Excelを使った予測方法
著者Guillaume Saint-Jacques。推敲日2008年6月18日 (最終改訂日2010年2月22日)
予測の利点
予測することで、正確な判断が導かれ、お金を稼いだり、節約につながります。ここに一つの例を挙げます。- 在庫規模を最適に保つ
時は金なり。在庫スペースも金なり。どうするかと言えば、在庫を最小限に抑える、もちろん、品切れのないようにです。
ではどのような方法で?予測によって行うのです!
より使いやすくするために: ラベル付け、コメント、ファイル名
時間を経てデータが蓄積されると、混乱しやすくなってきます。そしてそれはミスにつながります。ではその解決策とは?きちんとラベル付けし、コメントを付け、ファイルに正しい名称をつければトラブルを避けることができます。- 常に列(コラム)にラベル付けをする。.各列の最初の行にデータ名をつけます。
- 違うデータは別の列を使う。 別々の数値(例えばコストと売上げなど)を同じ列に記入しない。これが混乱の原因になり、計算とデータの取り扱いを難しくします。
- 各ファイルごとにはっきり分かる名前を付ける。これはほとんど努力がいらず、スピードアップにつながります。見た目で識別しやすくなり、ウィンドウズの検索機能で検索しやすくなります。
- コメントを使う。
通常多量のデータを扱わない場合でも、混乱はしやすいものです。このようなことが起こりやすいのは、ずっと昔に作りしばらく使わないでいたデータです。そのためにエクセルにはコメントという素晴らしい機能が付いています。
 The usefulness of comments |
コメント機能では次のことが使用できます:
- セルの内容について 説明が付けられる(例:i.e. Mr Doeによる単位原価の見積もり)
- その後シートを使うユーザーに対する注意を残せる(例:この計算は正しいか?... )
弊社のウェブアプリであるSalescastを使って、より精度の高い売上げ予測を入手してください。Lokadは需要予測を通して在庫最適化を行うことを専門としています。このチュートリアルの内容(およびそれ以上)は、Salescastの本来の特徴です。
はじめに:トレンドライン(趨勢曲線)を使った簡単な予測例
Viewing your data
弊社データ:― 最初の列は、類似製品の単位原価のデータを示しています。この単位原価は製品の品質に反映します。― 次の列には、販売された数量のデータが表されています。
弊社が知りたい情報:もし、弊社が別の製品を販売する場合、(単位原価150ドルとする)どれだけの売上げが期待できるか?
方法:これはいたってシンプルな方法を使います。単位原価と売上げの関係を数学的に見ていき、この関係性を使って予測をします。
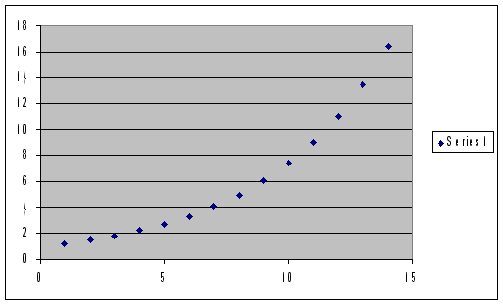
まずはじめに、データを目視するためにエクセルを使ってグラフ化します。ぱっと一目で見て分かることは傾向をつかむのに有用な手段です。
グラフ化するためにはデータを選択し、挿入>グラフ、そしてXY(散布図)オプションを選択します。私たちは売上げを品質の成果として見積もりたいので、単位原価を横軸(X)、売上げを縦軸(Y)にとります。
ここで、少し手を休めてグラフを見てみましょう:関係性は増加し、直線で伸びています。
関係性の正確につかむため、散布図を右クリックし、”近似曲線の追加”を選択しましょう。
 Creating a trendline |
ここで、私たちはデータに”フィット”(一番よく表している線)する関係性を選ばなくてはなりません。ここでまた私たちの目視が必要となります:この場合、点はほぼ直線に並んでいますので、”直線”を選択します。その後、その他の線―さらに複雑なものですが、より現実に沿ったもの―”例外”を使って微調整していきます。
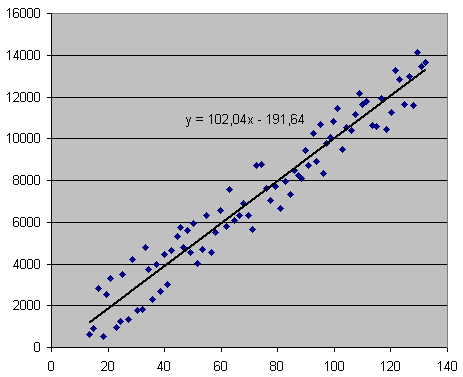
トレンドラインは図表で表されています。もう一度右クリックをすると関係性がよりはっきりわかります: Y=102.4X -191.64
理解した事項:販売した数量= 102.4 × 単位原価 - 191.64
つまり、もし単位原価$150で生産を決定すると、期待できる売上げ量はl 102.4 × 150 - 191.64 = 15168 個となります。
 A linear trendline |
まず、予測の第一ステップをクリアしました。
しかし、注意しなければならない点があります。それは、ソフトウェアは常に2つの列の関係性を見つけるということです ― それが実際にはどんなに弱い関係であってもです!そのため、ロバスト性をチェックすることが必要です。すぐにできるのは次のことです:
- 第一番目に、必ず散布図を目視すること。点がトレンドライン付近に散布している場合、上記の例にあるように、この関係性がロバストである可能性は高くなります。しかし、点がランダムに散在し、トレンドラインから離れているケースでは注意が必要です:相関性は弱く、評価された関係は盲目に信じてはいけません。
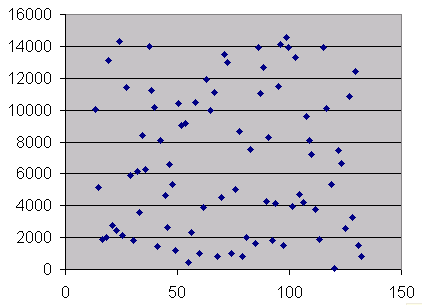 The dots are everywhere: no evident relationship, unreliable forecasts |
The dots "make sense", and allow more reliable forcasting |
- 図表を見た後、CORREL機能を使うことができます。この例では、この機能はCORREL(A2:A83,B2:B83)を読み取ります。もし、結果が0に近い場合、相関性は低く、結論は:単に傾向は見られないと言えます。逆に1に近い場合、関係性は強いと言えます。後者は発見した関係性を説明するのに有効となります。
微細な方法ですが、他にも相関性が高いことが分かる方法があります;これについては後ほど説明します。
もちろん、最後のステップは自動化されています:関係性を記録したり、電卓で計算する必要はありません。分析ツールパックがあるからです!
分析ツールパックを使った予測
先を急ぐ前に、Excel ATP (Analysis Tool Pack) がインストールされているかチェックしましょう。詳細は、分析ツールパックのインストールを参考にしてください。残念ながらこのように完璧な売上げデータがシンプルな直線関係であることは現実には稀です。複雑なデータのある難しいケースに対して、エクセルがどんな機能を備えているのか、見てみましょう。
次のステップ:指数関数的一致の例
ご想像される通り、会社データが常に直線的モデルであるとは限りません。事実、指数関数的モデルとしてとらえられざるを得ない理由がたくさんあります。多くの経済的活動は指数関数的方程式によって表されます。(例えば、複利計算は昔からある一般的なものです。)ここで指数関数的一致を見てみましょう:
1) データを見てください。簡単なグラフを描き、目視します。もしそれが指数関数的な変化をしているならこのように見えるはずです。
 perfect exponential shape |
Using trendlines |
それから、方程式を求めます。
2) 幸運にもこれらすべてのことが直接分析ツールパックを使って可能です:すべてのデータを新しいエクセルシートに移し、ツール=>データ分析を行います。
分析ツールパック(ATP)のインストール
ATPはエクセルへのアドイン型ツールですが、デフォルトでインストールされているとは限りません。インストールは、次の手順で行います。- マイクロソフト・オフィスのCDを手元に用意します。エクセルにATPファイルをインストールする際に必要となる場合があるからです。
- エクセル・シートを新規で開け、ツールメニューに行き、アドインを選択します。ウィンドウの一番始めのボックスをチェックし、 « Analysis ToolPack »とラベル付けします。
- マイクロソフト・オフィスCDを挿入するよう指示があれば、そのようにします。
- 以上です! « ツール » メニューに « データ分析 » オプションを含めた色々な機能が増えているのがお分かりでしょう。これが一番頻繁に使う機能なのです。
分析ツールパック(ATP)を使う
... 直線設定で使用する場合
ここでは、直線の例に戻って見てみることにしましょう。このデータを目視して « よさそう » であれば(上記の図を見てください)、 « トレンドライン »プロセスを経由せずに、ATPを使って関数形式の直接予測ができます。データシートを開き、« ツール » メニューを開け、« データ分析 »を選択します。ポップ・アップ・ウィンドウが現れ、どのような分析を行いたいのか聞かれます。直線設定では、« 回帰分析 » を選択します。
ここで、エクセルに二つの独立変数 « Y値域 » と « X値域 »を与える必要があります。Y値域は予測したい範囲を示し(例えば売上げ)、X値域はその売上げを説明するデータ(ここでは単位原価)を含みます。この例では(example.xlsをご覧ください)売上げデータはB列の3行目から90行目にあるので、Y値域として、« $B$3:$B$90 » のようにインプットし、X値域として «$A$3:$A$90 » とインプットする必要があります。その後、« OK »をクリックします。
« 回帰統計 »を含んだ新規シートが現れます。
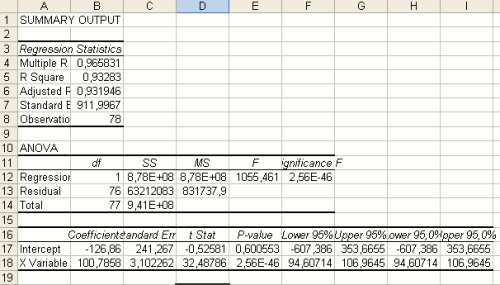 The Analysis ToolPack Output, in the case of an Ordinary Least Squares regression |
もっとも重要な結果はシートの下方の« 係数 » 列に含まれます。切片は一定で、« X値1 » 係数はXの係数(ここでは原価単位)になります。したがって、« トレンドライン » 機能を使って見つけた方程式と同じことが分かります。売上げ = 切片 + X係数 × 原価単位 = -126 + 100 × 原価単位
またこのシートには、予測がどれだけ正確なものかを教える有用な数値が含まれています。それは、« R2 »です。もしこれが1に近い場合、この予測は良いと言え、見つけた方程式はデータをよく表していると言えます。もしこの数値0に近い場合、予測はあまりよいものと言えません。この場合は別の一致(以下の指数関数一致をご参照ください)を試してみるとよいでしょう。
この方法はおそらく« トレンドライン » のテクニックを使ったものより迅速でしょう。しかし、これでは少し専門的過ぎて一目了然とは言えません。なので、もしデータのグラフを描いて凝視するのが面倒という場合は、最低でもこちら « R2 » の値を見てください。
... 指数関数的一致で使う場合
直線設定でうまくいかない場合(例えばR2の値が0.1などと低い場合)指数関数的一致を試してみましょう。通常の手順通り分析ツールパックを開始し、データシートを開け、« ツール »メニューに行き、« データ分析 »を選択します。ポップアップ・ウィンドウが現われ、どの分析を行うか聞かれます。
指数関数的設定では« 指数平滑 »を選択します。
エクセルはインプットの範囲を聞いてくるだけです。予測したいデータを含む列を選択し(例えば単位原価)“smoothing factor”を選びます。