Por Joannes Vermorel, diciembre de 2022El término Inteligencia de negocios (Business Intelligence o BI) hace referencia a una clase de software empresarial dedicado a la elaboración de informes analíticos basados principalmente en los datos transaccionales recopilados a través de los diferentes sistemas empresariales que usa la compañía para operar. La BI está diseñada para ofrecer funciones de generación de informes autoservicio a los usuarios que no especializados en TI. Estas funciones autoservicio pueden abarcar desde el ajuste de parámetros en informes existentes hasta la creación de informes desde cero. La mayoría de las grandes empresas cuentan con al menos un sistema de BI operativo que se agrega a sus sistemas transaccionales y que a menudo incluyen un ERP.
Origen y motivos
El informe analítico moderno nació con los primeros pronosticadores económicos
[1] [2], en particular en Estados Unidos, a comienzos del siglo XX. Esta primera versión resultó ser extremadamente popular, lo que le valió la atención de los principales medios de comunicación y una amplia circulación. Esta popularidad demostró que había un profundo interés por los informes cuantitativos con alta densidad de información. Durante los 80, muchas grandes empresas comenzaron a conservar sus transacciones comerciales en forma de registros electrónicos, almacenados en bases de datos transaccionales, que generalmente hacían uso de algunas de los primeros
sistemas de planificación de recursos empresariales (ERP). Estos ERP estaban pensados principalmente para optimizar procesos existentes, mejorando la productividad y la fiabilidad. Sin embargo, muchos advirtieron el enorme potencial desaprovechado de estos registros y, en 1983, SAP presentó el ABAP
[3], un lenguaje de programación dedicado a la generación de informes basados en los datos recopilados dentro del ERP.
No obstante, los sistemas de bases de datos relacionales que se vendían en los 80 presentaban dos limitaciones importantes en la producción de informes analíticos. La primera era que solo especialistas en TI muy capacitados podían encargarse del diseño de los informes. Esto hacía que el proceso resultara lento y costoso, lo que limitaba enormemente la diversidad de informes que podían introducirse. La segunda era que la generación de los informes era muy pesada para el hardware informático. Los informes generalmente se elaboraban solo durante la noche (y en lotes), cuando las operaciones de la empresa cesaban. En cierta medida, esto reflejaba las limitaciones del hardware informático de la época, pero también reflejaba limitaciones de
software.
A principios de los 90, los progresos en el hardware informático permitieron el surgimiento de otro tipo de soluciones de software
[4]: las soluciones de
Inteligencia de negocios. El costo de la RAM (memoria de acceso aleatorio) había ido
disminuyendo constantemente, mientras que su capacidad de almacenamiento había ido
creciendo de modo igualmente constante. Como resultado, el almacenamiento de una versión especializada y más compacta de datos de negocios
en memoria (RAM) para el acceso inmediato se volvió una solución viable, tanto desde el punto de vista tecnológico como económico. Estos desarrollos resolvieron las dos principales limitaciones de los sistemas de generación de informes que se habían implementado una década antes: los front-ends del nuevo software eran mucho más accesibles para quienes no eran especialistas, mientras que los back-ends —con tecnologías OLAP (que veremos más adelante)— eliminaron algunas de las limitaciones informáticas más significativas. Gracias a estos avances, para el final de la década, las soluciones de BI se habían vuelto moneda corriente entre las grandes empresas.
Con el progreso continuo del hardware informático, surgió una nueva generación de herramientas de BI
[5] a fines de los años 2000. Los sistemas de bases de datos relacionales de los 80 que eran incapaces de elaborar informes oportunamente se fueron volviendo, a partir de los años 2000, cada vez más capaces de mantener el historial transaccional completo de una empresa en RAM. Como resultado, las consultas analíticas complejas podían completarse en segundos
sin un back-end OLAP dedicado. Así, el foco de las soluciones de BI pasó al front-end, ofreciendo interfaces de usuario web cada vez más accesibles —principalmente SaaS (software como servicio)— y presentando al mismo tiempo paneles de información cada vez más interactivos que aprovechaban la versatilidad del back-end relacional.
OLAP y los cubos multidimensionales
OLAP es la sigla de
procesamiento analítico en línea, y está asociado con el diseño del
back-end de una solución de BI. El término, acuñado en 1993 por Edgar Codd, da nombre a una serie de ideas de diseño de software
[6], muchas de las cuales son anteriores a los 90, y algunas son incluso de los 60. Estas ideas de diseño fueron fundamentales para el surgimiento de la BI como clase distintiva de productos de software en los años noventa. OLAP respondía al desafío de poder elaborar informes analíticos nuevos
en tiempo breve, incluso cuando la cantidad de datos involucrada en la elaboración del informe era demasiado grande para procesarse rápidamente.
La técnica más sencilla para elaborar un informe analítico nuevo implica la
lectura de los datos al menos una vez. Sin embargo, si el conjunto de datos es tan grande
[7] que leerlo en su totalidad llevaría horas (si no días), elaborar un informe nuevo también requerirá horas o días. Por eso, para elaborar un informe actualizado en segundos, la técnica no puede requerir la relectura de todo el conjunto de datos cada vez que se solicita una actualización del informe.
OLAP propone aprovechar estructuras de datos más pequeñas y compactas, que reflejan los informes de interés. Estas estructuras de datos específicos están pensadas para actualizarse de forma incremental a medida que aparecen nuevos datos. Así, cuando se solicita una actualización de un informe, el sistema de BI no tiene que releer todo el conjunto de datos históricos, sino solo la estructura de datos compacta que contiene toda la información necesaria para generar el informe. Además, si la estructura de datos es lo suficientemente pequeña, puede almacenarse en memoria (RAM) y, por lo tanto, es posible acceder a ella más rápidamente que si estuviera en el almacenamiento definitivo usado para los datos transaccionales.
Pensemos en el siguiente ejemplo: imaginemos una red minorista de 100 hipermercados. El director financiero quiere un informe con las ventas totales en euros por tienda por día de los últimos tres años. Los datos de ventas históricas sin procesar de los últimos tres años representan más de 1000 millones de líneas de datos (cada código de barras escaneado en cada tienda durante este período), y más de 50 GB en su formato tabular sin procesar. Sin embargo, una tabla de 100 columnas (1 por hipermercado) con 1095 líneas (3 años * 365 días) da un total de menos de 0,5 MB (a un ritmo de 4 bytes por número). Además, cada vez que se produce una transacción, las celdas correspondientes en la tabla pueden actualizarse de consecuencia. Crear y mantener una tabla de este tipo ilustra cómo funciona un sistema OLAP.
Las estructuras de datos compactas que describíamos antes generalmente adoptan la forma de un
cubo OLAP, también llamado cubo multidimensional. Las celdas existen en el cubo en la intersección de las dimensiones discretas que definen la estructura global del cubo. Cada celda contiene una medida (o valor) extraída de los datos transaccionales originales, a los que a menudo se llama
tabla de hechos. Esta estructura de datos es similar a los conjuntos multidimensionales que se encuentran en la mayoría de los lenguajes de programación más conocidos. El cubo OLAP se presta a operaciones eficientes de proyección o agregación a lo largo de las dimensiones (como la suma o el promedio), dado que el cubo se mantiene lo suficientemente pequeño como para caber en la memoria de una computadora.
Generación de informes y visualización de datos interactivos
Permitir que usuarios no especialistas de TI pudieran acceder a las funciones de generación de informes fue la principal motivación para la adopción de herramientas de BI. Así, la tecnología adoptó un diseño WYSIWYG (
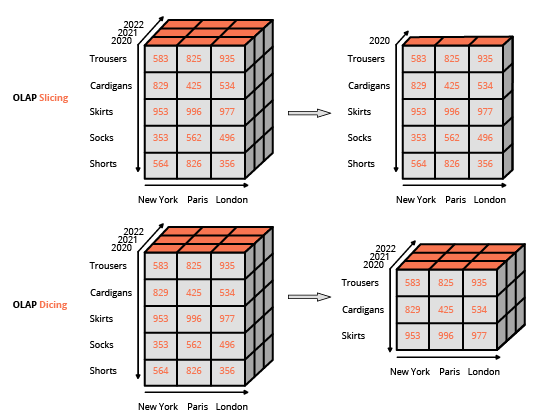
lo que ves es lo que obtienes), valiéndose de interfaces de usuario muy completas. Este enfoque difiere del modo habitual de interacción con una base de datos relacional, que consiste en la composición de consultas usando un lenguaje especializado (como SQL). La interfaz habitual para manipular un cubo OLAP es una interfaz de matriz, como las tablas dinámicas en un programa de hoja de cálculo, que permite a los usuarios aplicar filtros (lo que se denomina
slice and dice o "segmentar y desglosar" en terminología BI) y realizar agregaciones (promedio, min, max, sum, etc.).
Con excepción de los casos de procesamiento de conjuntos de datos particularmente grandes, la necesidad de utilizar cubos OLAP fue disminuyendo a fines de los años 2000, en paralelo con los pasos agigantados que se dieron en el hardware informático. Se introdujeron nuevas herramientas de BI "finas" con un enfoque exclusivo en el front-end. Las herramientas de BI finas estaban diseñadas principalmente para interactuar con bases de datos relacionales, a diferencia de sus predecesoras ".gruesas", que aprovechaban back-ends integrados con cubos OLAP. Esta evolución fue posible gracias a que las bases de datos relacionales de esa época generalmente permitían la ejecución de consultas complejas en todo el conjunto de datos en segundos, siempre que la dimensión del conjunto de datos estuviera por debajo de un cierto límite. Las herramientas de BI finas pueden verse como editores WYSIWYG unificados para los diferentes dialectos de SQL que admitían. (De hecho, en la estructura, estas herramientas de BI generan consultas SQL). El principal desafío técnico fue la optimización de las consultas generadas, para minimizar el tiempo de respuesta de la base de datos relacional subyacente.
Las funciones de
visualización de datos de las herramientas de BI consistían principalmente en la presentación de datos al cliente, ya fuera a través de computadoras de escritorio o de aplicaciones web. Las funciones de presentación progresaron de forma constante hasta los primeros años 2000, cuando el hardware de usuario final (por ejemplo, estaciones de trabajo y computadoras portátiles) comenzaron a superar ampliamente (en términos computacionales) lo que se necesitaba para la visualización de datos. Hoy en día, incluso las visualizaciones de datos más elaboradas son procesos livianos, empequeñecidos en escala en cuanto al consumo de recursos computacionales asociados con la extracción y la transformación de los datos subyacentes que se visualizan.
El impacto organizativo de la BI
Mientras que la facilidad de acceso ha sido un factor decisivo para la adopción de la mayoría de las herramientas de BI, navegar por el entorno de datos de grandes empresas, en cambio, resulta difícil, aunque más no sea por la mera diversidad de los datos disponibles. Además, aunque la herramienta de BI sea relativamente accesible, la lógica de generación de informes que las empresas implementan a través de las herramientas de BI tiende a reflejar la complejidad del negocio y, como resultado, la lógica en sí puede ser mucho menos accesible que la herramienta que respalda su ejecución.
Esto hace que la adopción de herramientas de BI lleve —en la mayoría de las grandes empresas— a la creación de equipos de analíticas dedicados, que generalmente operan como función de respaldo del Departamento de TI. Como pronosticaba la Ley de Parkinson (
el trabajo se expande hasta llenar el tiempo disponible para terminarlo), estos equipos tienden a ocupar cada vez más tiempo, a la par de la cantidad de informes generados, independientemente de los beneficios que obtenga la empresa (percibidos o reales) del acceso a dichos informes.
Límites técnicos de la BI
Como a menudo sucede, se produce una compensación entre las virtudes de las herramientas de BI, es decir, que una mayor facilidad de acceso va en detrimento de la
expresividad. En este caso, las transformaciones aplicadas a los datos se limitan a una clase relativamente limitada de filtros y agregaciones. Esta es la primera limitación importante, ya que muchas —si no la mayoría— de las cuestiones comerciales no pueden abordarse con esos operadores (por ejemplo,
¿cuál es el riesgo de rotación de un cliente?). Desde luego,
es posible introducir operadores avanzados en la interfaz de usuario de BI, pero este tipo de funciones "avanzadas" van en contra
[8] del objetivo inicial de hacer que la herramienta sea accesible para los usuarios no especializados. Así, el diseño de consultas avanzadas de datos no difiere del desarrollo de software, una tarea que resulta difícil por naturaleza. Como dato anecdótico, la mayoría de las herramientas de BI permite escribir consultas "básicas" (generalmente en SQL o en un dialecto de este tipo), recurriendo de nuevo a los pasos técnicos que se suponía que la herramienta eliminaría.
La segunda principal limitación es el
rendimiento. Esta limitación se presenta en dos formas diferentes, dependiendo de si las herramientas de BI son finas o gruesas. Las herramientas de BI finas generalmente incluyen una lógica sofisticada para optimizar las consultas de base de datos que generan. Sin embargo, estas herramientas están, en última instancia, limitadas por el rendimiento que pueden ofrecer las bases de datos que sirven de back-end. Una consulta aparentemente simple puede resultar ineficiente a la hora de la ejecución, lo que lleva a tiempos de respuesta prolongados. Esto es algo que un ingeniero de base de datos puede abordar modificando y mejorando la base de datos. Sin embargo, también en este caso la solución va en contra del objetivo inicial de hacer que la herramienta de BI sea accesible para los usuarios no especializados.
Las herramientas de BI gruesas tienen una limitación en su rendimiento debida al diseño de los cubos OLAP en sí. En primer lugar, la cantidad de RAM necesaria para mantener un cubo multidimensional en la memoria escala rápidamente a medida que las dimensiones del cubo aumentan. Incluso una cantidad moderada de dimensiones (por ej., 10) puede acarrear serios problemas asociados con la memoria que ocupa el cubo. En general, los diseños en memoria (siendo los cubos OLAP los más habituales), tienden a presentar problemas relacionados con la memoria.
Además, el cubo es una representación de los datos transaccionales originales
con pérdidas: ningún análisis que se haga con el cubo puede recuperar información que ya se hubiera perdido. Recordemos el ejemplo del hipermercado. En una situación de ese tipo, los carritos de compras no pueden representarse en un cubo. Por lo tanto, la información "comprados juntos" se pierde. El diseño de "cubo" global de OLAP limita significativamente los datos que pueden siquiera representarse; sin embargo, es esta misma limitación la que hace posible la propiedad "en línea".
Limitaciones comerciales de la BI
La introducción de herramientas de BI en una empresa es menos transformadora de lo que podría parecer. En palabras simples, elaborar números, de por sí, no genera valor para la empresa si no se actúa en función de esos números. El diseño mismo de las herramientas de BI pone el énfasis en una elaboración "ilimitada" de informes, pero el diseño no respalda ningún curso de acción real. De hecho, en la mayoría de las situaciones, la poca expresividad de las herramientas de BI resulta ser demasiado limitadora ante cualquier intento de automatización basada en los informes de BI.
Además, la herramienta de BI tiende a exacerbar las tendencias burocráticas ya presentes en las grandes empresas. A título anecdótico, a menudo bastan unos números aproximados y un buen juicio para establecer las prioridades de una empresa. Sin embargo, la existencia de una herramienta analítica autoservicio —como la BI— ofrece una enorme oportunidad para procrastinar y complicar las cosas con un flujo incesante de métricas cuestionables y que no se traducen en acciones.
Las herramientas de BI son susceptibles a las desventajas del
diseño por comité, donde las ideas de todos se incluyen en el proyecto. La naturaleza autoservicio de la herramienta enfatiza un ENFOQUE ampliamente inclusivo a la hora de introducir nuevos informes. Como resultado, la complejidad del entorno de generación de informes tiende a crecer con el tiempo, independientemente de la complejidad del negocio que esos informes en teoría deberían reflejar. El término
métricas de vanidad se ha vuelto popular para hablar de métricas como estas —generalmente implementadas a través de una herramienta de BI—, que no contribuyen a las ganancias de una empresa.
La solución de Lokad
Considerando las capacidades del hardware informático moderno, usar un sistema de generación de informes para elaborar un millón de números por día es sencillo; elaborar
10 números por día que valgan la pena leer, no lo es tanto. Si bien una herramienta de BI usada en pequeñas dosis resulta provechosa para la mayoría de las empresas, en dosis mayores se vuelve tóxica.
En la práctica, es limitada la cantidad de datos clave que pueden obtenerse de la BI. Por cada nuevo informe que se genera, la cantidad de datos nuevos o mejores que se obtiene es cada vez menor. Recordemos que el detalle de las analíticas de datos a los que se puede acceder desde una herramienta de BI es
limitado por diseño, ya que las consultas deben seguir resultando de fácil acceso para las personas no especializadas en toda la interfaz de usuario.
Además, incluso cuando se adquiera un nuevo dato clave, esto no implica que la empresa podría traducirlo en acciones. La BI es, en esencia, una tecnología de
generación de informes: no pone el foco en ninguna llamada a la acción para la empresa. El paradigma de la BI no está orientado a la automatización de las decisiones de negocios (ni siquiera las más rutinarias).
La
plataforma de Lokad ofrece funciones de generación de informes a medida, como la BI. Sin embargo, a diferencia de la BI, Lokad tiene como objetivo la optimización de las decisiones de negocios, específicamente las que tienen que ver con la cadena de suministro. En la práctica, recomendamos contar con un
Supply Chain Scientist que se encargue del diseño, y el posterior mantenimiento, de la receta numérica que genera —a través de Lokad— las decisiones de cadena de suministro de interés
Referencias
1. Fortune Tellers: The Story of America's First Economic Forecasters, de Walter Friedman (2013).
2. A Selection of Early Forecasting & Business Charts, de Walter Friedman (2014) (PDF)
3. ABAP es un lenguaje de programación presentado por SAP en 1983, cuya sigla corresponde a Allgemeiner Berichts-Aufbereitungs-Prozessor, que en alemán significa "procesador de preparación de informes generales''. Este lenguaje se introdujo como precursor de los sistemas de BI para complementar el ERP (también llamado SAP) con funciones de generación de informes. El objetivo de ABAP era aliviar la sobrecarga de ingeniería que implicaba la implementación de informes personalizados. En los 90, ABAP se rediseñó como un lenguaje de configuración y extensión para el ERP mismo. Al lenguaje se lo redenominó Advanced Business Application Programming (Programación avanzada de aplicaciones de negocio) para reflejar este cambio de enfoque.
4. BusinessObjects, fundado en 1990 y comprado por SAP en 2008, es el arquetipo de las soluciones de BI que surgieron en los 90.
5. Tableau, fundado en 2003 y comprado por Salesforce en 2019, es el arquetipo de las soluciones de BI que surgieron a partir de los años 2000.
6. The origins of today’s OLAP products (El origen de los productos OLAP de hoy), Nigel Pendse, última actualización de agosto de 2007,
7. El hardware informático ha ido avanzando sin cesar desde los 50. Sin embargo, cuanto más económico se volvía elaborar más datos, más económico se volvía también almacenar más datos. Como resultado, desde los 70, la cantidad de datos de negocios ha ido creciendo casi tan rápidamente como las capacidades del hardware informático. Por eso, la noción de "demasiados datos" resulta ser un blanco móvil.
8. A fines de los años noventa y principios de los años 2000, muchas empresas de software intentaron —sin lograrlo— reemplazar los lenguajes de programación con herramientas visuales. Vea también Lego Programming (Programación de Lego) de Joel Spolsky, diciembre de 2006