di Joannès Vermorel, dicembre 2007 (ultima revisione: gennaio 2012)Le scorte di sicurezza sono un metodo di ottimizzazione dell'inventario che indica quanto inventario deve essere conservato rispetto alla domanda prevista per raggiungere un determinato livello di servizio. Le scorte extra agiscono come un cuscinetto "di sicurezza" (da qui il nome) per proteggere l'azienda dalle prevedibili fluttuazioni future. La formula delle scorte di sicurezza dipende sia dalla domanda futura che si prevede, sia dai tempi di consegna e si presume che l'incertezza sia normalmente distribuita per entrambi i fattori. Questa formula è presente nella maggior parte dei sistemi di gestione delle scorte, compresi i più importanti ERP e MRP.
Aggiornamento (luglio 2020): l'approccio descritto qui sotto è "da manuale" e si rivela, inoltre, estremamente disfunzionale. Nello specifico, né la domanda né i tempi di consegna futuri sono normalmente distribuiti (secondo i principi di Gauss). Inoltre, l'intera prospettiva non tiene conto del fatto che tutte le SKU che possono essere ordinate o prodotte dall'azienda competono per le stesse risorse.
Pubblico di destinazione: Questo documento è destinato principalmente ai professionisti della logistica, sia nel settore della distribuzione che nel settore della produzione, ed è utile agli editor di software di contabilità, ERP o eCommerce che volessero introdurre nelle loro applicazioni delle funzionalità per la gestione delle scorte. Consigliamo vivamente di non utilizzare alcun modello di scorte di sicurezza per quanto riguarda le supply chain reali)).
Abbiamo tentato di ridurre al minimo le spiegazioni matematiche; non abbiamo potuto, però, eliminare tutte le formule, dal momento che lo scopo di questo documento è quello di fornire una guida pratica al calcolo della scorta di sicurezza.
Scarica: calculate-safety-stocks.xls (Foglio di calcolo di Microsoft Excel)
Introduzione
La gestione dell'inventario è un
compromesso finanziario tra i costi di gestione del magazzino e i costi di una rottura di stock. Maggiori sono le scorte, maggiore sarà il capitale operativo necessario, maggiore sarà il deprezzamento dei prodotti. D'altra parte, se le scorte non sono sufficienti, il rischio è quello di incorrere in una rottura di stock, di perdere delle potenziali vendite, o addirittura di bloccare l'intero processo di produzione.
Il livello delle scorte dipende sostanzialmente da due fattori:
- la domanda nel lead time, ossia la quantità di articoli che verranno consumati o acquistati;
- il lead time, ossia il periodo di tempo che trascorre tra la decisione di ordinare un articolo e l'effettiva disponibilità dell'articolo.
Questi fattori, poi, sono soggetti a variazioni, in particolare a:
- variazioni nella domanda: il comportamento del cliente può evolvere in maniera spesso imprevedibile;
- variazioni nel lead time: fornitori o trasportatori possono trovarsi ad affrontare difficoltà impreviste.
Scegliere il livello della scorta di sicurezza equivale a trovare un compromesso tra questi costi, tenendo conto di tutte le variabili possibili.
L'equilibrio tra costi di gestione del magazzino e costi di rottura di stock varia a seconda del settore industriale in cui opera l'azienda. A questo punto, riteniamo opportuno, invece che considerare direttamente i costi, introdurre il concetto classico di
livello di servizio.
Il
livello di servizio esprime la probabilità che un determinato livello di scorta di sicurezza non porti a una rottura di stock. Naturalmente, se aumentiamo la scorta di sicurezza, aumenterà anche il livello di servizio. In caso di scorte di sicurezza considerevoli, il livello di servizio tende al 100% (ossia, a una probabilità nulla di incorrere in una rottura di stock).
Scegliere il livello di servizio, ossia la probabilità accettabile di incorrere in una rottura di stock, sarà argomento di un'altra guida, in cui spiegheremo come
calcolare un livello di servizio ottimale.
Modello di riapprovvigionamento
Il punto di riordino è il livello di scorte una volta raggiunto il quale si rende necessario creare un nuovo ordine. Se non ci sono elementi di incertezza (se, cioè, la domanda futura è perfettamente nota e la consegna è assolutamente affidabile), il punto di riordino sarà pari alla
domanda nel lead time, ossia la domanda totale prevista per il periodo di lead time.
Nella pratica, a causa dei diversi elementi di incertezza, abbiamo la formula
punto di riordino = domanda nel lead time + scorta di sicurezzaPoniamo che nelle previsioni non venga introdotto un bias, o errore sistematico: in questo caso, una scorta di sicurezza pari a zero porterebbe a un livello di servizio del 50%. Infatti, le previsioni così ottenute indicano che è più probabile che la domanda futura sia superiore o inferiore alla domanda nel lead time (teniamo sempre a mente che la domanda nel lead time è il risultato di una previsione).
Attenzione: le previsioni possono non presentare alcun bias e non essere comunque esatte. Il bias è un errore sistematico introdotto nel modello previsionale (es. sovrastimare sempre la domanda del 20%).
Distribuzione normale dell'errore
A questo punto, abbiamo bisogno di un modo per indicare l'incertezza nella domanda nel lead time. Qui di seguito, ipotizzeremo che l'errore sia distribuito normalmente, come nell'immagine qui sotto.
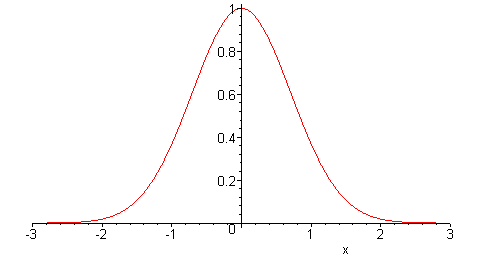 Osservazioni statistiche
Osservazioni statistiche: l'ipotesi di una distribuzione normale non è totalmente arbitraria. In alcune condizioni, gli stimatori statistici convergono verso una distribuzione normale, come dimostra il teorema del limite centrale. Queste considerazioni, tuttavia, trascendono l'obiettivo di questa guida.
La distribuzione normale è definita da due parametri soltanto: la media e la varianza. Poiché partiamo dal presupposto che non venga introdotto un bias nella previsione,
ipotizziamo che la media della distribuzione degli errori sia pari a zero, che non vuol dire che gli errori siano pari a zero.
Determinare la varianza degli errori in una previsione è un compito ben più delicato. Lokad, così come molti altri strumenti di previsione, offre, oltre alle previsioni, delle
stime MAPE (Mean Absolute Percentage Error). Per completare la nostra spiegazione, vedremo come delle semplici euristiche possono contribuire a risolvere il problema.
In particolare, la
varianza all'interno dei dati storici può essere una valida euristica per stimare la varianza degli errori di previsione. David Piasecki suggerisce addirittura di sostituire, nell'espressione della varianza, la domanda nel lead time con la domanda prevista, quindi
σ2 = E[ (yt - y')2 ]
dove
E è l'operatore
medio,
yt è la domanda storica per il periodo
t (di solito la quantità di vendite) e
y' è la domanda prevista.
L'idea alla base di questa ipotesi è che l'errore di previsione è molto spesso legato alla quantità di variazioni attese:
maggiori sono le variazioni future, maggiore sarà l'errore nelle previsioni.
Per calcolare la varianza dell'errore, in realtà, bisognerebbe tenere in conto anche altri fattori, di cui parleremo più diffusamente nei prossimi paragrafi.
Come calcolare la scorta di sicurezza
Una volta determinate media e varianza, e quindi una volta nota la distribuzione dell'errore, dobbiamo calcolare il livello di errore
accettabile all'interno di questa distribuzione. A tal proposito, abbiamo introdotto prima il concetto di livello di servizio, espresso in percentuale.
Note: il lead time che abbiamo ipotizzato è
statico. Un approccio simile, però, potrà essere usato anche in caso di lead time variabile. A questo riguardo, vedere anche (in inglese):
Per trasformare il livello di servizio in un
livello di errore, noto anche come
fattore di servizio, dobbiamo ricorrere alla
distribuzione normale inversa (
NORMSINV per la funzione Excel corrispondente). Il procedimento non è così complicato come potrebbe sembrare. Suggeriamo di dare un'occhiata a questa
applet di distribuzione normale per avere un'idea più chiara. Come si può vedere, la funzione cumulativa trasforma la percentuale in una
area sotto la curva, in cui la soglia dell'asse X corrisponde al valore del fattore di servizio.
Intuitivamente, possiamo calcolare
scorta di sicurezza = deviazione standard dell'errore * fattore di servizioIn maniera più formale, sia
S la scorta di sicurezza. Avremo
S = σ * icdf(P)
dove
σ è la deviazione standard (ossia la radice quadrata di
σ2, la varianza definita precedentemente),
cdf è la distribuzione normale cumulativa
normalizzata (media pari a 0 e varianza pari a 1) e
P è il livello di servizio.
Tenendo presente che
punto di riordino = domanda nel lead time + scorta di sicurezza ,
sia
R il punto di riordino. Avremo
R = y' + σ * icdf(P)
Lead time e periodo di previsione corrispondenti
Finora, abbiamo ipotizzato che, dato un preciso
lead time, saremmo stati in grado di produrre la previsione di domanda futura corrispondente. Nella pratica, le cose funzionano in modo leggermente diverso.
Solitamente, l'analisi dei dati storici inizia con l'aggregazione dei dati in periodi di tempo (quasi sempre settimane o mesi).
Non è detto, però, che il periodo scelto corrisponda al lead time. In questo caso, saranno necessari ulteriori calcoli per determinare la domanda nel lead time e la varianza a essa associata, tenendo presente che abbiamo ipotizzato una distribuzione normale per l'errore di previsione, come abbiamo visto in precedenza.
Intuitivamente,
la domanda nel lead time può essere calcolata come la somma dei valori previsti per i periodi futuri che intersecano il segmento del lead time. Bisogna dedicare particolare attenzione a regolare in modo preciso l'ultimo periodo di previsione.
Più formalmente, sia
T il periodo e
L il lead time. Avremo
L = k * T + α * T
dove
k è un numero intero e
0 ≤ α < 1.
Sia
D la domanda nel lead time. Avremo quindi l'espressione finale per il calcolo della domanda nel lead time
D = (Σt=1..k y't) + αy'k+1
dove
y'n è la domanda prevista per i
nth periodi futuri.
Ferma restando l'ipotesi di una distribuzione normale, possiamo calcolare la varianza dell'errore di previsione come
σ2 = E[ (yt - y')2 ]
dove
y' è la previsione media per periodo
y'= D / (k + α)Tuttavia,
σ2 è calcolato qui come
varianza per periodo, mentre a noi interessa una varianza che corrisponda al lead time. Sia
σL2 la
varianza regolata per lead time. Avremo
σL2 = (k + α) σ2In conclusione, possiamo ricalcolare il punto di riordino come
R = D + σL * cdf(P)
Usare Excel per calcolare il punto di riordino
In questa sezione, vedremo in dettaglio
come calcolare il punto di riordino con Microsoft Excel. Suggeriamo di dare un'occhiata anche all'
esempio di foglio Excel che abbiamo fornito.
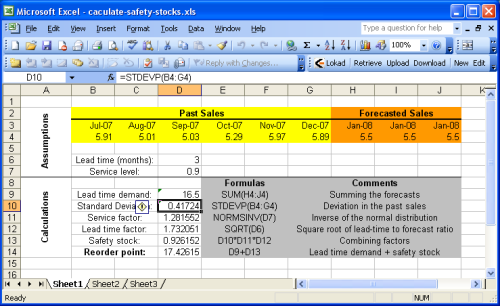
Nel caso dell'esempio, il foglio è diviso in due sezioni principali: le
ipotesi in alto e i
calcoli in basso. Le previsioni sono intese come parte delle ipotesi, poiché le previsioni di vendita (o di domanda) non sono argomento di questa guida. Per maggiori informazioni, è possibile fare riferimento al nostro
tutorial per le previsioni di vendita con Microsoft Excel.
La maggioranza delle formule che abbiamo visto in precedenza si basa su operazioni molto semplici (addizioni, moltiplicazioni), facilissime da eseguire con Microsoft Excel. Ci sono, però, due funzioni degne di nota:
NORMSINV (Microsoft KB): stima la distribuzione normale inversa, che abbiamo indicato prima come cdf;STDEV (Microsoft KB): stima la deviazione standard, che abbiamo indicato prima come σ. Ricordiamo che la deviazione standard σ è la radice quadrata della varianza σ2.
Per semplicità, il primo foglio non implementa l'euristica
σ2 = E[ (yt - y')2 ] nel calcolo del fattore di servizio. Questo approccio è implementato nello
Sheet2 (secondo foglio del documento Excel). Poiché nell'esempio abbiamo fatto l'ipotesi di previsioni stabili, il punto di riordino rimane lo stesso, con o senza questa euristica.
Riferimenti
Inventory Management and Production Planning and Scheduling, Edward A. Silver, David F. Pyke, Rein Peterson, Wiley; terza edizione, 1998

