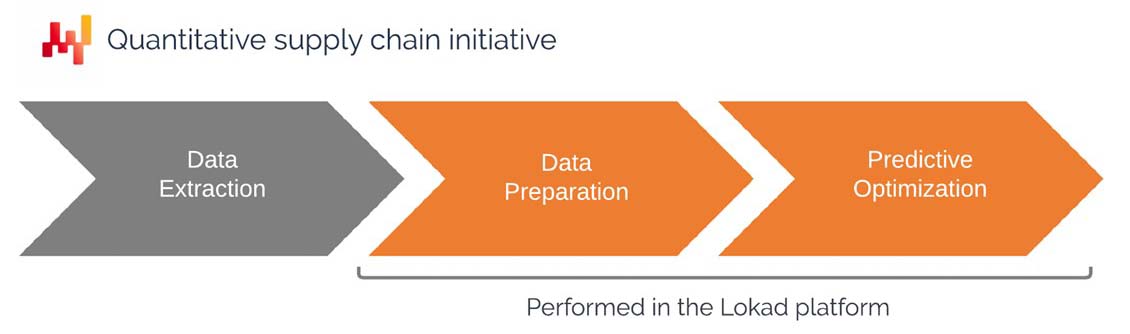
This document is intended as a guide for IT departments to construct a pipeline that extracts data from existing business systems and makes this data available within Lokad’s platform. The setup of a data pipeline is one of the earliest phases of a quantitative supply chain initiative. The document covers the approach that Lokad recommends, including the scope of the data to be extracted and made available on the Lokad platform, the format of the data, and the data transfer strategies.
Motivation and context
Lokad defines a quantitative supply chain initiative as one that delivers a
numerical recipe that automates decisions (or at least recommendations) in the face of supply chain challenges. Lokad features a programmatic platform that has been designed for the resolution of predictive optimization problems related to supply chain.
Typical problems include:
- Deciding stock quantities to replenish
- Deciding stock quantities to produce
- Deciding whether to increase or decrease prices
- Deciding if stocks should be moved within the network
If the company succeeds in optimizing these decisions, it can usually decrease its operating costs, decrease its working capital requirements, and increase its quality of service. At minimum, the company should be able to revise this mix of cost, cash, and service to make it more aligned with its overall supply chain strategy.
The numerical recipe, which addresses the problem of interest, is intended to be implemented within Lokad. As a result, the numerical recipe requires
relevant company data to be made available within Lokad’s platform. This leads to the following questions:
- Which data should be transferred to Lokad?
- Which format should be used for the data?
- Which transfer patterns should be used to refresh the data?
While the problems listed above are varied, the relevant input data are very similar, and are ordinarily serviced through the core transactional historical data of the company (historical sales, for example).
The client’s IT department is usually responsible for the setup and the maintenance of the data extraction pipeline. In the coming sections, what is specifically required from the IT department will be explained in detail.
Once the data extraction pipeline is created, Lokad-side engineers - referred to as
Supply Chain Scientists - are responsible for the setup and the maintenance of the
numerical recipe. These engineers are frequently provided by Lokad as part of a “Platform+Experts” service agreement, but it is also possible for the client to internalize this competency. However, even when such engineers are in-house, we recommend placing them in the supply chain department, rather than the IT one.
Regardless of whether this part of the supply chain initiative is externalized or not, the perspective outlined in this document remains the same.
High-level technical perspective
Lokad is an analytical layer that operates on top of the client’s existing transactional systems. In other words, Lokad does not replace the ERP; it supplements it with predictive optimization capabilities that, realistically, cannot be implemented as part of a traditional transactional system.
Each Lokad account comes with a filesystem that can be accessed through SFTP and FTPS protocols. A web interface is also available, although this interface is not typically intended for our IT audience (rather for the provision of dashboards for non-specialist users). We expect the relevant data, typically extracted from the core transactional systems used by the company, to be exported as flat files (more on this below) and uploaded to Lokad’s filesystem.
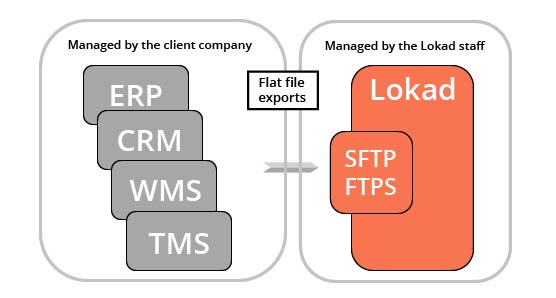
Unless otherwise agreed, the client’s IT department is responsible for everything involving the data up to the point where the flat files are uploaded to Lokad’s file system. Lokad’s platform design is such that it can process partial data extraction failures (more on this below), thus the IT department has some latitude in this regard.
Once the data are made available to Lokad, a series of Envision scripts (Envision is the domain-specific programming language developed by Lokad) process them and generate the optimized supply chain decisions of interest.
There are several practical applications of such data extraction, many of which go beyond Lokad’s supply chain optimization initiative. Marketing, finance, and sales teams – to name only three – are potential beneficiaries of the same historical sales data Lokad eventually processes. For this reason, Lokad recommends consolidating the transactional data into a dedicated servicing layer – a “data lake” – that is exclusively reserved for the provision of such data to appropriate teams and third-party analytical systems (like Lokad’s platform).
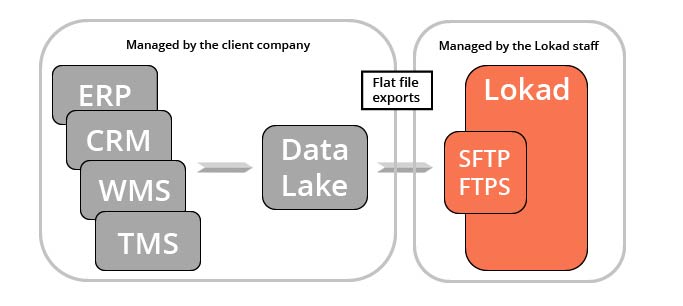
The creation of a
data lake is not a requirement for using Lokad, merely a potential architecture that eases operations for the company. It is worth noting that a
data lake also facilitates the emergence of a “data practice” within a company - should such a practice not already exist.
The scope of relevant data
Supply chain is about optimizing decisions related to the
flow of physical goods (purchasing, transportation, production, sales, etc.). As a result, the most relevant data for a predictive optimization initiative is almost always the data that describe whatever
flows happen within the company. This data is typically found in the client’s transactional business systems.
As previously mentioned, Lokad’s platform is quite flexible in its processing capabilities, therefore there are
no hard requirements when it comes to data. Most likely, the client will not be able to provide many of the data items listed below, and Lokad is able to operate within such limitations. Thus, the list below attempts to be as comprehensive as possible in identifying helpful data sources, without requiring the strict provision of each one.
Product catalog:
The list of products (or items, articles, parts) that the company buys, transforms, assembles, and/or sells. This list matters because many decisions happen at the “product” level. The hierarchy (e.g., categories, families, sub-families), if present, is relevant – both for reporting purposes and analytical purposes. Structured attributes (e.g., color, size, weight, shape) that qualify the products are also useful. As rule of thumb, any data that
describes the products – from a supply chain perspective – is relevant. Relationships between products - like BOMs (bills of materials) - are relevant too.
Sales order history:
The list of the client’s historical sales orders. This list matters because sales are almost always the best proxy that the company has to estimate market demand. This data should include the monetary amounts associated with transactions, as supply chain optimization should be performed from a financial perspective. (This financial perspective is revisited later in greater detail.) Where possible, it is (always) preferable to provide raw order transactions, as opposed to daily/weekly/monthly aggregates. (This point is also discussed in greater detail below.) The sales order history may include backlogged orders, cancelled orders, postponed orders, modified orders, returns, etc., all of which are potentially relevant data points. If clients are identified in this data, the anonymized client identifiers become relevant. (Personal data has its own section below.)
Purchase orders:
The list of the client’s historical purchase orders, as well as pending purchase orders (yet to be received). This list matters because purchase orders are almost always the best proxy for estimating supplier lead times, and their quality of service. Pending purchase orders reflect the “stock on order”. The purchase orders should also include monetary amounts associated with the transactions. Where possible, it is also (always) preferable to provide the raw order history as opposed to aggregates. The purchase order history should include, if available, the relevant dates: order date, shipment date, delivery date, etc.
Production orders:
The list of the client’s historical production orders (if applicable), and the pending production orders (yet to be executed). This list matters because these orders reflect the transformation flow of goods that happen within the company, as well as allowing us to identify the bottlenecks that may exist in the supply chain. Depending on the situation, production may have variable yields or sometimes batches may be scrapped because of quality issues. These events are relevant.
Inventory movements:
The list of the client’s historical inventory movements if multiple locations are present. This list matters because it sheds light on the origin of the stock used to either trigger production processes or serve clients. Depending on the situation, lead times for these movements may be variable. If so, the fine print of the dates (transfer order date, shipping date, receiving date) are relevant as well.
Stock levels:
The list of all the client’s SKUs (stock-keeping unit) with their current stock level. This list matters because it characterizes the current state of the supply chain. Depending on the industry, the representation of the inventory can be more complex than simple SKU levels. Expiration dates can also be present. Some or all the inventory may be tracked at the serial number level. If serial inventory is in use, the whole list of serial numbers and their associated locations is relevant. More generally, all the elements that describe the present state of the inventory assets held by the company are relevant.
Price tags:
The list of the client’s prices practiced when servicing the goods (and possibly the associated services). This list matters because the client’s present pricing policy may differ from what it used to charge. Newer prices impact future demand, but also the profitability of the supply chain decisions. Promotions, price breaks or pricing options may also be present. All the elements that contribute to the calculation of what gets charged to customers is relevant.
Snapshots of past stock levels, past price tags, and past pending purchase orders are also relevant for most supply chain purposes (however, these data are rarely available in business systems). As soon as a data extraction pipeline is in place, such snapshots can be implemented within Lokad itself – without direct intervention from the client’s IT department.
Though this list is already sizeable, when it comes to companies there are usually more relevant data sources than have been listed here. As a rule of thumb, if a piece of information is of use to the supply chain division, it is most likely relevant for predictive optimization purposes and should be directed to Lokad.
Prioritized schema of the prepared data
The list of
potentially relevant data tables cited above is not intended to overwhelm. In practice, it is important to identify which tables are
required to get the initiative to production, as opposed to being
nice to have. It is also important to properly
prioritize extractions in order to allow the supply chain scientists to move beyond the data extraction phase and into the optimization one.
Thus, as part of our supply chain practice, Lokad recommends that the supply chain scientists should produce a
prioritized schema of the prepared data and share this document with the client’s IT department at the start of the initiative. This document lists the tables – and their fields – that are expected to be available
at the end of the data preparation segment. This document also lists the respective priorities of all the fields requested.
This schema provides a high level
wish list for the data to be extracted. However, this document should not be misunderstood as a specification for the files generated at the data extraction stage. The supply chain scientists are in charge of the data preparation. It is acceptable (and commonplace) if the schema of the data, as made available by the data extraction pipeline, extensively differs from the “idealized” schema associated with the prepared data. This point is revisited in greater detail in the “Raw transactional extracts” section below.
Historical depth of the data
When it comes to the historical depth of data to be extracted, there are usually two distinct concerns. First, how far in the past should data extraction go? Second, what is the minimal historical depth necessary for the supply chain initiative to succeed?
Generally speaking, we recommend extracting the entire available history for all tables that have fewer than 1 billion lines. Editing the history translates to losing data that could be relevant for assessing the long-term evolution of the supply chain. Filters will be implemented Lokad-side as part of the data preparation, anyway, thus transferring more data does not necessarily translate into more computing resources for Lokad.
Regarding historical depth, there is no minimum requirement. If the system history is short (e.g., six months), then certain statistical patterns, like seasonality, cannot be estimated. However, supply chain practitioners, who need to take the decisions of interest, prior to the Lokad initiative, are bound by the same limitations. Lokad’s numerical recipe will be implemented in a manner that capitalizes on whatever depth of history happens to be available, even if it may appear sparse to the client.
Missing data
While modern business systems are typically extensive, there is invariably a lot of data that appears to be missing. As data is perceived to be missing, the viability of the quantitative supply chain initiative is challenged. However, no matter how much data happens to be “missing”, employees within the organization still manage to take the decisions that are needed for the supply chain to operate. In short,
there is a way. Lokad’s technological approach relies on doing the most with whatever happens to be available – just like employees do. This approach is the opposite of mainstream enterprise software that comes with final data requirements and will not operate unless all the requirements are met.
In our experience, there are two broad classes of “missing” data that should be distinguished: first, data that ought to be integrated in the business system; second, data that are thought to be highly beneficial for the analytical system (such as Lokad).
Minimal Order Quantities (MOQs), price breaks, and suppliers’ closed weeks are data that are frequently missing from business systems. Yet, these data are valuable from a supply chain optimization perspective. Such data might be scattered across spreadsheets and emails, preventing any direct structured analysis Lokad-side. When confronted with these situations, we suggest using heuristics (to be coded by Lokad) and using ad-hoc spreadsheets (to be uploaded to Lokad). Once the numerical recipe becomes operational, Lokad will engage the client’s IT department to make the data part of the business system(s). Moreover, the numerical recipe itself clarifies what data truly matter and to what extent.
Competitive intelligence data, such as competitors’ prices, is a category that is believed to be highly useful but, in our experience, this is not self-evident. Anecdotally, gaining this kind of data often comes at a substantial cost, otherwise companies would already do it. For this reason, providing such data is not a requirement. In any case, Lokad’s numerical recipe will be instrumental in assessing - at a later date - the actual financial gains associated with extra data.
Raw transactional extracts
We strenuously recommend preserving the original form of the data. The data pushed to Lokad should be nothing more than raw copies of the original tables and columns, as found in the RDBMS supporting the business systems of the company. All the data preparation should be delegated to the Lokad platform, which has been specifically engineered for data preparation.
Attempting to prepare the data invariably results in data loss. Whether this loss is acceptable or not depends on the specific supply chain decisions of interest. If the data are already lost by the time they reach Lokad’s platform, nothing can be done to recover this loss. Raw transactional extractions ensure that the entirety of the information available in the business systems becomes accessible within Lokad.
Moreover, data preparation introduces its own layer of complexity on top of the complexity of the business systems themselves. Granted, the numerical recipe that delivers the desired supply chain optimization cannot avoid dealing with classes of intrinsic complexity. However, if this numerical recipe also has to cope with the
accidental complexity introduced by prior data preparation, it turns an already difficult problem into an unreasonably difficult one. Raw transactional extractions ensure that Lokad does not end up tackling an even bigger problem than the one that needs to be solved.
From an IT perspective, raw transactional extractions are simple. Plain table copies should be used (e.g.,
SELECT * FROM MyTable), which is the simplest form of queries over a relational database. Such queries are simple, as there are no filters involved, and performant, as there is no join involved. Very large tables require some dedicated attention though. This point is covered below.
If a data lake is in place, then the data lake should
mirror the relational data as it is found in the business systems. All mainstream database systems have built-in mirroring capabilities. We recommend taking advantage of these capabilities when setting up the data lake. Moreover, mirroring data is vastly easier than preparing data - especially from the position of the IT department, as data preparation is highly dependent on the specific problem to be addressed.
The BI extraction antipattern
The data to be sent to Lokad should not originate from a secondary source (e.g., a Business Intelligence (BI) system) where the data have already been extensively modified, usually for the benefit of direct end-user consumption. Though extracting data from a BI system is easier than from an ERP, this invariably creates unsolvable problems down the road. By design, the transactional aspects of the data are lost, as data get aggregated into daily / weekly / monthly time-series.
Moreover, many hard-to-visualize but relevant complications, such as multi-line orders, are eliminated from Business Intelligence systems (such as BI cubes). These details are valuable as they reflect the essence of supply chain situations that must be addressed.
Bad data
In Lokad’s experience, instances of
bad data are rare. On the contrary, transactional business systems (like ERPs) usually have accurate data. Incorrect transactional data entries are rare and typically occur once or twice per 1000 entries. When barcodes or similar devices are used, the error rate is even lower. The real problem lies in the software making incorrect assumptions about the data, rather than the data itself being bad.
In-store stock levels for large B2C retail networks are almost always inaccurate. However, from Lokad’s perspective, this situation is a case of
noisy data, not bad data. If such stock levels are (incorrectly) assumed to be precise, results will be nonsensical. We approach this specific situation with a probabilistic view of stock levels, embracing uncertainty rather than dismissing it.
In fine, Lokad’s systems have been engineered to receive data and let the client operate their supply chain without stressing over these concerns. Lokad establishes a
data semantic to address these issues and this represents the most challenging part of the data preparation stage.
Personal data
A supply chain initiative almost never needs personal data to operate. Thus, from a supply chain perspective, we recommend treating personal data as a liability, not an asset. We strongly discourage the transfer of personal data to Lokad’s platform. In practice, this usually means filtering out the database columns (see discussion below) that contain personal identifiers (e.g., name, address, phone number, email, etc.).
These personal identifiers can be replaced by opaque anonymous ones – if the information is relevant from a supply chain perspective. For example, opaque client identifiers are useful because they allow Lokad to identify patterns related to customer loyalty - such as the negative impact of stock-outs. Unlike most forecasting technologies that can only operate with a time-series perspective, Lokad’s platform can take advantage of ultra-granular historical data, down to and including the transaction level.
If you are unsure about Lokad’s position on Personal Identifiable Information (PII), this topic is addressed in Sections 1, 3, and 4 of our
security document.
Financial data
Monetary amounts for goods purchased, transformed, and sold by the client are of prime relevance to the supply chain optimization Lokad provides. In fact, Lokad emphasizes a financial perspective on supply chain that optimizes
dollars of return over
percentages of error.
Unlike vendors who only consider data related to stock quantities, Lokad utilizes a client’s financial data - if made available. Logically, the most distressing supply chain costs are concentrated at the extremes; unexpectedly high demand generates stock-outs; and unexpectedly low demand generates inventory write-offs. In between, the inventory rotates just fine. Thus, in order to truly optimize inventory decisions, a financial tradeoff must be made regarding these risks. Lokad leverages a client’s financial data to compute an adequate tradeoff.
Data pipeline vs one-shot extraction
A data extraction pipeline automatically refreshes the data transferred to Lokad. This setup represents a larger effort than a one-shot data extraction. If possible, we strongly recommend automating the data extraction, possibly with a phased approach if the number of relevant tables is large. This automation works best if installed from Day 1. However, partial one-shot extractions used to identify relevant tables can be useful. This point is discussed in the following passages.
There are three main reasons to support a data pipeline approach.
First, from the supply chain practitioner’s perspective, 3-week-old data is ancient history. The results obtained from stale data are irrelevant as far as present-day supply chain decisions are concerned. A one-shot extraction would produce results based on a single snapshot of the client’s business history. This would produce results of limited value. Moreover, supply chain practitioners need to see the analytical system
in action in order to gain trust in its capacity to handle day-to-day variability.
Second, though engineering a highly reliable data pipeline is difficult, it is preferable to the alternatives. An unreliable data pipeline endangers the whole quantitative supply chain initiative, as no amount of analytics can fix basic data problems, such as not having access to up-to-date stock levels.
It usually takes numerous scheduled runs to perfect the extraction process, as some issues only present intermittently. The surest way to fix these issues is to start running the data pipeline as early as possible, thus allowing Lokad to identify and resolve any problems. In particular, scheduled runs are also one of the safest options to assess the end-to-end performance of the whole sequence of processes, including those that lead to the delivery of recommended supply chain decisions.
Third, in our experience, the most frequent cause of delayed quantitative supply chain initiatives is the late setup of the data extraction pipeline. We acknowledge IT departments are frequently under a lot of pressure to deliver many projects and constructing a data extraction pipeline is one more task they must contend with. Thus, it is tempting – for the IT department – to postpone the
pipeline part, opting instead to start with a series of one-shot extractions. Though this approach is viable, it presents the risk of introducing delays to the initiative, as well as preventing Lokad from identifying entire classes of potential problems as early as possible (as described in the previous paragraph).
Data extraction frequency
We recommend refreshing all the data pipelines – the extraction segments, as well as the analytical segments – at least once a day, even when dealing with monthly or quarterly calculations. This may seem counterintuitive, but, in our experience, frequent automated refreshes are the only way to achieve a
highly reliable end-to-end process.
For most supply chain situations, we recommend an extraction routine that delivers a complete data picture up to the close of the current day’s business (e.g., extracting on Thursday evening
all the pertinent historical data up to close of business on Thursday). The data extraction pipeline runs at the end of the workday, and the analytical processing – within the Lokad platform – follows. Fresh results are available from the very start of the next business day.
Data extraction depth: the 2+1 rule for increments
When the data is too large to be reuploaded to Lokad in full every day, incremental uploads should be used. We recommend such uploads follow the
2+1 rule for increments: the time window of the daily upload covers the last two complete weeks, plus the current one. Following this rule is important to ensure the high reliability of the Lokad solution.
The data extraction pipeline will fail once in a while – independently of Lokad. In our experience, even excellent IT departments experience 1-2 pipeline failures per year. When the daily upload fails, the last day of data is compromised. If each daily upload only covers a single day (no overlap between uploads), Lokad is left with a partially corrupted data history. Fixing this history, Lokad-side, requires a second manual intervention from the IT department, in addition to fixing whatever prevented the data extraction pipeline from running properly in the first place. This “data history fix” is likely to be delayed by a few days – as this is an unusual operation for the IT department. Meanwhile, the results returned by Lokad are negatively impacted, as some recent data happen to be partially corrupted.
On the contrary, if each daily upload covers the last two complete business weeks, plus the current one, a failed daily run of the data extraction pipeline benefits from a complete recovery the next day. Indeed, as the data extraction pipeline is part of the routine operations covered by the IT department, resuming the normal state of operation is likely to happen within one business day. This recovery does not require any specific interaction between the IT department and either Lokad’s support staff or the end-users of the Lokad solution. The data fix gets automatically delivered through the overwrites that happen on a daily basis covering the 2+1 time window.
The 2+1 rule reflects a tradeoff based on Lokad’s experience: the longer the time window, the more resilient the data extraction pipeline becomes against transient issues. Though we can hope that any issues with the data extraction pipeline can be resolved within one business day, the IT department may have more pressing issues. In fact, the failing data extraction pipeline may only be a symptom of a more severe problem that the IT department prioritizes resolving. Thus, the recovery may take a few days. The 2+1 rule ensures that as long as the IT department manages to fix the pipeline within two weeks, operations can resume as usual with as little impact to the optimization initiative as possible. However, if the time window is too long, then the incremental upload becomes too heavy in terms of computing resources, defeating the very reason why incremental uploads were introduced in the first place.
If the last three weeks represent less than 100MB of data, we suggest adopting the
monthly variant of the 2+1 rule: the time window of the daily upload covers the last two complete months, plus the current one.
Identifying the relevant tables and columns
The vast majority of enterprise software are built on top of relational databases. While web APIs might exist, in our experience, such APIs rarely deliver a satisfying performance when it comes to scheduled full-history extractions. On the contrary, directly querying the database though SQL frequently proves both straightforward to implement and fairly performant as well, as the SQL queries recommended by Lokad do not require any join to be performed.
Thus, once a business system (e.g., ERP) has been deemed a relevant data source for the initiative, and assuming that the underlying relational database can be accessed, the specific shortlist of relevant tables and columns must be identified. Many business systems contain hundreds of tables and thousands of columns, most of which are irrelevant to the supply chain initiative. As a rule of thumb, a supply chain initiative rarely needs more than a dozen tables to get started and only a few dozen to achieve a high degree of data coverage.
If the company has access to an expert who is familiar with the database schema of the business, leveraging this expertise is the simplest way to identify the relevant tables within the database. However, if there is no expert, reverse engineering the database to identify the areas of interest can typically still be done in a week or two (even in the presence of a fairly complex system). In addition to leveraging whatever technical documentation is accessible concerning the system of interest, we suggest starting with a complete schema extraction of the database, including:
- the table name
- the column name
- the column type
- the table size
We suggest collating this information within a spreadsheet. The potential tables can be identified by their names and sizes. We suggest starting with a closer inspection of the largest tables, as that is where one can usually discover the most relevant ones (for an optimized supply chain initiative). In order to inspect a table, we suggest a visual inspection of a few dozen data lines. The observations should be added to the spreadsheet as the work progresses.
PostgreSQL schema diagnosis
The query for extracting all the tables and columns:
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = '‘table_name'’;See also
https://stackoverflow.com/questions/20194806/how-to-get-a-list-column-names-and-datatypes-of-a-table-in-postgresql
The query for extracting all the table sizes:
select table_name, pg_relation_size(quote_ident(table_name))
from information_schema.tables
where table_schema = '‘public'’See also
https://stackoverflow.com/questions/21738408/postgresql-list-and-order-tables-by-size
The query template for extracting a sample of rows:
select column from table
order by RANDOM()
limit 10000See also https://stackoverflow.com/questions/19412/how-to-request-a-random-row-in-sql
Oracle schema diagnosis
The query for extracting all the tables and columns:
SELECT table_name, column_name, data_type FROM ALL_TAB_COLUMNSThe query for extracting all the table sizes:
SELECT table_name, num_rows FROM ALL_TABLESThe query template for extracting a sample of rows:
set colsep ,
set headsep off
set pagesize 0
set trimspool on
spool c:/temp/oracle/output/foo_my_table.csv
SELECT * FROM FOO_MY_TABLE FETCH FIRST 10000 ROWS ONLY;
spool offFile formats and transfers
The Lokad platform supports plain text, flat file formats (typically CSV or TSV formats) as well as Microsoft Excel spreadsheets, both for read and write operations. The
Read and Write Files section documents Lokad’s I/O capabilities. While Lokad supports quite a diverse set of formatting options, we recommend the following:
- Plain text is used instead of spreadsheets (see discussion below).
- The first row contains the column headers and matches the original column names.
- Column names do not contain whitespaces or hyphens.
- UTF-8 is used for character encoding.
- Dot (.) is the decimal separator for fractional numbers.
- Dates all share the same format across tables.
- Monetary amounts isolate the currency in a separate column
- The file name matches the original table name.
- /input is the Lokad-side folder used, by convention, for depositing the extracted files.
Whenever an extracted flat file is larger than 100MB, we recommend compressing the file using GZIP.
Transfer-wise, we recommend using
SFTP with a public key authentication.
Partitioned tables
We recommend partitioning tables that are too large to be conveniently reuploaded to Lokad in full on a daily basis. Partitioning typically allows incremental uploads if the partition reflects the age of the data. As a rule of thumb, tables that have fewer than 1 million lines are usually not worth the effort it takes to partition them.
When partitioning a table into a list of files, the recommended file naming pattern consists of gathering the files into a dedicated subfolder within
/input (named after the respective table), and of suffixing each file with the corresponding extracted segment:
/input/mytable/mytable-2022-10-17.csv
/input/mytable/mytable-2022-10-18.csv
/input/mytable/mytable-2022-10-19.csv
/..Even if all the lines inside a file have the same “date” value (matching the one found in the name of the file), we recommend keeping this “date” column as part of the file.
Microsoft Excel
Lokad’s platform supports the reading of data from Microsoft Excel spreadsheets, as long as the spreadsheet follows a tabular format (first line contains the headers, then one record per line). However, the data extraction pipeline should avoid transferring spreadsheets to Lokad.
Spreadsheets are acceptable if files are
manually uploaded to Lokad, as opposed to being transferred through the automated data extraction pipeline. Manual uploads are acceptable if:
- The data does not exist (yet) in the business systems.
- The data is very infrequently updated.
/manual is the Lokad-side folder used, by convention, receive manually uploaded files.
File overwrites
The files within the Lokad filesystem represent the data as seen by Lokad. Overwriting existing files is the recommended way to refresh the extracted tables that are not partitioned. In the case of a partitioned table, the default expectation is to have one new file created for every period (one file per day, or week, or month).
Once all the files to be created (or overwritten) are transferred to Lokad, we recommend creating (or updating) a file named
/input/end-of-transfer.csv that contains:
- a single column named
LastTransfer - a single data line (two lines when counting the header) with a timestamp of the most recent transfer
This file can be used to trigger a
project sequence that processes the freshly updated data.
Data Health
The data extraction pipeline must operate reliably. The Lokad platform itself can be used to instrument the output of the extraction pipeline and assess the integrity, completeness, and freshness of the extracted data. Thus, as the very first step of the pipeline within Lokad, we recommend implementing
data health dashboards. These dashboards are intended for the IT department (though they are not expected to take charge of them). The dashboards’ collective purpose is to outline any data issue(s) and speed up the eventual resolution by the IT department. This implementation, like the rest of the numerical recipe driving the optimized supply chain initiative, is expected to be done by a supply chain expert, possibly by the Lokad team (in the case of a Platform+Experts subscription).
Specification of the data extraction
Once the data extraction pipeline has been stabilized, we recommend producing a specification for the data extraction. This document should list all the expected files and their columns, as well as the timetable for the data extraction. The stabilization of the data pipeline is expected to happen within six months of the initiative’s kickoff. This document should be jointly agreed upon by the IT department and by the supply chain department. This document contains the fine print of the data expected to be made available, in a timely manner, by the IT department to the Lokad platform.
The data format can still be revised at a later date, but the IT department is expected to notify the supply chain department prior to making any change to the data format or to the associated schedule. In general, once the specification has been agreed upon, the operations of the supply chain should be expected to rely,
for production purposes, on the integrity of the data extraction. Thus, in the event of any change(s), the supply chain department should expect a reasonable “grace period” that is sufficient to upgrade the logic within Lokad (to accommodate the revised data format).
As producing a detailed specification requires significant time and effort, we recommend delaying the production of this document until the pipeline is stabilized. In our experience, during the first couple of months, the pipeline - both its data extraction and analytical segments - undergo a rapid evolution. This rapid evolution is likely to deprecate early attempts at producing such a specification.
Feedback loop
The supply chain decisions (e.g., inventory replenishments) generated within the Lokad platform can be exported as flat files to be reintegrated into the business system(s). This mechanism is referred to as the
feedback loop. Our experience indicates that the feedback loop is unlikely to be implemented within four months of the initiative’s kick-off. The trust in the numerical recipe required to allow even a portion of the supply chain to run on autopilot is substantial, and this degree of confidence can take several months to cultivate. Thus, the feedback loop is not a concern at the start of the initiative.
In our experience, the setup of the feedback loop is a much smaller challenge than the setup of the data extraction pipeline. For example, the figures, as produced within Lokad, are expected to be authoritative and final; if there are further rules to be applied to turn those figures into actionable numbers (e.g., applied MOQs), then the numerical recipe is incomplete and needs fixing
on the Lokad side. On the other hand, Lokad’s platform has the capacity to process and produce any form of data as long as it is reasonably tabular. Thus, the simplicity of the feedback loop is designed to reflect the simplicity of the supply chain decisions. For example, there might be dozens of constraints that define whether a given purchase order is valid or not, but the content of the final purchase order is a straightforward list of quantities associated to part numbers.
However, we recommend that the Lokad platform should not be given
direct access to the client’s business systems. Instead, files should be made available in a timely manner within the Lokad file system. The IT department remains in charge of importing this data back into the business systems. This ensures that a potential security breach of the Lokad account cannot be used to access other systems within the company. Also, this provides the capability to postpone this feedback operation if it conflicts with another operation carried out by IT over the business system(s).
Given the feedback loop entails, by definition, data pertaining to real-world supply chain operations, we recommend producing a specification dedicated to this process. This specification mirrors the data extraction one, but with data being transferred in the opposite direction. This document is also expected to be jointly agreed upon by the IT and supply chain departments.