Quantile forecasts are a significant improvement over classical forecasts whenever inventory is involved. However probabilistic forecasting vastly outperforms quantile forecasts.
The most well-known type of forecast is the
mean forecast where respective weights of
over and
under forecasting are strictly balanced. Projected temperatures for the next day are a typical example of mean forecasts.
Quantile forecasts are different: a bias is introduced on purpose in order to alter the odds of over and under forecasting. Quantiles represent a
radical improvement over classical forecasts for many verticals such as retail, wholesale and manufacturing. In March 2012, Lokad has become the first software vendor to deliver industrial-grade quantile forecasts. This page details why quantile forecasts matter and how they differ from classical forecasts.
Whitepaper
Spare parts inventory management with quantiles
In a world where most equipment manufacturers and retailers are operating in fiercely competitive markets, delivering a high service level to the existing customer base is a strategic priority for many companies. However, managing a spare parts inventory efficiently still poses a huge challenge due to size and the erratic nature of demand. This whitepaper discusses the challenges and current state of spare parts planning technology, and introduces quantile forecasting as a disruptive new approach to tackling the problem.
GET THE STORY (PDF)
Foreword
The terminology quantile forecast might sound complicated, and chances are, unless you’re deeply versed in statistics, that you’ve never heard the term before. However, quantile forecasts – without being named that way - are routinely used in retail and manufacturing businesses. For example, defining a reorder point for your inventory is strictly equivalent to producing a quantile forecast over the demand. Despite radical implications of quantile forecasts for retail and manufacturing, quantiles have received little attention in the market so far. The simplest explanation is that support for quantile forecasts was close to nonexistent in the software industry. However, with Lokad, there is no reason to overlook anymore such a critical piece of technology.
What are demand forecasts required for?
In order to understand why quantile forecasts are of any use for a retailer or a manufacturer, we need to back to why forecasts are required in the first place. Demand forecasts are critical in order to ensure that the right level of resources - such as inventory, staffing or cash - is available at the right time.However, meeting the demand with the right level of resources is typically a very asymmetric problem: the cost of over-allocating resources (aka over-forecasting) can vastly differ from the cost of under-allocating resources (aka under-forecasting).
For example:
- Food retailers typically seek very high service levels at 95% or more (i.e. very infrequent stock-outs). In this context, it is estimated that the marginal cost of a stock-out vastly excesses the marginal cost an extra unit of stock.
- Car manufacturers are under increasing pressure to lower their production costs. As a result, some manufacturers opt for a zero-stock strategy - and consequently a zero immediate availability - where cars can only be purchased first to be manufactured later on. In this situation, it is estimated that the marginal cost of the stock excesses the cost of the non-immediate availability. Thus, for companies, it is typically not profitable to allocate their resources based on raw mean demand forecasts, as allocating too few resources 50% of the time is a poor trade-off that does not reflect the reality of the business.
Hence, companies are purposefully introducing a bias in their resource allocations to reflect the business-specific asymmetry that exists in their trade. Being able to better deal with this asymmetry is exactly what quantile forecasts are about.
A quantile forecast (τ, λ) where τ (tau) is the target probability and where λ (lambda) is the horizon expressed in days, represent a demand forecast over the next λ days that come with a probability of τ of being higher than the future demand (consequently a probability 1-τ of being lower than the future demand).
Extrapolated quantiles and when they do not work
Quantile forecasts have been known for decades, however implementing a native quantile forecasting model is frequently, and rightfully, considered as being as a lot more complicated than implementing a mean forecasting model. As a result, the vast majority of forecasting software vendors (*) are only delivering mean forecasts.
(*) As far we know, Lokad has become in March 2012, the first vendor to deliver a native industrial-grade generic quantile forecasting technology. However, among academic circles, research prototypes for quantile regression have been around for decades.
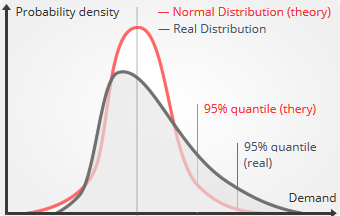
However, as companies do require quantile forecasts, they typically leverage an extrapolation work-around to produce their quantile forecasts. Practically speaking, the approach consists of assuming that the demand follows a normal distribution and to add a corrective safety term. The classical safety stock approach follows this pattern for example.
Extrapolated quantiles are classic (mean) forecasts transformed into quantile forecasts through an extrapolation method. The term is opposed to native quantiles where the statistical model directly produces the quantile. The extrapolation doesn't rely on input data, but rather on a distribution defined a priori. This distribution, usually the normal distribution, tends to be the weakest link of the extrapolation process, as it differs from the reality
Unfortunately, the extrapolation suffers from serious drawbacks in 3 frequent contexts:
- High quantiles (i.e. high service level)
- Intermittent demand
- Spiky demand (bulk orders)
In those situations, we have found that
native quantile forecasts tend to outperform of 20% or more the best extrapolated quantile forecasts; the comparison being made by leveraging the respective quantile and classical forecasting technologies of Lokad - knowing that those already tend to outperform the competition.
High quantiles (i.e. high service levels)
The assumption that errors associated to forecasts are normally distributed is typically good for quantile targets close to the mean or the median. However, the quality of the
approximation degrades as the target percentage increases. For high target percentages, typically all values above 90%, we have found that the extrapolation itself frequently becomes the weakest link of the forecast. In those situations, native quantiles should be favored.
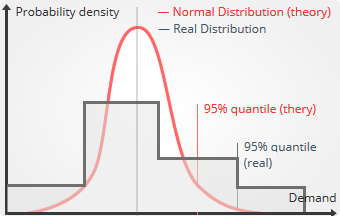
Intermittent demand
The extrapolation tries to fit a
smooth curve over the future demand in order to reflect uncertainty. However, when the demand is intermittent or sparse, there is
nothing smooth about the demand: for each period (week, month), the number of units being sold, i.e. the observable demand, is an integer varying between 0 and 5 for example. Historically, many
mean forecasting models have been designed to better apprehend sparse demand; however from the quantile angle, it becomes clear that the more fundamental issue is that no mean forecast can be properly extrapolated into an accurate quantile in case of sparse demand. In contrast, native quantiles can completely fit
small-integers patterns of the demand.
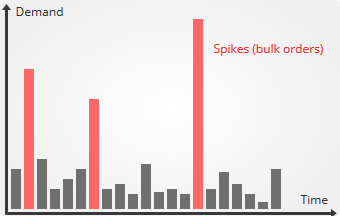
Spiky demand (bulk orders)
When bulk orders are present, the historical demand curve tends to have a rather spiky shape. This shape reflects that a few orders account for a significant percentage of the total demand. However, contrary to the intermittent demand case, a non-zero demand exists all the time. The fundamental issue here is not that the demand goes through
integral values; it is that mean forecasts fail at properly projecting those spikes in the future.
Oversimplifying, there are two approaches to deal with spikes:
- Discard them if the company decides they are not worth pre-allocating resources.
- Adjust pre-allocated resources in order to handle them, or a least handle a certain fraction of the spikes.
In both cases, mean forecasts behave poorly: extrapolated quantiles remain too low to capture spikes while in the same time, they are over-estimating the resources to handle non-spike demand. Native quantile forecasts address spikes in a more direct and more accurate manner.
Native quantile forecasts by Lokad
This is a legacy article. Our latest generation of forecasting engine no longer operates with quantile forecasts. Check out our latest Technology pages for more information.
Lokad delivers a
fully automated online service that takes time-series as input and returns native quantile forecasts, each quantile matching its horizon and target percentage (respectively lead time and the service level in case of inventory optimization). No extrapolation is required. The quantile forecasting process requires
zero statistical expertise. In practice, most companies will go through our webapp in order to get optimized
reorder points; the reorder point being an inventory-specific quantile forecast. For each time-series, the quantile forecast is just one single data point. Unlike mean forecasts,
quantile forecasts are typically not represented as a curve that evolves over time and that extends the historical curve into the future. Quantile forecasts behave differently statistically-speaking, however fundamental underlying demand patterns remain the same: trend, seasonality, product life-cycle, promotions ... All patterns supported by our
classic forecasting technology are also supported by our
quantile forecasting technology.
Classic (mean) vs Quantile forecasts
From a mathematical viewpoint,
quantile forecasts represent a generalization of the classical notion of forecasts. From a practical viewpoint, quantile forecasts are typically superior (more accurate) for most business situations where risks associated to over and under estimates of the demand are not symmetric.
However, quantile forecasts are also
less readable and less intuitive. Hence, classic forecasts remain a fundamental tool for managers to get a more intuitive grasp of the evolution of their business.
We have no plan whatsoever to deprecate classic forecasts. As a matter of fact, most of R&D efforts that we push on our forecasting technology benefit to the two types of forecasts. Quantile forecasting is a chance for us to refine our understanding of the statistical behavior of the demand. Our No1 priority remains
to deliver more accurate forecasts.
Stock-out bias on quantile forecasts
Stock-outs not only hurt the business because of the loss of loyalty they create among clients who cannot be serviced, but stock-outs also introduces a bias in the observations of the historical demand. Because of stock-outs, zero sales does necessarily equal zero demand. Salescast is not immune to this problem; however, when properly used, it can be made extremely
resilient to it.

Impact of stock-outs on the classic forecasts
A forecast in the classical (median) sense represents an anticipation of the future that has 50% chance to be above or below the future demand. When stock-outs are observed, a
downward bias is introduced within the historical records because unfulfilled demand is typically not accounted for.
As a consequence, the forecasts built upon the historical data come with a downward bias as well, hence generating further stock-outs.
In the most extreme case, if there is no minimal stock level defined, the replenishment process can converge to a
frozen inventory status where no sales are further recorded – because there is no stock – and where no inventory is further reordered. Worse, in this situation, forecasts are 100% accurate: forecast is at zero and sales are at zero as well.
Pitfalls of stock-out data integration
In order to correct the bias introduced by stock-outs, stock-outs should be accounted for. This can be done by collecting detailed historical records about all the past (and current) stock-outs. While this idea is appealing, we observe that this approach requires considerable efforts in practice.
- Most companies do not accurately track stock-outs. It’s not sufficient to have some stock-out data, the data about stock-out should be extensive and accurate to have any hope for improving the demand forecasts.
- Stock-outs are (hopefully) relatively rare, usually occurring less than 10% of the time in most businesses. As a consequence, it takes a significant business volume to collect enough data to support a robust statistical analysis of the stock-outs.
- The impact of stock-outs is complex. Stock-outs cause cannibalizations (on the unavailable items) when substitutes are present. They also cause some clients to postpone their demand, leading sometime to a “surge” of demand when items become available again.
Quantiles as bias-resilient forecasts
Instead, quantile forecasts represent a much more efficient and
leaner alternative to mitigate the bulk of bias introduced by stock-outs. In short, quantiles are used to compute reorder points as
natively biased forecasts. For example, a reorder point computed with a 95% service level is an estimation built to be 95% of the time just above the demand (facing a stock-out only 5% of the time).
Quantile forecasts, when associated to
high service levels - i.e. above 90% in practice - behave very differently than classic forecasts. Intuitively, in order to compute a 95% quantile forecast, the analysis focuses on the Top 5% most extreme fluctuations of the demand. While it is possible that the stock-outs have been so predominant in the historical that even the top 5% sales ever observed are only a fraction of the “usual” demand, in practice, this is usually not the case. Even in presence of significant stock-outs, the highest point of demand in the history is typically higher than the average demand.
As a result, quantile forecasts almost never get into the vicious circle where stock-outs introduce so much bias that, in turn, biased forecasts exacerbate further the stock-out problem. We observe that, for vast majority of our clients, quantile forecasts lead to a virtuous circle where quantiles, being more resilient to bias, immediately reduce the frequency of stock-outs,
bringing service levels back in control. Then, after a while, the frequency of stock-outs converges toward the defined target service levels.
Choosing your service levels
When quantile forecasts are used, the reorder point is computed as a function of
expected demand, lead time and service level. The reorder quantity is computed as the reorder point minus the stock on hand and minus the stock on order. The service level represents the desired probability of not getting a stock-out. The following article gives a short introduction to the topic and guidance on how to set appropriate service levels.
The implicit assumption within this statement: It is not economic to always be able to service an order from stock on hand. Deciding on the
right service level for a certain product is essentially
balancing inventory costs vs. the cost of a stock out. Service level is therefore an important variable for calculating the appropriate safety stock; the higher the desired service level, the more safety stock needs to be held.
Unfortunately, the cost functions describing the problem are extremely very business specific. While inventory costs can often be determined rather easily, the cost of stock outs are much more complicated to determine. A customer that does not find the product in store might either choose an alternative that is in store, postpone the purchase to a later date or buy at the competition. In grocery retail for example, out-of-shelf situations of certain
must have products are known to drive customers out of the store, taking their business to a competitor.
As this example illustrates, the associated cost functions are not only business, but
product specific. When considering that most manufacturers and retailers are dealing with hundreds to hundreds of thousands of products, it becomes obvious that an
overly scientific approach is not advisable nor feasible.
The good news is that in practice it mostly proves fully sufficient to
work with a simple framework that can be fine-tuned over time.
How to get started
Service levels are considered by many retailers as part of their core IP, and tightly guarded. Nevertheless, some
ballpark figures should provide a good starting point: A typical service level in retail is 90%, with high priority items reaching 95%. We have seen a number of customers successfully choosing a very pragmatic approach when setting service level at a uniform 90%
starting point, to subsequently improving and adjusting these to their needs.
It is important to understand the relationship between service level and safety stock. Graph 1 illustrates the relationship. Dividing by 2 the
distance to 100% multiplies the safety stock by 2. For example, if an increase in service level from 95% to 97.5% will double the necessary safety stock. Service Levels approaching 100% get extremely expensive very fast, and a service level of 100% is the mathematical equivalent to
infinite safety stock.
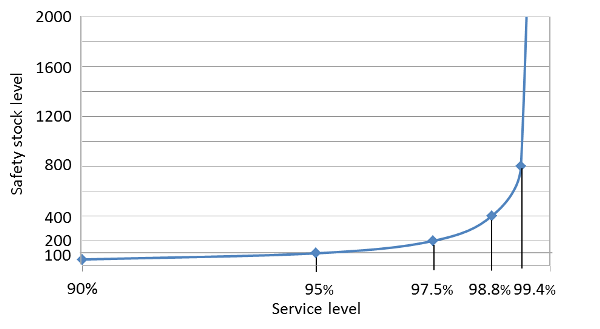 Graph 1: Relationship safety stock vs. service level |
Choosing categories
It is in our experience fully sufficient to differentiate between 3-5 service level categories that cover the product portfolio from
must have items to the lowest priority items. As an example, we chose a three-value system:
- High: 95%
- Medium: 90%
- Low: 85%
Categorizing products
Product rankings allow a structured and sensible way to allocate products to the categories we defined previously. Rankings that are often used solely or in combination include turnover, profitability, number of orders, COGS (cost of goods sold).
Example product ranking by turnover- Top 80% of turnover: High service level
- Next 15% of turnover: Medium service level
- Next 5% of turnover: Low service level
Example product ranking by gross margin contribution- Top 80% of gross margin: High service level
- Next 15% of gross margin: Medium service level
- Next 5% of gross margin: Low service level
Once the categories have been defined and service levels have been assigned, Lokad will determine the reorder point (including safety stock levels) as a function of theses values. We often see that a lot of potential for inventory reduction is not only leveraged by the accuracy of our forecast, but also by the more sophisticated method and frequent update of the service level.
Who still feels rather insecure regarding the correct service level to be entered into Lokad should remember that it is not important, and also rather unrealistic, to have the perfectly fine-tuned service levels right out of the gates. What is important is that the new attention to this notion, in combination with Lokad forecasts and reorder point analysis,
will improve the status quo with a high certainty.