従来型予測による最初の報告書
ホーム » Salescast » このページ
統計学とは、反直感的な科学です。従って、統計学のウェブアプリとしてのSalescastは、不可解な結果を出す傾向にあります。ここでは、従来型の予測、つまり、通常の毎日、毎週、毎月の予測に焦点を当ててみようと思います。
ここでは一般にSalescastが在庫最適化ツールとしてではなく、需要予測ツールとして利用される場合の従来型予測に焦点を当てています。なお、クォンタイル予測となると大幅に違っており、これは主に在庫最適化が目的となっています。
始める前に
この段階では、既にSalescastを使い始めることが出来ており、Salescastにて最初のMicrosoft Excelレポートを作成したものと想定します。特定の列の解釈について疑問がおありであれば、こちら関連文書をご参照ください。また、インプットデータが正確であったか再度確認することをお勧めします。一般に、既存の企業のシステムで得られた数値と、Salescastが報告した過去の数値とを比較し確認なさってください。バックテストおよびモデルの選択
実際の予測に関して論ずる前に、簡単にどのようにしてSalescastが予測を作成するのか見てみましょう。私どもの予測エンジンは、単純なものから非常に複雑なモデルに至るまで幅広い大規模な予測モデルのライブラリーを包有しています。それぞれの時系列において、Salescastはバックテストを実施します。つまり、過去にさかのぼり、データを切り取り、その切り取ったデータのみを使って予測を作成し、その結果の精度を測ります。過去のデータが適応できる期間に応じて、日、週、月の時系列にて同じ作業を繰り返します。最終的に、それぞれの時系列およびモデルに対して、予測エンジンは精度測定のための一式を取り揃えることになり、これによって最も精度の高い予測モデルを選ぶことができるのです。 この選択メカニズムは厳密にパフォーマンス主導となります。たとえば、論理的には季節性モデルは製品Xに適用されねばならない、と言うことはありません。季節性モデルは予測エンジンの中に偶然にして存在するのであって、このモデルが他のモデルに対して優れている時においてのみ、選ばれるのです。
平坦な予測と不規則な過去
ほとんどの場合、過去のデータは比較的不規則であり、特にSKUや製品など細分化したレベルで見た場合、顕著です。下のグラフにおいて、青線は時系列のサンプルです。赤線はこの時系列の暫定的な予測を表しています。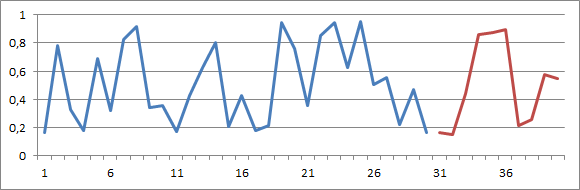
この予測は、視覚的には過去に観察された変動を再現しており、良さそうに思われます。しかしながら、統計的観点からは、この予測は大幅に不正確なのです。時系列は0から1の間のランダムな数値によって構成されています。ここには、何ら学ぶべきパターンはなく、ただのノイズでしかありません。
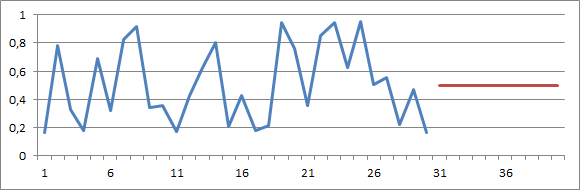
上のグラフでは、予測を修正してみました。今度は0.5での平坦な線です。視覚的には、この予測は過去と見比べ奇妙に映るでしょう。データでは観察されていない、規則性が存在しているのですから。しかしながら統計学的な見地では、この予測は先程の予測に比べ、 一層精確なのです。
この見解は実際に統計の一般的な(ただし、直感的ではない)側面です。過去の需要がより不規則であればある程、予測はなだらかなものとなるのです。これと違った動きをするのであれば、どんな予測システムであっても実際には精度に劣ることになります。
簡単ながら効率良い予測モデル
予測エンジンは非常に複雑なモデルを含有していますが、時によっては特定のデータセットにおいて(モデル選択過程において、他のモデルに比べて優れている時)非常に簡単なモデルが適用されることもあります。多くの例がありますが、ここでは以下モデルの例をご紹介します。
- 最終期間横ばい(週間あるいは月間予測): 予測は最終週あるいは最終月に観察された値を一様に繰り返す。
- 一年間の季節性(週間あるいは月間予測): 予測はきっかりと一年前に観測された値を繰り返す(それぞれ12ヶ月前、或いは52週間前)。
- 一週間サイクル(日間予測): 予測はきっかりと一週間前に観測された値を繰り返し、曜日パターンが合致。
- 年間平均横ばい(週間あるいは月間予測): 予測は一様に昨年に渡り平均した過去の需要を繰り返す。
このモデルのどれを予測に使ったとしてもper se(それ自体)には問題はありません。チャレンジは、簡単なモデルに対していつより複雑なモデルを使用すべきなのか知ることであり、だからこそ、Salescastのバックテストはそれほど重要なことなのです。
いずれにせよ、お客様の観点からすれば、平坦な予測 - 特に12ヶ月先の予測 - は往々にして期待外れと見なされます。たとえば、ビジネス専門家によって期待される季節性パターンがSalescastの報告した値に見いだせなかった時。しかしながら、私どもの予測エンジン多くの季節性モデルをそろえており、こういったモデルは常にベンチマークされているのです。従って、非季節性モデルが選ばれたということは、他の全ての季節性モデルをもってしても、このモデルが定量的に優れていたということなのです。こういった場合に、季節性パターンを強要することは、精度を劣らせることにしかならないのです。もちろん、それ自体が非常に直感的ではないことはお察しの通りです。
精度の列
The 精度の列はオプションとなり、デフォルトの段階では機能は作動していません。これは従来型予測の見込まれる予測エラー率を表します。これはシステムの自己診断機能と考えていただいて良いと思います。この精度インディケーターの精度の定義といった専門的な詳細に入らずに、100%の時に予測は完全に正確であり、0%の時には予測が完全に不正確であることになるとだけ申し上げておきます。予測プロセス(統計的にしろ、そうでないにしろ)において、100%の精度とは現実的な期待とはなりません。特に、売上ボリュームが低い場合、+1または-1といった小さな誤りがパーセントで表される精度を既に50%以下に比べ下げています。直感とは反して、精度の全体的なレベルは予測手法の結果ではなく、データそのものの集合体のレベルによるものなのです。
たとえば、全国規模で毎日の電力消費量を予測したとしましょう。99.5%の精度の予測は比較的劣ったものと見なされると思います。一方、生鮮食品のバーゲンセールの予測売上となれば、30%の精度が重大な成果と見なされるかもしれません。しかしながら、ましな予測ソリューションが状況を改善できないとはならないのです。
予測ということになれば、絶対的に良いあるいは悪い予測はないのです。唯一重要なことは、この予測は現状あるいは選択肢に比べて、どれ程良いのかということになります。
Salescastを選ぶ


Salescastを使い始める
- スクリーンショット
- Excelのサンプルレポート
- チュートリアル
- TSVファイルのインポート(英文) + sample-TSV.zip
- 在庫切れが予測に齎すバイアスを管理する
- 毎日、週間、月間集計
- REST APIで自動化(英文)
ユーザーガイド
お客様の声
他の例もこちらでご覧になれます。