Por Joannès Vermorel, diciembre de 2007 (última revisión: enero de 2012)El stock de seguridad es un método de optimización del inventario que indica cuánto inventario debe almacenarse por sobre la demanda esperada para lograr un determinado nivel de servicio objetivo. El stock adicional actúa como
buffer de "seguridad" —de ahí su nombre— para proteger a la empresa contra fluctuaciones futuras esperadas. La fórmula del stock de seguridad depende tanto de la demanda futura esperada como del tiempo de entrega futuro esperado. Y se supone que la incertidumbre se distribuirá de manera normal en ambos factores. La fórmula del stock de seguridad está presente en la mayoría de los sistemas de gestión del inventario, incluidos los ERP y los MRP más conocidos.
Actualización de julio de 2020: El método detallado a continuación es el de una cadena de suministro "de manual"; lamentablemente, también resulta ser muy disfuncional. En especial, ni la demanda futura ni el tiempo de entrega futuro se distribuyen de forma normal (es decir, no son gaussianas). Además, el método no entiende que todas las SKU que la empresa puede pedir o fabricar compiten por los mismos recursos. Recomendamos vivamente no utilizar el modelo de stock de seguridad para las cadenas de suministro reales.
Público destinatario: Este documento está dirigido principalmente a los profesionales de la cadena de suministro en distribución o en fabricación. Aún así, este documento también es útil para editores de software de contabilidad/ERP/eCommerce que deseen ampliar sus aplicaciones con funciones de gestión de stock.
Hemos intentado mantener los requisitos matemáticos al mínimo indispensable pero, aún así, no podemos eludir las fórmulas por completo, ya que el propósito de este documento es precisamente ser una guía práctica que explique cómo calcular el stock de seguridad.
Descargar: calculate-safety-stocks.xls (Hoja de cálculo de Microsoft Excel)
Introducción
La gestión del inventario es una
compensación financiera entre los costos de inventario y los costos de desabastecimientos. Cuanto más stock, mayor será el capital de trabajo necesario y mayor será la depreciación de las existencias. Por otro lado, si no cuenta con suficiente stock, se producen desabastecimientos que hacen que se pierdan potenciales ventas, posibilidad que interrumpe el proceso de producción completo.
Los stocks en el inventario dependen esencialmente de dos factores:
- demanda de tiempo de entrega: la cantidad de artículos que serán consumidos o comprados.
- lead time o tiempo de entrega: el tiempo transcurrido entre la decisión de reorden y la nueva disponibilidad.
Aún así, estos dos factores están sujetos a incertidumbres:
- variaciones de la demanda: el comportamiento de los clientes puede evolucionar en modos impredecibles.
- variaciones del tiempo de entrega: los proveedores o los transportistas pueden verse frente a dificultades inesperadas.
Decidir el nivel de stock de seguridad es equivalente en forma implícita a hacer concesiones entre los costos considerando las incertidumbres.
El equilibrio costes de inventario vs. costes de desabastecimientos depende mucho de la actividad. Así, en lugar de considerar los costos directamente, presentaremos ahora la noción clásica de
nivel de servicio.
El
nivel de servicio expresa la probabilidad de que un determinado nivel de stock de seguridad no derive en un desabastecimiento. Por supuesto, cuando se aumenta el stock de seguridad, el nivel de servicio también aumenta. Cuando el stock de seguridad son muy grandes, el nivel de servicio tiende hacia el 100 % (es decir, cero probabilidad de enfrentarse a un desabastecimiento).
Elegir el nivel de servicio, es decir, la probabilidad aceptable de que se verifiquen faltas, excede el objetivo de esta guía. No obstante, hemos delineado una guía separada sobre el
cálculo de los niveles de servicio óptimos.
Modelo de reposición de inventario
El punto de reorden es la cantidad de stock que debería llevar a realizar una orden.
Si no existieran incertidumbres (por ejemplo, si la demanda futura fuera conocida a la perfección y el suministro fuera perfectamente confiable), el punto de reorden sería igual al total de la demanda pronosticada durante el tiempo de entrega, también llamada
demanda de tiempo de entrega (lead time demand). En la práctica, debido a las incertidumbres, tenemos
punto de reorden = demanda de tiempo de entrega (lead time demand) + stock de seguridadSi suponemos que los pronósticos no presentan
sesgos (estadísticamente hablando), tener cero stock de seguridad llevaría a un nivel de servicio del 50 %. De hecho, los pronósticos sin sesgos significan que existen iguales posibilidades de que la demanda futura sea mayor o menor que la demanda de tiempo de entrega (recuerde que la demanda de tiempo de entrega es sólo un valor pronosticado).
Atención: los pronósticos pueden no presentar sesgos y aún así no ser exactos. El sesgo indica un error sistemático por parte del modelo de pronóstico (ej. sobrestimar la demanda siempre en un 20 %).
Distribución normal de error
En este punto, necesitamos un modo de representar la incertidumbre en la demanda de tiempo de entrega. En el caso a continuación, supondremos que el error se distribuye normalmente. Vea la imagen a continuación.
 Notas estadísticas
Notas estadísticas: este supuesto de distribución normal no es totalmente arbitrario. En ciertas circunstancias, los estimadores estadísticos convergen en una distribución normal como se delinea en el teorema del límite central. Sin embargo, esas consideraciones exceden el objetivo de esta guía.
Una distribución normal sólo se define por dos parámetros: su media y su varianza. Debido a que suponemos que los pronósticos no presentan sesgos,
suponemos que la media de distribución de error es cero, lo que no significa que estemos asumiendo que el error sea cero.
Determinar la varianza del error de pronóstico es una tarea más delicada. Lokad, como kit de herramientas de pronóstico, proporciona
cálculos MAPE (error absoluto medio relativo) asociados con sus pronósticos. Por motivos de compleción, explicaremos cómo se puede utilizar la heurística simple para resolver este problema.
En particular,
se puede utilizar la varianza dentro de los datos históricos como un buen heurístico para calcular la varianza de error del pronóstico.
David Piasecki también sugiere el uso de la demanda pronosticada en lugar de la demanda media en la expresión de varianza, es decir
σ2 = E[ (yt - y')2 ]
donde
E es el operador
medio,
yt es la demanda histórica para el período
t (generalmente la cantidad de ventas) y
y' es la demanda pronosticada.
La idea clave detrás de este supuesto es que el error del pronóstico a menudo se correlaciona con la cantidad de varianza esperada:
cuanto mayores sean las varianzas futuras, mayor será el error de los pronósticos.En realidad, el cálculo de esta varianza de error implica algunas sutilezas que serán tratadas con mayor detalle a continuación.
Expresión de stock de seguridad
En este punto, hemos determinado tanto la media como la varianza, por lo que la distribución del error es conocida. Debemos calcular ahora el nivel de error
aceptable dentro de esta distribución de error. Aquí arriba hemos presentado la noción de nivel de servicio (un porcentaje) para hacerlo.
Notas: Estamos suponiendo un tiempo de entrega
estático. No obstante, se puede utilizar un abordaje similar para un tiempo de entrega variable. Ver:
Para convertir el nivel de servicio en un
nivel de error, también llamado
factor de servicio, debemos utilizar la
distribución normal acumulativa inversa (también llamada distribución normal inversa) (vea
NORMSINV para ver la función de Excel correspondiente). Debido a que puede sonar complicado —si bien no lo es—, le sugerimos que vea el
applet de distribución normal para tener un panorama más visual. Como puede ver, la función acumulativa transforma el porcentaje en un
área bajo la curva, siendo el umbral del eje X correspondiente al valor del factor de servicio.
En forma intuitiva, calculamos
stock de seguridad = sesgo de error estándar * factor de servicioEn modo más formal, tomemos
S como la existencia de seguridad, y entonces tenemos
S = σ * icdf(P)
donde
σ es el sesgo estándar (es decir, la raíz cuadrada de
σ2 la varianza definida arriba),
cdf es la distribución acumulativa normal
normalizada (media cero y varianza igual a uno) y
P, el nivel de servicio.
Recordando que
punto de reorden = demanda de tiempo de entrega + stock de seguridad
R será el punto de reorden,y así tenemos
R = y' + σ * icdf(P)Haciendo coincidir el tiempo de entrega con el período de pronóstico
Hasta ahora, simplemente hemos supuesto que para un determinado
tiempo de entrega, podíamos producir directamente un pronóstico de demanda futura correspondiente. En la práctica, no funciona exactamente así.
El análisis de los datos históricos generalmente comienza con el agregado de los datos dentro de períodos de tiempo (en general semanas o meses).
Aún así, el período elegido puede no coincidir exactamente con el tiempo de entrega; así, se necesitan algunos cálculos adicionales para expresar la demanda de tiempo de entrega y su varianza asociada (considerando que aún suponemos una distribución normal para el error de pronóstico como se detalló en la sección anterior).
En forma intuitiva,
la demanda de tiempo de entrega puede calcularse como la suma de los valores pronosticados para los períodos futuros que corta el segmento de tiempo de entrega. Se debe prestar especial atención para ajustar adecuadamente el último período pronosticado.
Formalmente, tomemos
T como el período y
L como el tiempo de entrega. Escribimos
L = k * T + α * T
donde
k es un número entero y
0 ≤ α < 1.
D será la demanda de tiempo de entrega. Luego, tenemos la expresión final para la demanda de tiempo de entrega
D = (Σt=1..k y't) + αy'k+1
donde
y'n es la demanda pronosticada para el período
n en el futuro.
Considerando los mismos supuestos de distribución normal, podemos calcular la varianza de error del pronóstico como
σ2 = E[ (yt - y')2 ]
donde
y' es el pronóstico promedio por período
y'= D / (k + α)Aún así,
σ2 se calcula aquí como una
varianza por período mientras que nosotros necesitaríamos una varianza que se corresponda con el tiempo de entrega.
σL2 será la
varianza por tiempo de entrega ajustada, y así tenemos
σL2 = (k + α) σ2Finalmente, podemos volver a expresar el tiempo de reorden como
R = D + σL * cdf(P)Uso de Excel para calcular el punto de reorden
Esta sección detalla
cómo calcular el punto de reorden con Microsoft Excel. Le sugerimos que mire la
hoja de cálculo de Excel de ejemplo que proporcionamos.
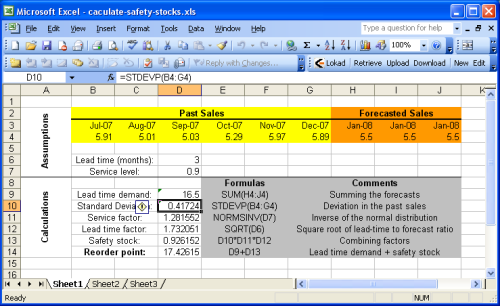
La hoja de ejemplo se divide básicamente en dos secciones: los
supuestos (assumptions) en la parte superior y los
cálculos (calculations) en la parte inferior. Se supone que los pronósticos son una parte de los supuestos debido a que el pronóstico de las ventas (o la demanda) excede el objetivo de esta guía. Puede consultar nuestro
tutorial para pronóstico de ventas con Microsoft Excel para más detalles.
La mayoría de las fórmulas presentadas en la sección anterior son operaciones bastante básicas (sumas, multiplicaciones) que son muy fáciles de realizar con Microsoft Excel. Aún así, vale la pena destacar dos funciones:
NORMSINV (Microsoft KB): calcula la distribución normal acumulativa, llamada cdf arriba.STDEV (Microsoft KB): calcula el sesgo estándar, llamada σ arriba. Recordamos que el sesgo estándar σ es la raíz cuadrada de la varianza σ2.
Con el fin de simplificar, la primera planilla no implementa el heurístico
σ2 = E[ (yt - y')2 ] al calcular el factor de servicio. Este método se implementa en la
Sheet2 o Planilla2 (segunda planilla del documento de Excel). Debido a que hemos supuesto pronósticos estacionarios en el ejemplo, el punto de reorden se mantiene idéntico con o sin el heurístico.
Recursos
'’Inventory Management and Production Planning and Scheduling'' (Gestión del inventario y planificación y programación de la producción), Edward A. Silver, David F. Pyke, Rein Peterson, Wiley; tercera edición edition, 1998

