiedono circa tre volte più risorse di calcolo delle loro controparti deterministiche. Tuttavia, nonostante queste spese di gestione, i benefici in termini di performance della supply chain superano di gran lunga il costo delle risorse di calcolo.
Metriche di precisione per le previsioni probabilistiche
Indipendentemente da ciò che accade, una previsione probabilistica ben concepita indica che vi era effettivamente una probabilità non nulla che questo risultato si verificasse. Questo è interessante perché a prima vista può sembrare che le previsioni probabilistiche siano in qualche modo immuni dalla realtà, proprio come un indovino che fa affermazioni profetiche ambigue la cui inesattezza non può essere dimostrata, poiché l'indovino può sempre suggerire una spiegazione a posteriori sul modo corretto di interpretare le profezie. In realtà, esistono molteplici modi per valutare quantitativamente la qualità di una previsione probabilistica. Alcuni di questi modi sono
metriche simili nello spirito alle metriche utilizzate per valutare l'accuratezza delle previsioni deterministiche. Altri modi divergono in modi più estremi e profondi rispetto alla prospettiva deterministica.
Passiamo brevemente in rassegna quattro approcci utili per valutare l'accuratezza di una previsione probabilistica:
- la funzione di perdita pinball
- il continuous ranked probability score (CRPS)
- la probabilità bayesiana
- la prospettiva generativa antagonista
La
funzione di perdita pinball offre una metrica di precisione per una stima quantile da ricavare da una previsione probabilistica. Ad esempio, se si vuole valutare la quantità di stock che ha il 98% di probabilità di essere maggiore o uguale alla domanda del cliente in un negozio per un determinato prodotto, tale quantità può essere ottenuta direttamente da previsioni probabilistiche semplicemente sommando le probabilità a partire da 0 unità di domanda, 1 unità di domanda, etc., fino a quando la probabilità non supera di poco il 98%. La funzione di perdita pinball fornisce una misura diretta della qualità di questa stima parziale della domanda futura. Può essere vista come uno strumento per valutare la qualità di qualsiasi punto della funzione di densità cumulativa della previsione probabilistica.
Il
continuous ranked probability score (CRPS) offre una metrica, che può essere interpretata come la "quantità di spostamento" della massa di probabilità necessaria per spostare tutta la massa di probabilità verso il risultato osservato. È la generalizzazione più diretta dell'errore medio assoluto (MAE) verso una prospettiva probabilistica. Il valore CRPS è omogeneo con l'unità di misura dell'esito stesso. Questa prospettiva può essere generalizzata a spazi metrici arbitrari, invece che a situazioni monodimensionali, attraverso la cosiddetta "teoria del trasporto" e la distanza di Monge-Kantorovich (che va oltre l'oggetto di questo articolo).
La probabilità e l'
entropia incrociata adottano la prospettiva bayesiana del
minimo grado di sorpresa: più alta è la probabilità dei risultati osservati, meglio è. Per esempio, abbiamo due modelli probabilistici A e B: il modello A afferma che la probabilità di osservare 0 unità di domanda è del 50% per un dato giorno; il modello B afferma che la probabilità di osservare 0 unità di domanda è dell'1% per un dato giorno. Osserviamo la domanda in 3 giorni e otteniamo le seguenti osservazioni: 0, 0, 1. Il modello A aveva circa il 10% di probabilità di generare queste osservazioni, mentre il modello B aveva una probabilità di circa lo 0,01% soltanto. Quindi, il modello B ha molte meno probabilità di essere il modello corretto rispetto al modello A. La probabilità si discosta dalla prospettiva deterministica di avere un criterio significativo
assoluto per valutare i modelli. Al contrario, fornisce un meccanismo per
confrontare i modelli; tuttavia, a livello numerico, non può essere usato se non per confrontare i modelli.
La prospettiva generativa antagonista è la prospettiva più moderna in materia (Ian Goodfellow et al., 2014). In sostanza, questa prospettiva afferma che il modello probabilistico "migliore" è quello che può essere utilizzato per generare risultati in stile Monte Carlo, indistinguibili da quelli reali. Ad esempio, se considerassimo lo storico delle transazioni di un ipermercato, potremmo troncare questa storia in un punto arbitrario del passato e utilizzare il modello probabilistico per generare transazioni false ma realistiche. Il modello sarebbe considerato "perfetto" se fosse impossibile, attraverso l'analisi statistica, recuperare il punto nel tempo in cui il set di dati passa dai dati "reali" ai dati "falsi". L'idea centrale dell'approccio generativo della rete antagonista è quello di "imparare" le metriche che aggravano i difetti di qualsiasi modello probabilistico. Piuttosto che concentrarsi su una particolare metrica, questa prospettiva sfrutta ricorsivamente le tecniche di machine learning per "imparare" le metriche stesse.
La ricerca di metodi per migliorare la qualità delle previsioni probabilistiche è un’area ancora in corso di esplorazione. Non c'è una chiara delimitazione tra le domande: "come produrre una previsione più attendibile?" e "come si determina se una previsione è più attendibile?". I recenti studi hanno notevolmente offuscato le linee di demarcazione tra le due domande, ed è probabile che le prossime scoperte implicheranno ulteriori cambiamenti nel modo stesso in cui le previsioni probabilistiche vengono considerate.
Probabilità sempre più piccole e funzione di verosimiglianza
Le probabilità molto piccole sorgono naturalmente quando si guarda ad una situazione multidimensionale attraverso il prisma delle previsioni probabilistiche. Queste piccole probabilità sono problematiche perché i computer non elaborano numeri indefinitamente precisi. I valori di probabilità grezzi sono spesso piccolissimi, nel senso che vengono arrotondati a zero a causa dei limiti della precisione numerica. La soluzione a questo problema non è l'aggiornamento del software a calcoli di precisione arbitraria – che è molto inefficiente in termini di risorse di calcolo – ma l'utilizzo del "log-trick", che trasforma le moltiplicazioni in addizioni. Questo trucco è utilizzato – in un modo o nell'altro – praticamente da tutti i software che lavorano con le previsioni probabilistiche.
Supponiamo di avere $X_1$, $X_2$, …, $X_n$ variabili casuali che rappresentano la domanda giornaliera per tutti i $n$ diversi prodotti venduti all'interno di un determinato negozio. Lasciamo che $\hat{x}_1$, $\hat{x}_2$, .., $\hat{x}_n$ corrispondano alla domanda empirica osservata alla fine della giornata per ogni prodotto. Per il primo prodotto – regolato da$X_1$ - la probabilità di osservare $\hat{x}_1$ è scritta $P(X_1 = \hat{x}_1)$. Ora, supponiamo in modo un po' improprio, ma per chiarezza, che tutti i prodotti siano assolutamente indipendenti dalla domanda. La probabilità per l'evento congiunto di osservare $\hat{x}_1$, $\hat{x}_2$, .., $\hat{x}_n$ è:
$$P(X_1 = \hat{x}_1 \dots X_n = \hat{x}_n) = \prod_{k=1}^n P(X_k = \hat{x}_k)$$
Se $P(X_k = \hat{x}_k) \approx \frac{1}{2}$ (approssimazione lorda) e $n = 10000$ allora la probabilità congiunta di cui sopra è dell'ordine di $\frac{1}{2^{10000}} \approx 5 * 10^{-3011}$, che è un valore molto piccolo. Questo valore scende al di sotto del più piccolo numero rappresentabile, anche considerando i numeri a virgola mobile a 64 bit che sono generalmente utilizzati per il calcolo scientifico.
Il
log-trick consiste nel lavorare con il logaritmo dell'espressione, ovvero:
$$\ln P(X_1 = \hat{x}_1 \dots X_n = \hat{x}_n) = \sum_{k=1}^n \ln P(X_k = \hat{x}_k)$$
Il logaritmo trasforma la serie di moltiplicazioni in una serie di addizioni, che si rivelano essere molto più stabili, dal punto di vista numerico, di una serie di moltiplicazioni.
L'uso del
log-trick è frequente quando si ha a che fare con previsioni probabilistiche. La funzione di verosimiglianza è letteralmente il logaritmo della probabilità (introdotta in precedenza) proprio perché la probabilità grezza sarebbe, in generale, numericamente non rappresentabile considerando i comuni tipi di numeri in virgola mobile.
Approcci algoritmici per le previsioni probabilistiche
La questione della previsione probabilistica guidata dal computer è vasta quasi quanto il campo del machine learning stesso. Le eventuali delimitazioni tra i due campi sono per lo più una questione di scelte soggettive. Tuttavia, questa sezione presenta una lista piuttosto selettiva di approcci algoritmici che possono essere utilizzati per ottenere previsioni probabilistiche.
All'inizio del XX secolo, e probabilmente già alla fine del XIX secolo, è emersa l'idea delle
scorte di sicurezza, secondo cui l'incertezza della domanda è modellata seguendo una distribuzione normale. Poiché le tabelle precalcolate della distribuzione normale erano già state stabilite per altre scienze (in particolare per la fisica), l'applicazione della scorta di sicurezza richiedeva solo la moltiplicazione di un livello di domanda per un coefficiente di "scorta di sicurezza", appunto, ricavato da una tabella preesistente. A titolo di aneddoto, molti libri di testo sulla supply chain pubblicati fino agli anni '90 contenevano ancora nelle loro appendici queste tabelle della distribuzione normale. Sfortunatamente, il principale svantaggio di questo approccio è che le distribuzioni
normali non sono una proposta ragionevole per le supply chain. In primo luogo, per quanto riguarda le supply chain, è lecito supporre che
nulla sia mai
normalmente distribuito. In secondo luogo, la distribuzione normale è una distribuzione continua, il che è in contrasto con la natura discreta degli eventi della supply chain (si veda sopra la "Legge dei piccoli numeri"). Pertanto, mentre tecnicamente le "scorte di sicurezza" hanno una componente probabilistica, la metodologia di base e le ricette numeriche sono saldamente orientate verso una prospettiva deterministica. Questo approccio è qui elencato per chiarezza.
In rapida ascesa verso i primi anni 2000, i metodi di apprendimento collettivo – i cui rappresentanti più noti sono probabilmente le foreste casuali e gli alberi decisionali – sono relativamente semplici da estendere dalle loro origini deterministiche alla prospettiva probabilistica. L'idea chiave alla base dell'apprendimento collettivo è quella di combinare numerosi e deboli predittori deterministici, come gli alberi decisionali, in un predittore deterministico superiore. È possibile, tuttavia, regolare il processo di combinazione per ottenere delle probabilità piuttosto che un singolo aggregato, trasformando così il metodo di apprendimento collettivo in un metodo di previsione probabilistica. Questi metodi sono non parametrici e sono in grado di adattarsi a distribuzioni a coda pesante e/o multimodali, che si trovano comunemente nella supply chain. Questi metodi tendono ad avere due notevoli svantaggi. In primo luogo, per costruzione, la funzione di probabilità di densità prodotta da questa classe di modelli tende a includere molti zeri, il che impedisce qualsiasi tentativo di sfruttare la metrica di verosimiglianza. Più in generale, questi modelli non si adattano alla prospettiva bayesiana, poiché le osservazioni più recenti sono spesso dichiarate "impossibili" (cioè, aventi zero probabilità) dal modello. Questo problema, tuttavia, può essere risolto con metodi di regolarizzazione[1]. In secondo luogo, i modelli tendono a essere grandi quanto una frazione considerevole del dataset di input, e l'operazione di "previsione" tende a essere tanto costosa dal punto di vista computazionale quanto l'operazione di "apprendimento".
I metodi iperparametrici conosciuti collettivamente sotto il nome di "deep learning", emersi in modo esplosivo tra il 2000 e il 2010, erano, per puro caso, quasi probabilistici. Infatti, mentre la stragrande maggioranza degli ambiti in cui il deep learning funziona davvero (ad esempio la classificazione delle immagini) si concentrano solo su previsioni deterministiche, si scopre che la metrica dell'entropia incrociata – una variante della funzione di verosimiglianza discussa sopra – presenta gradienti molto ripidi, che spesso ben si adattano alla discesa stocastica del gradiente (in inglese
Stochastic Gradient Descent o SGD), che si trova al centro dei metodi di deep learning. Pertanto, i modelli di deep learning si rivelano essere progettati come probabilistici, non perché le probabilità fossero interessanti, ma perché la discesa del gradiente converge più velocemente quando la funzione di perdita riflette una previsione probabilistica. Così, per quanto riguarda il deep learning, la supply chain si distingue per il suo interesse per l'effettivo output probabilistico del modello di deep learning, mentre la maggior parte degli altri casi d'uso fa collassare la distribuzione delle probabilità alla sua media, mediana o moda. La
Mixture Density Networks è un tipo di rete di deep learning orientata all'apprendimento di distribuzioni di probabilità complesse. Il risultato stesso è una distribuzione parametrica, eventualmente composta da distribuzioni gaussiane. Tuttavia, a differenza delle "scorte di sicurezza", una miscela di distribuzioni gaussiane può, in pratica, riflettere i comportamenti della coda pesante che si osservano nelle supply chain. Va notato che, anche se i metodi di deep learning sono spesso considerati all'avanguardia, raggiungere la stabilità numerica, specialmente con miscele di densità in mezzo, rimane un'"arte oscura".
La programmazione differenziabile è una discendente del deep learning, che ha guadagnato popolarità intorno al 2010. Ha molti attributi tecnici in comune con il deep learning, ma differisce significativamente nell'approccio. Mentre il deep learning si concentra sull'apprendimento di funzioni arbitrariamente complesse (ad es. giocare a
go) impilando un gran numero di funzioni semplici (ad es. livelli convoluzionali), la programmazione differenziabile si concentra sulla struttura fine del processo di apprendimento. La struttura più fine e più espressiva può, letteralmente, essere formattata come programma, che coinvolge rami, loop, chiamate a funzioni, ecc. La programmazione differenziabile è di grande interesse per la supply chain, perché i problemi tendono a presentarsi in modi altamente strutturati, e tali strutture sono note agli esperti[2]. Ad esempio, le vendite di una data camicia possono essere cannibalizzate da quelle di un'altra camicia di un colore diverso, ma non saranno cannibalizzate dalle vendite di una camicia di tre taglie in più. Questa conoscenza preliminare strutturale è la chiave per ottenere un'alta efficienza dei dati. Infatti, dal punto di vista della supply chain, la quantità di dati tende a essere molto limitata (si veda il paragrafo dedicato alla legge dei piccoli numeri). Quindi, "inquadrare" strutturalmente il problema aiuta a garantire che i modelli statistici desiderati siano appresi, anche quando i dati sono limitati. La conoscenza preliminare strutturale (o priori strutturali) aiuta anche ad affrontare i problemi di stabilità numerica. Rispetto ai metodi di apprendimento collettivo, i priori strutturali sono tendenzialmente meno dispendiosi in termini di tempo rispetto alla progettazione di funzioni e più semplici da mantenere. Lo svantaggio è che la programmazione differenziabile rimane a oggi una prospettiva relativamente recente.
Il metodo Monte Carlo (1930-1940) può essere utilizzato per approcciare le previsioni probabilistiche da un'angolazione diversa. I modelli finora discussi forniscono funzioni di densità di probabilità esplicite (dall’inglese "Probability Density Functions", o PDF). Da una prospettiva Monte Carlo, tuttavia, un modello può essere sostituito da un generatore – o sampler – che genera casualmente i possibili risultati (talvolta chiamati "deviazioni"). Le PDF possono essere recuperate facendo la media dei risultati del generatore, anche se tali funzioni sono spesso trascurate per ridurre i requisiti di risorse computazionali. In effetti, il generatore è spesso progettato per essere molto più compatto, in termini di dati, delle PDF che rappresenta. La maggior parte dei metodi di machine learning – compresi quelli elencati sopra per gestire direttamente le previsioni probabilistiche – possono contribuire all'apprendimento di un generatore. I generatori possono assumere la forma di modelli parametrici a bassa dimensione (ad esempio modelli di spazio di stato) o di modelli iperparametrici (ad esempio i modelli LSTM e GRU usati nel deep learning). I metodi di apprendimento collettivo sono raramente utilizzati per supportare i processi generativi a causa degli alti costi computazionali delle loro operazioni di "previsione", che sono altamente richieste dal metodo Monte Carlo.
Lavorare con le previsioni probabilistiche
Per ricavare intuizioni e decisioni utili dalle previsioni probabilistiche, sono necessari strumenti numerici specializzati. A differenza delle previsioni deterministiche, dove troviamo dei numeri semplici, le previsioni stesse sono o esplicite (funzioni di densità di probabilità), o generatori di Monte Carlo. La qualità degli strumenti probabilistici è, in pratica, importante quanto la qualità delle previsioni probabilistiche. Senza questi strumenti, l'utilizzo di previsioni probabilistiche si trasforma in un processo deterministico (per saperne di più, si veda la sezione "Antipattern" più in basso).
Per esempio, questi strumenti dovrebbe essere in grado di eseguire compiti come:
- combinare il tempo di produzione con il tempo di trasporto, entrambi incerti, per ottenere il tempo di trasporto "totale", anch'esso incerto;
- combinare la domanda con il lead time, entrambi incerti, per ottenere la domanda "totale", incerta, che deve essere soddisfatta dallo stock che sta per essere ordinato;
- combinare i resi con la data di arrivo dell'ordine del fornitore in transito, entrambi incerti, per ottenere il lead time incerto del cliente;
- aumentare la previsione della domanda, prodotta con un metodo statistico, con un rischio di coda derivante manualmente da una comprensione di alto livello di un contesto non riflesso nei dati storici, come una pandemia;
- combinare la domanda incerta con uno stato incerto degli stock in relazione alla data di scadenza (vendita al dettaglio di prodotti alimentari), per ottenere la quantità incerta di avanzi di stock a fine giornata;
- e così via.
Una volta che tutte le previsioni probabilistiche – non solo quelle della domanda – sono correttamente combinate, si dovrebbe procedere all'ottimizzazione delle decisioni relative alla supply chain. Ciò comporta una prospettiva probabilistica sui vincoli, così come la funzione score. Tuttavia, illustrare questo aspetto va oltre lo scopo del presente articolo.
Ci sono due ampie tipologie di strumenti per lavorare con le previsioni probabilistiche: il primo sono le algebre di variabili casuali, il secondo è la programmazione probabilistica. Queste due tue tipologie si completano a vicenda, in quanto non hanno lo stesso mix di pro e contro.
Un'algebra di variabili casuali lavora in genere su funzioni di densità di probabilità esplicite. L'algebra supporta le consuete operazioni aritmetiche (addizione, sottrazione, moltiplicazione, ecc.) ma trasposte alle loro controparti probabilistiche, trattando spesso le variabili casuali come statisticamente indipendenti. L'algebra fornisce una stabilità numerica che è quasi alla pari con la sua controparte deterministica (cioè i numeri semplici). Tutti i risultati intermedi possono essere conservati per un uso successivo, il che si rivela molto utile per organizzare e risolvere i problemi di pipeline di dati. Il rovescio della medaglia è che l'espressività di queste algebre tende a essere limitata, in quanto non è generalmente possibile esprimere tutte le sottili dipendenze condizionali che esistono tra le variabili casuali.
La programmazione probabilistica adotta una prospettiva Monte Carlo per affrontare il problema. La logica è scritta una volta sola, in genere attenendosi a una prospettiva interamente deterministica, ma viene eseguita più volte attraverso lo strumento (cioè il processo Monte Carlo) per raccogliere le statistiche desiderate. La massima espressività si ottiene attraverso costrutti "programmatici", che permettono di modellare dipendenze arbitrarie e complesse tra variabili casuali. Anche la scrittura della logica stessa attraverso la programmazione probabilistica tende ad essere leggermente più semplice rispetto ad un'algebra di variabili casuali, poiché la logica include solo numeri regolari. Uno svantaggio è il costante compromesso tra la stabilità numerica (più iterazioni producono una migliore precisione) e le risorse di calcolo (più iterazioni hanno un costo maggiore). Inoltre, i risultati intermedi non sono in genere facilmente accessibili, in quanto la loro esistenza è solo transitoria, proprio per alleviare la pressione sulle risorse di calcolo…
Recenti lavori di approfondimento indicano che esistono anche altri approcci al di là dei due presentati sopra. Per esempio, gli autocodificatori variazionali offrono prospettive per eseguire operazioni su
spazi latenti con ottimi risultati mentre si cercano trasformazioni molto complesse nei dati (ad esempio, rimuovere automaticamente gli occhiali da un ritratto fotografico). Sebbene questi approcci siano concettualmente molto affascinanti, non hanno mostrato, fino a oggi, molta rilevanza pratica nel risolvere i problemi della supply chain.
Rappresentazione delle previsioni probabilistiche
Il modo più semplice per visualizzare una distribuzione discreta delle probabilità è un istogramma, dove l'asse verticale indica la probabilità e l'asse orizzontale il valore della variabile casuale di interesse. Ad esempio, una previsione probabilistica di un lead time può essere rappresentata in questo modo:
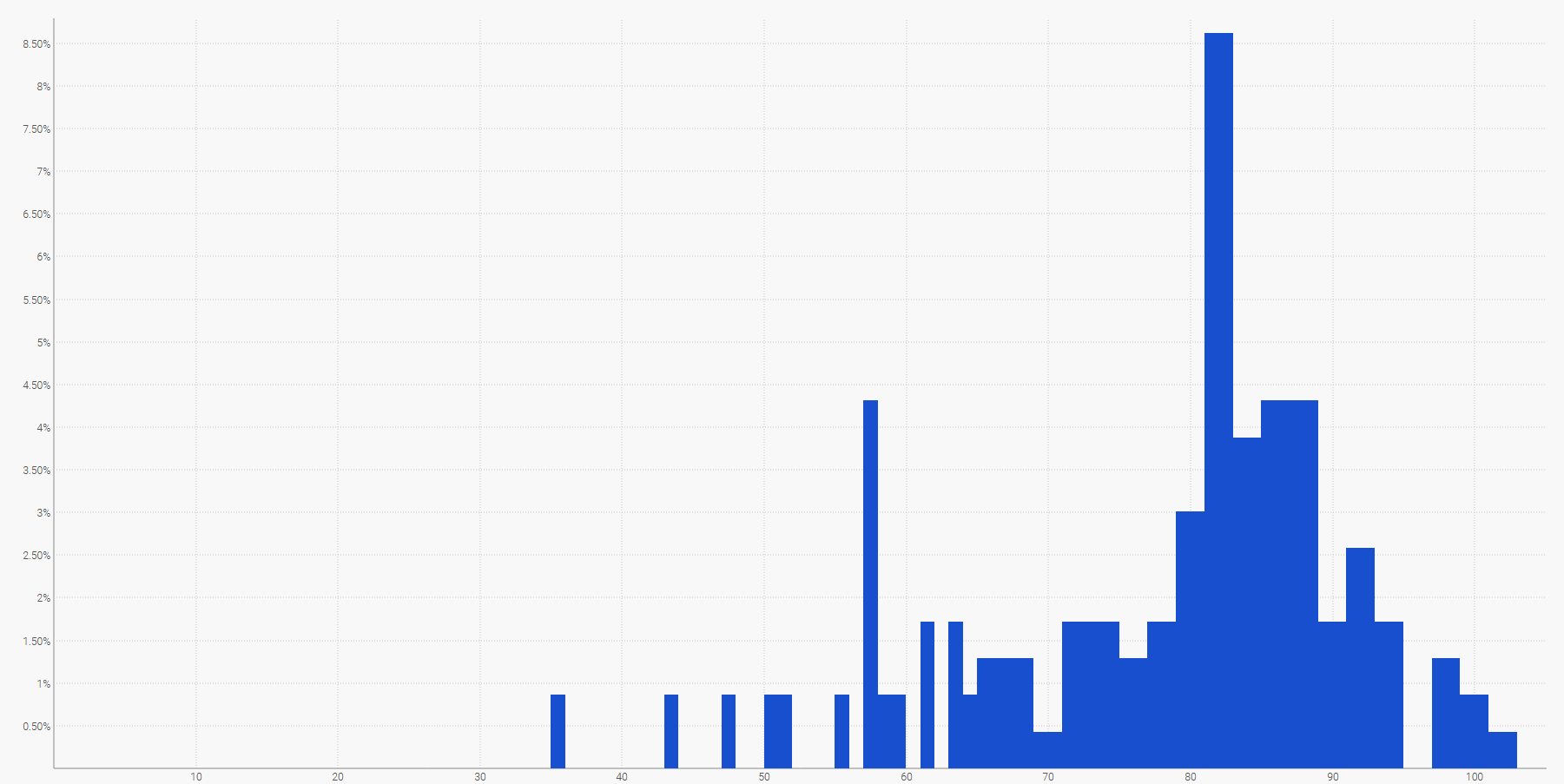
Una previsione probabilistica del lead time raffigurata tramite un istogramma.Anche la domanda futura, sommata in un determinato periodo di tempo, può essere rappresentata da un istogramma. Più in generale, l'istogramma è adatto a tutte le variabili casuali unidimensionali su $\mathbb{Z}$, l'insieme dei numeri interi relativi.
La rappresentazione dell'equivalente probabilistico di una serie temporale equidistante – ovvero una quantità che varia su periodi di tempo discreti di uguale lunghezza – è già molto più complessa. Infatti, a differenza della variabile casuale unidimensionale, non esiste una visualizzazione canonica di tale distribuzione. È importante considerare che i periodi non possono essere assunti come indipendenti. Pertanto, sebbene sia possibile rappresentare una serie temporale "probabilistica" allineando una serie di istogrammi, uno per periodo, questa rappresentazione non raffigurerebbe a dovere il modo in cui gli eventi si svolgono in una supply chain.
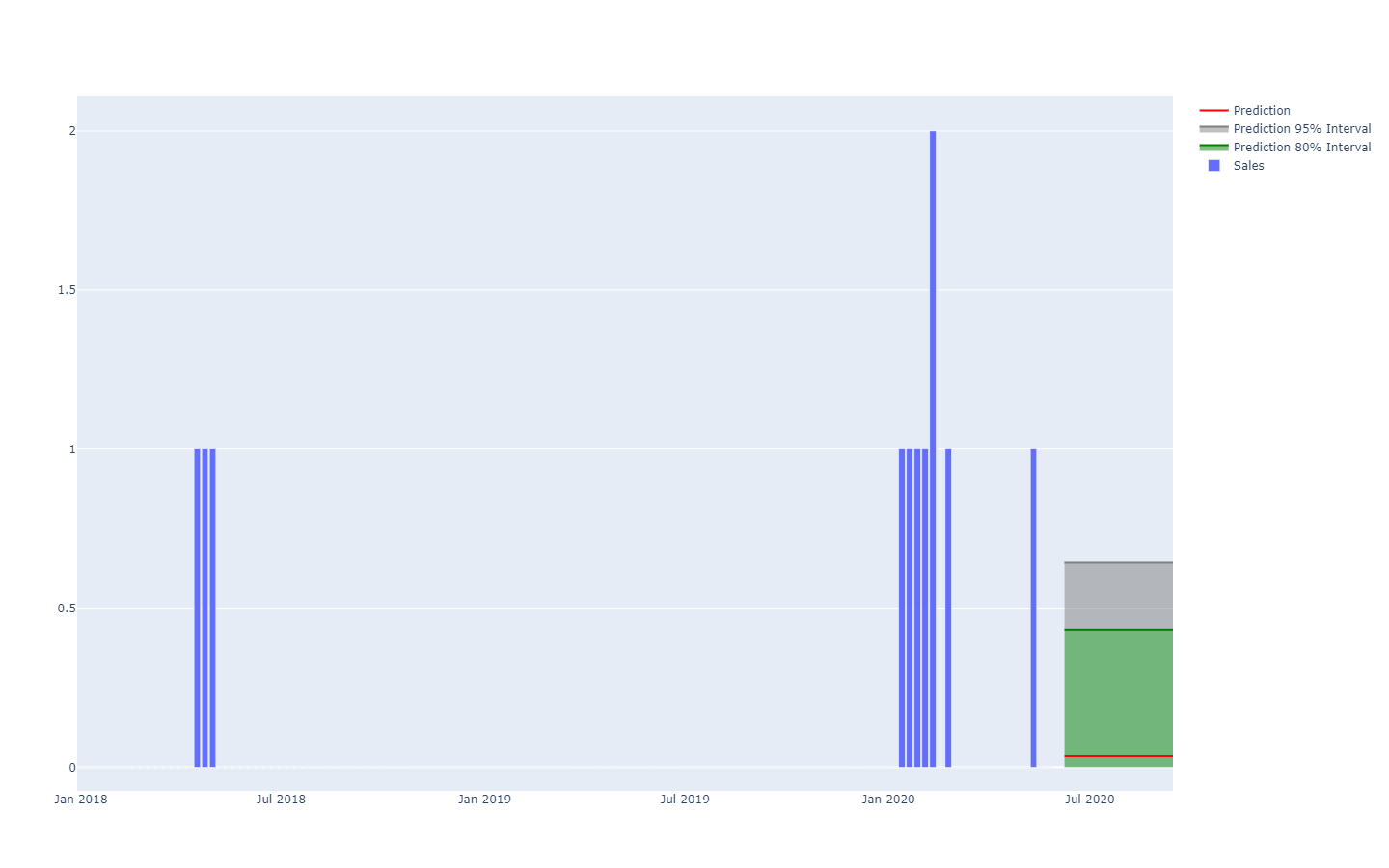
Una previsione probabilistica della domanda rappresentata tramite soglie quantili.Ad esempio, non è improbabile che un prodotto appena lanciato abbia buone prestazioni e raggiunga elevati volumi di vendita (un successo). Non è nemmeno improbabile che lo stesso prodotto appena lanciato non abbia successo e registri bassi volumi di vendita (un insuccesso). Tuttavia, è molto improbabile che ci siano ampie oscillazioni tra alti e bassi livelli di vendite giornaliere.
Gli intervalli di previsione, che si riscontrano spesso nella letteratura sulla supply chain, sono in qualche modo fuorvianti. Essi tendono a enfatizzare situazioni a bassa incertezza che non sono rappresentative delle situazioni reali della supply chain.
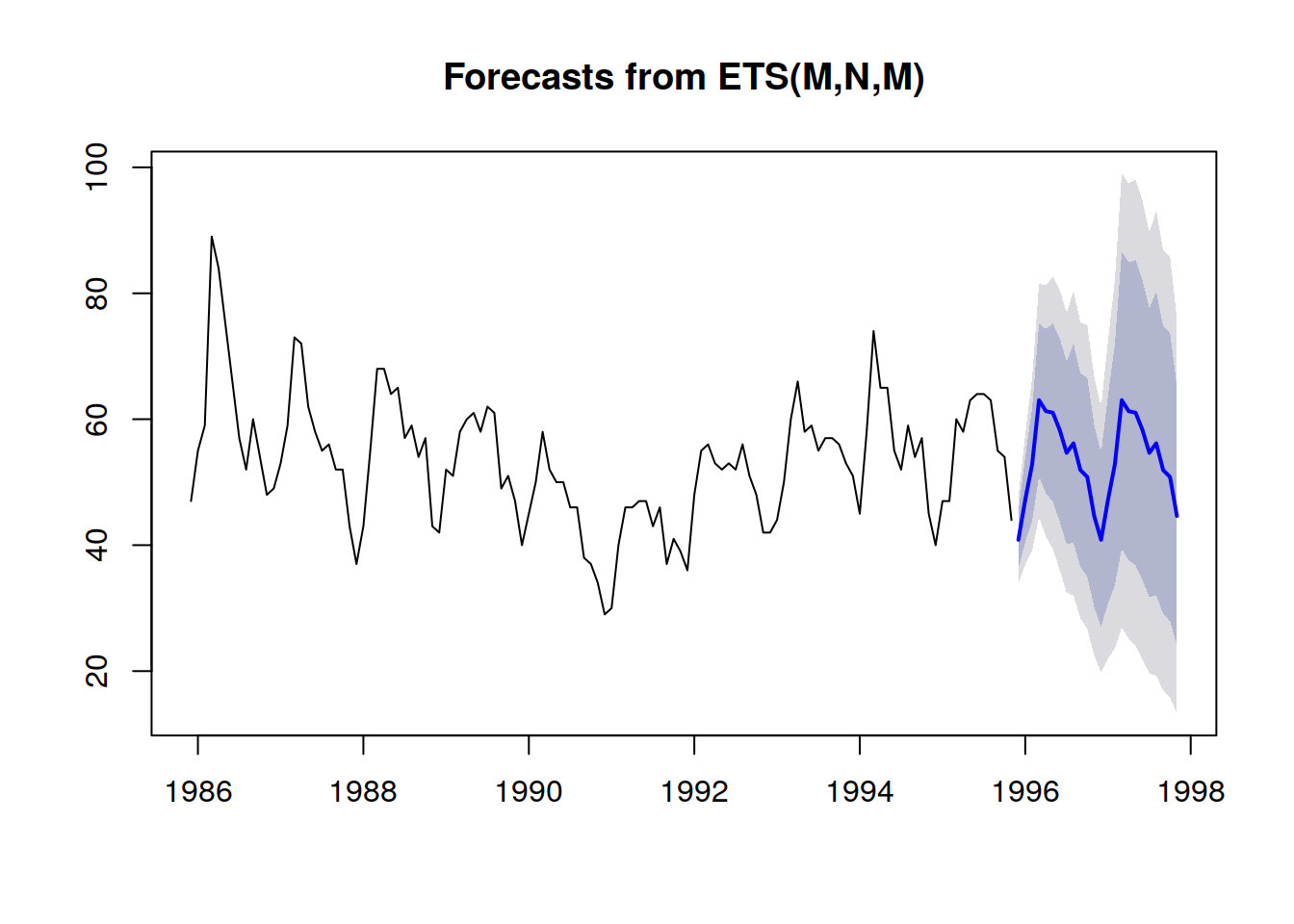
Estratto da Visualization of probabilistic forecasts, di Rob J Hyndman, 21 Novembre 2014Si noti come messi insieme con uno schema di colorazione per delineare specifiche soglie quantili, questi intervalli di predizione corrispondono esattamente alle distribuzioni di probabilità.
Una migliore rappresentazione – che non migliora le forti dipendenze inter-periodo – è quella di guardare i valori
cumulativi nel tempo, prendendo i quantili di questi, e poi differenziandoli per ottenere gli incrementi per periodo (si veda l'illustrazione di una previsione probabilistica all'inizio del presente articolo). La visualizzazione è la stessa, ma la
semantica sottostante è diversa. Ora esaminiamo i quantili rispetto agli
scenari, delineando gli scenari estremamente favorevoli (o sfavorevoli).
Gli antipattern delle previsioni probabilistiche
Le previsioni probabilistiche mettono in discussione il modo in cui molte persone pensano "intuitivamente" al futuro. In questa sezione, rivediamo alcuni degli aspetti più fraintesi delle previsioni probabilistiche.
Non esistono eventi "imprevedibili"
Dal punto di vista deterministico, prevedere il risultato di una lotteria è impossibile, in quanto le probabilità di vincerla sono "una su un milione". Tuttavia, da un punto di vista probabilistico, il problema è banale: ogni biglietto ha "una probabilità di vincita su un milione". L'altissima varianza del risultato non deve essere confusa con una certa "inconoscibilità" del fenomeno stesso, che può essere perfettamente compreso, come nel caso di una lotteria. La previsione probabilistica mira a quantificare e strutturare la varianza, non a eliminarla.
Non esistono distribuzioni "normali"
Le distribuzioni normali, note anche come gaussiane, sono onnipresenti sia nella supply chain che nei libri di fisica. Eppure, quando si tratta di questioni umane, quasi nulla è distribuito "normalmente". Le distribuzioni normali, per design, rendono le grandi deviazioni (rispetto alle deviazioni medie) estremamente rare, al punto da essere escluse dal modello - ovvero le probabilità sono inferiori a una su un miliardo. La domanda, il lead time, i rendimenti sono esempi di modelli che non mostrano una distribuzione normale. L'unico aspetto positivo delle distribuzioni normali è che sono adatte ad evocare esercizi da manuale per gli studenti, in quanto si prestano a soluzioni analitiche esplicite.
Scegliere le probabilità
Di fronte a una distribuzione di probabilità, si è tentati di scegliere un punto della distribuzione, generalmente la media o la mediana, e procedere in base a questo numero. Questo processo va contro l'essenza stessa dell'aspetto probabilistico della previsione. Le probabilità non dovrebbero essere ridotte a una stima di un singolo punto perché, indipendentemente dal punto scelto, questo processo comporta una massiccia perdita di informazioni. Pertanto, anche se può essere un po' inquietante, le probabilità sono destinate a essere conservate come tali il più a lungo possibile. Il punto di svolta è generalmente la decisione finale della supply chain, che massimizza i rendimenti, pur affrontando futuri incerti.
Rimozione degli outlier statistici
La maggior parte dei metodi numerici classici – saldamente radicati nella prospettiva deterministica delle previsioni (ad esempio, le medie mobili) – si comportano malamente quando incontrano degli outlier statistici. Di conseguenza, molte aziende stabiliscono processi per "pulire" manualmente lo storico dei dati da questi
outlier. Tuttavia, la necessità di un tale processo di pulizia non fa che evidenziare le carenze di tali metodi numerici. Gli outlier statistici sono, infatti, un ingrediente essenziale della previsione probabilistica, in quanto aiutano ad avere un'idea migliore di ciò che sta accadendo nella coda della distribuzione. In altre parole, gli outlier sono la chiave per quantificare la probabilità di incontrare ulteriori
outlier.
Armarsi con gli strumenti sbagliati
Per manipolare le distribuzioni di probabilità sono necessarie attrezzature specifiche. La produzione di una previsione probabilistica è solo un passo tra tanti per fornire un valore reale all'azienda. Molti professionisti della supply chain finiscono per ignorare le previsioni probabilistiche per la mancanza di strumenti adatti a farne uso. Molti venditori di software si sono uniti al movimento e sostengono di supportare le "previsioni probabilistiche" (insieme all' "IA" e alla "blockchain"), ma in realtà non sono riusciti a fare più di un'implementazione cosmetica di alcuni modelli probabilistici (si veda la sezione precedente). L'esposizione di un modello di previsione probabilistica non vale quasi nulla senza l'ampia strumentazione necessaria per sfruttarne i risultati numerici.
Note
[1]: la funzione
smooth() presente in Envision è utile per regolarizzare le variabili casuali attraverso un processo di campionamento discreto.
[2]: la conoscenza preliminare della struttura del problema non deve essere confusa con la conoscenza preliminare della soluzione stessa. I "sistemi esperti" che sono stati sperimentati negli anni '50 come un insieme di regole scritte a mano hanno fallito perché gli esperti non sono riusciti a mettere in pratica, tramite formule numeriche, la loro intuizione. I priori strutturali, utilizzati nella programmazione differenziabile delineano il principio, non i dettagli, della soluzione.


