Par Joannès Vermorel, décembre 2007 (dernière version janvier 2012)La création de stocks de sécurité est une méthode d'optimisation des stocks qui indique quelle quantité de stock doit être tenue en plus de la demande prévue afin d'atteindre un objectif de niveau de service donné. Le stock supplémentaire agit comme un tampon de "sécurité" - d'où son nom - pour protéger l'entreprise contre les futures fluctuations prévues. La formule du stock de sécurité dépend à la fois de la demande future attendue et du délai d'exécution futur attendu. L'incertitude est supposée être normalement distribuée pour ces deux facteurs. La formule du stock de sécurité est omniprésente dans la plupart des systèmes de gestion des stocks, y compris les ERP et MRP les plus connus.
Mise à jour de juillet 2020 : L’approche expliquée ci-dessous correspond au modèle classique théorique de la supply chain, qui est malheureusement très dysfonctionnel. En particulier, ni la demande future ni le délai d’approvisionnement ne sont normalement distribués (c’est-à-dire qu’ils ne sont pas gaussiens). De plus, cette perspective passe totalement à côté du fait que toutes les unités de gestion des stocks qui peuvent être commandées ou produites par l'entreprise sont en concurrence pour les mêmes ressources. Nous conseillons vivement de ne pas utiliser de modèle de stock de sécurité en ce qui concerne les supply chains réelles.
Public ciblé : Ce document s'adresse en premier lieu aux professionnels de la grande distribution et aux fabricants. Toutefois, ce document peut servir également aux éditeurs de logiciels (comptabilité, ERP, eCommerce) qui souhaiteraient ajouter à leurs applications des fonctionnalités de gestion des stocks.
Nous avons essayé de simplifier au maximum les explications mathématiques. Cependant, il n'est pas possible de se passer ici de certaines formules mathématiques, puisque cette page se veut un guide pratique pour expliquer comment calculer les stocks de sécurité.
Téléchargez : calculate-safety-stocks.xls (Tableur Microsoft Excel)
Introduction
La gestion des stocks est un
compromis financier entre le coût des stocks et le coût des ruptures de stocks. Plus vous avez de stock, plus votre besoin de fonds de roulement est élevé, et plus vos stocks se déprécient. A l'inverse, si vous n'avez pas assez de stock, vous souffrez de ruptures et vous risquez de perdre des ventes, ou même d'interrompre le processus de production dans son entier.
Le niveau de stock repose essentiellement sur deux facteurs :
- la demande : la quantité d'items qui seront consommés ou achetés.
- le délai de réapprovisionnement : le délai entre la décision de commander un item et sa mise à disponibilité effective.
Ces deux facteurs peuvent varier en fonction de :
- la variation de la demande : le comportement des clients peut évoluer de manière imprévisible.
- la variation du délai de réapprovisionnement : les fournisseurs et les transporteurs peuvent être confrontés à des difficultés non anticipées.
Décider du niveau du stock de sécurité revient implicitement à faire un compromis entre ces coûts en prenant en compte les incertitudes.
L'équilibre
coût du stock vs.
coût de rupture est fortement lié à l'activité de l'entreprise. Ainsi, au lieu de prendre en considération ces coûts directement, nous préférons introduire la notion classique de
taux de service.
Le
taux de service reflète la probabilité qu'un certain niveau de stock de sécurité suffise pour éviter la rupture de stock. Naturellement, en augmentant les stocks de sécurité, le taux de service augmente également. Si le niveau des stocks de sécurité augmente de façon considérable, le taux de service se rapproche de 100% (c'est-à-dire que la probabilité de rencontrer une rupture de stock est quasiment nulle).
Choisir le taux de service adéquat, c'est-à-dire la probabilité acceptable d'une rupture de stock, dépasse le cadre de ce guide. Nous avons conçu un guide séparé à propos du
calcul des taux de service optimaux.
Modèle de réapprovisionnement des stocks
Le point de commande est la quantité de stock censée déclencher une commande. S'il n'y avait aucune incertitude (si la demande future était parfaitement connue et que les fournisseurs étaient parfaitement fiables), le point de commande serait tout simplement égal à la demande prévue pendant le délai de réapprovisionnement, également appelé la
demande outil (lead time demand, ou lead demand).
En pratique, en raison des incertitudes, nous avons l'équation suivante :
point de commande = demande outil + stock de sécuritéSi l'on pouvait considérer que les prévisions calculées sont totalement
non biaisées (statistiquement parlant), un stock de sécurité nul correspondrait à un taux de service de l'ordre de 50%. En effet, des prévisions non biaisées signifient qu’il y a autant de chances pour que la demande future soit supérieure ou inférieure à la demande outil (souvenez-vous que la demande outil est uniquement une valeur prévisionnelle).
Attention : des prévisions peuvent être biaisées sans pour autant être exactes. Le biais indique une erreur systématique du modèle de prévision (ex : le modèle surestime la demande de 20%).
Distribution normale de l'erreur
A ce stade, nous avons besoin d'un moyen pour représenter l'incertitude dans la détermination de la demande outil. Dans ce qui suit, nous faisons l'hypothèse que l'erreur est normalement distribuée (cf. image ci-dessous).
 Remarques statistiques
Remarques statistiques : l’hypothèse de la distribution normale n’est pas totalement arbitraire. Dans certaines situations, les estimateurs statistiques convergent vers une distribution normale comme souligné par le théorème central limite. Mais ces considérations sortent du cadre de ce guide.
Une distribution normale est uniquement définie par deux paramètres : sa moyenne et sa variance. Comme nous prenons pour hypothèse que les prévisions ne sont pas biaisées, alors
la moyenne de la distribution des erreurs doit être nulle - ce qui ne signifie pas que l'erreur est de zéro.
Déterminer la variance des erreurs de prévisions est une tâche plus délicate. Lokad, comme la plupart des outils de prévisions, fournit des
estimations MAPE (Mean Absolute Percentage Error) associées à ses prévisions. Pour compléter notre explication, nous allons voir comment des heuristiques simples permettent de résoudre le problème.
En particulier, la
variance au sein de l'historique de données peut être une bonne heuristique pour estimer la variance de l'erreur de prévision. David Piasecki suggère également d'utiliser la
demande prévisionnelle plutôt que la
demande moyenne dans l'expression de la variance, à savoir
σ2 = E[ (yt - y')2 ]
où
E est l'opérateur
moyen,
yt est la demande historique pour la période
t (en général la quantité de ventes) et
y' la demande prévisionnelle.
L'idée clef qui se cache derrière cette hypothèse est que l'erreur de prévision est très souvent corrélée au niveau de variation attendue :
plus les variations à venir sont élevées, plus le niveau d'erreur sur les prévisions est élevé.
En réalité, le calcul de la variance de l'erreur implique certaines subtilités qui seront traitées plus en détails ci-dessous.
Calcul du stock de sécurité
A présent, nous savons comment déterminer à la fois la moyenne et la variance, et ainsi connaître la distribution de l'erreur. Nous devons à présent calculer le niveau d'erreur
acceptable au sein de cette distribution. Pour ce faire, nous avons introduit ci-dessus la notion de taux de service (en pourcentage).
Remarques : Nous faisons l'hypothèse que le délai de réapprovisionnement est
statique. Cependant, une approche similaire peut être utilisée pour un délai de réapprovisionnement variable. Sur ce point, cf. les articles suivants (en anglais) :
Afin de convertir le taux de service en un
niveau d'erreur, également appelé
facteur de service, nous devons utiliser
la fonction de répartition normale réciproque (cf.
NORMSINV pour la fonction Excel correspondante). Cela n'est pas aussi compliqué que cela peut le paraître ; nous vous suggérons de jeter un coup d’œil à l’
applet de répartition normale pour obtenir un aperçu visuel. Comme vous pouvez le voir, la fonction transforme le pourcentage en une
zone située sous la courbe, le seuil de l’axe X correspondant à la valeur du facteur de service.
De manière intuitive, nous pouvons calculer
stock de sécurité = écart type de l’erreur * facteur de service De manière plus formelle, avec
S le stock de sécurité, nous avons
S = σ * icdf(P)
où
σ est l'écart-type (c'est-à-dire la racine carrée de
σ2, la variance définie plus haut),
cdf la fonction de répartition réciproque
normalisée (moyenne égale à 0 et variance égale à 1), et
P le taux de service.
Sans oublier que
point de commande = demande outil + stocks de sécurité
Avec
R le point de commande, nous avons
R = y' + σ * icdf(P)Délai de réapprovisionnement et période de prévision correspondants
Jusqu'à présent, nous sommes avons simplement fait l'hypothèse que pour un
délai de réapprovisionnement donné, nous étions directement capables de produire la prévision de la demande future correspondante. En pratique, cela ne fonctionne pas exactement de cette façon.
L'analyse de l'historique de données débute généralement par l'agrégation des données en périodes de temps (semaines ou mois, en général).
Toutefois, la période choisie peut ne pas coïncider exactement avec le délai de réapprovisionnement. C'est pourquoi des calculs supplémentaires sont nécessaires pour exprimer la demande outil et sa variance associée (en considérant que nous faisons toujours l'hypothèse d'une distribution normale de l'erreur de prévision, comme nous l'avons détaillé plus haut).
Intuitivement,
la demande outil peut être calculée comme la somme des valeurs prévisionnelles pour les périodes futures croisant le segment de la demande outil. Notons qu'il faut bien prendre soin d'ajuster correctement la dernière période à prévoir.
Formellement, avec
T la période et
L le délai de réapprovisionnement. Nous écrivons
L = k * T + α * T
où
k est un nombre entier et
0 ≤ α < 1. Soit
D la demande outil, alors nous avons l’expression finale de la demande outil
D = (Σt=1..k y't) + αy'k+1
où
y'n est la demande prévisionnelle pour les
nth périodes à venir.
En faisant la même hypothèse d'une distribution normale, on peut calculer la variance de l'erreur de prévision comme étant
σ2 = E[ (yt - y')2 ]
où
y' est la prévision moyenne par période
y'= D / (k + α)Cependant,
σ2 est calculé ici comme une
variance par période, tandis qu'il nous faudrait une variance correspondant au délai de réapprovisionnement. Soit
σL2 la
variance par délai de réapprovisionnement ajustée, alors
σL2 = (k + α) σ2Pour finir, nous pouvons reformuler nouveau le point de commande de la façon suivante :
R = D + σL * cdf(P)Utiliser Excel pour calculer le point de commande
Cette section explique
comment calculer le point de commande avec Microsoft Excel. Nous vous suggérons de jeter un coup d'œil à l'
exemple de feuille Excel que nous vous proposons.
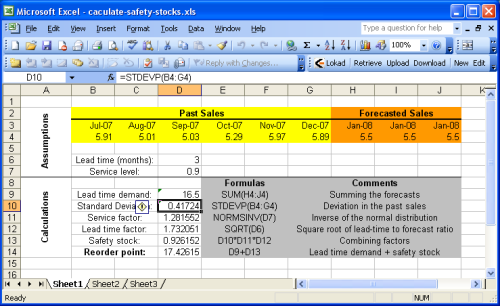
Dans notre exemple, la feuille Excel est séparée en deux sections : les
hypothèses en haut et les
calculs en bas. Les prévisions font partie de la section hypothèses, car la prévision des ventes (ou de la demande) n'entre pas dans le cadre de ce guide. Vous pouvez vous référer à notre
tutoriel sur les prévisions des ventes avec Microsoft Excel pour en savoir plus.
La plupart des formules introduites précédemment reposent sur des opérations très basiques (additions, multiplications), très faciles à exécuter sous Microsoft Excel. Cependant, deux fonctions se distinguent
NORMSINV (Microsoft KB) estime la fonction de répartition normale, notée cdf ci-dessus.STDEV (Microsoft KB) estime l'écart-type, noté σ ci-dessus. Pour rappel, σ, l'écart-type est la racine carrée de la variance notée σ2.
Pour simplifier les choses, le première feuille n'implémente pas l’heuristique
σ2 = E[ (yt - y')2 ] pour calculer le facteur de service. Cette approche est implémentée dans
Sheet2 (la 2nde feuille de calcul du document Excel). Etant donné que, dans cet exemple, nous avons fait l'hypothèse de prévisions stables, le point de commande reste identique, avec ou sans cette heuristique.
Références
Inventory Management and Production Planning and Scheduling, Edward A. Silver, David F. Pyke, Rein Peterson, Wiley; 3 edition, 1998

