販売予測によって安全在庫を算出
著者Joannès Vermorel、2007年12月推敲
以下に述べるアプローチは数十年前の古いものですが、Lokadが最近変位予測を中心に開発したものは「安全在庫」モデルをやや時代遅れにさせてしまうでしょう。実際、再発注点は変位予測に他ならないのです。したがって、安全在庫モデルによって与えられている変位値の「直接」計算は、平均して「間接」計算したものより優れています。
この項では安全在庫レベルを調整することによって最適な在庫量を保つ方法について説明します。小売業および製造業に適しています。この理論には マイクロソフト・エクセルを使っています。カスタム・アプリケーションに、この理論を用いたいと考えるソフトウェア開発者の方には、詳細情報を差し上げます。ターゲットとなる層: この資料は、主として小売業・製造業の物流部門に焦点を当てています。しかしまた、会計経理部門、ERP、eコマースのソフトウェアを編集して、在庫管理機能を強化したい場合にも有用です。
弊社では数学的な要求をできるだけ排除するよう努力していますが、すべての方程式を避けることはできません。この資料の目的は安全在庫を計算する方法を説明するガイドであることをご了承ください。
ダウンロード: calculate-safety-stocks.xls (Microsoft Excel Spreadsheet)
安全在庫について詳しく知る:
- 様々なリードタイムの処理法(英文) (ブログ投稿)
- 一括購入が安全在庫にもたらす影響(英文) (ブログ投稿)
はじめに
在庫管理は在庫コストと欠品コストの経済的トレードオフということになります。 在庫が多ければ、より多くの運営資金が必要になり、するとその分在庫の減価償却費が発生するということになります。一方で、在庫が十分でないと、品切れという事態に陥り、販売可能量を十分に確保できず、全体的な生産プロセスに支障をきたす可能性もはらんでいます。在庫量は原則的に以下の2つの要素に依ります。
しかし、これら二要素は不確実性に左右されます。
- 需要の変動:お客様の行動が予測不可能な方向に展開する
- リードタイムの変動:供給側や物流面で予期しない困難に直面する
安全在庫レベルを決定することは、これらの不確実性を考慮に入れたコストの相殺を行うことに等しいと言えるでしょう。
在庫管理コスト対欠品コストは、ビジネスによって非常に異なります。ですから、これらのコストを先に考えるよりも、まずは伝統的な「サービスレベル」の概念について紹介していきたいと思います。
サービスレベルとは、欠品を招かないある一定の安全在庫レベルの確率を表します。当然、安全在庫が増加するとサービスレベルも上昇します。安全在庫が非常に大きくなればサービスレベルは100%に近づく傾向にあります。(すなわち、欠品になる確率は0に近づきます)
サービスレベルを選択する、言い換えれば許容範囲の欠品率の決定については、このガイドでは触れませんが、別途ガイドがございます。最適なサービスレベルを計算するをご参照ください。
在庫補充モデル
弊社のウェブアプリSalescastを使って安全在庫の最適化を図ってください。Lokadは需要予測を通した在庫最適化を専門としています。このチュートリアル(およびその他多数)の内容はSalescast本来の機能です。
再発注点とは、注文をする時点の在庫量を指します。もし、不確実性がなければ(すなわち将来の需要が完全に分かっており、供給面が完全に信頼できる)、再発注点はリードタイム期間に予想される需要総量と単純に等しくなります。これは需要リードタイムとも呼ばれます。
Lokadでは、過去データから直接リードタイム需要を計算する数多くのツールをご提供しています。弊社サイトのマイクロソフトエクセルを使った予測方法と式をご覧ください。
実際には、不確実性があるため、このようになります。
再発注点 = 需要リードタイム + 安全在庫もし予測の信頼度が高いもの(偏りのないもの)と仮定するとき、安全在庫を0とするとサービスレベルは50%となります。確かに、信頼度の高い予測といっても将来の需要が需要リードタイムを上回ったり下回ったりする可能性は十分にあります(需要リードタイムは予測値に過ぎません)。
注意: 予測は正確でなくとも偏っていない場合があります。偏りは予測モデルによる定誤差を示します。(例:常に需要を20%多く見積もる)
誤差の正規分布
ここでは、需要リードタイムにおける不確実性を表す方法が必要となります。以下に、誤差が 正規分布であると仮定しましょう。下の図をご覧ください。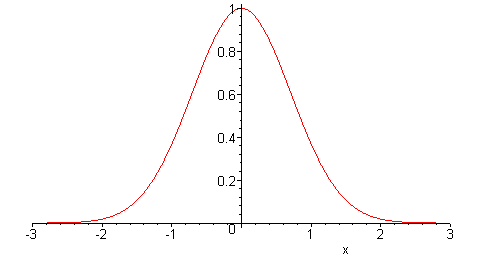
統計学上の注記: この正規分布仮定は完全に任意なものではありません。ある状況下では、統計に基づく推定量は、中心極限定理に表される通りの正規分布に収束します。しかしこれらの項目についてはこのガイドでは扱いません。
正規分布は、2つのパラメータによってのみ定義されます。それらは平均と分散です。今ここで予測は偏りのないものと仮定しているわけですから、エラー分布の平均が0と仮定し、それはエラーが0であると仮定しているわけではありません。
予測エラーの分散を決定するのは、さらにデリケートなタスクです。弊社は予測ツールキットとして、その予測に関連する MAPE estimations (Mean Absolute Percentage Error)をご提供しています。もう少し理解を深めるために、この問題を解決するために簡単なヒューリスティクスを説明しましょう。
特に過去データ内での分散は、予測エラー分散を推定するのによいヒューリスティックとなりえます。また、David Piaseckiは分散式において平均需要の代りに予測需要を使うよう提案しています。それは
σ2 = E[ (yt - y')2 ]上記は、
E は平均 作用素、yt は、期間 t の過去需要(一般的には売上高)、そして y' は予測需要を表します。この仮定に隠されているアイデアとは、予測エラーは非常に頻繁に予測分散の量と相関関係を持っているということです。分散が大きければ大きいほど、予測におけるエラーも大きくなると言えます。
実際、このエラー分散の計算は微妙なことで、以下のような詳細に大きく影響します。
安全在庫を求める計算式
さて、平均と分散の両方について決定したので、エラー分布については分かりました。次はこの分布で許容できるエラーレベルを計算しなければなりません。それを行うために、記述の通りサービスレベル(パーセンテージ)についてご紹介しました。注記:ここでは固定されたリードタイムを仮定しています。しかし、様々なリードタイムについて同様のアプローチを使うことができます。こちらを参照ください。
サービスレベルをエラーレベル(もしくはサービスファクターとも呼ばれる)に変換するために、逆累積正規分布(逆正規分布と呼ばれることもある)を使わなければなりません(対応するエクセル式についてはNORMSINV をご覧ください)。複雑そうに思われますが、そんなことはありません。視覚的に理解するために、まずこちらの正規分布アプレットをご覧下さい。ご覧の通り、累積関数はパーセンテージを曲線から下の部分に変換し、X軸閾はサービスファクター値に一致していることが分かります。
このように計算します。
safety stock(安全在庫) = standard deviation of error(エラーの標準編差) * service factor(サービスファクター)より形式的に書くならば安全在庫を
S とし、S = σ * icdf(P) ここでは
σ は標準偏差(すなわち上記で定義されている分散 σ2 の平方根) cdf は正規の累積正規分布(平均は0、分散は1と等しい)、 P はサービスレベルを表します。忘れてはいけないのが、
reorder point(再発注点) = lead time demand(需要リードタイム) + safety stock(安全在庫) Let
R を再発注点とすると、次のようになります。R = y' + σ * icdf(P)リードタイムの一致と予測期間
今まで、ひとつのリードタイムを想定してきたので、それに一致する将来需要を直接予測することができました。実際には、このようには行きません。過去データの分析はたいてい一定期間の集計から着手することになります (通常は週ごとや月ごと)。しかし、選択する期間はリードタイムと完全に一致するわけではありません。そこで、需要リードタイムとその関連する分散を表すための計算をすることが必要です(前項で説明した予測エラーの正規分布を仮定していると考えます)。
直感的に、需要リードタイムは、リードタイムセグメントと交差する将来の期間の予測値の合計として計算されるだろうと考えます。前予測期間ときっちりと調整するよう気を付けてください。
形式的に表すと、
T が期間、 L がリードタイムとし、以下のようになります。L = k * T + α * T 整数
k および 0 ≤ α < 1となります。
D を需要リードタイムとします。そして、需要リードタイムを最終式で表します。D = (Σt=1..k y't) + αy'k+1 将来の期間
nth についての予測需要 y'n とします。同じ正規分布を仮定して考えると、予測エラー分散を以下のように計算できます。C
σ2 = E[ (yt - y')2 ] y' は期間ごとの平均予測です。y'= D / (k + α)しかし、
σ2 は、期間ごとの分散として計算されている一方、 私たちが必要とするのはリードタイムに一致する分散です。 σL2 を調整したリードタイム分散ごとに置き換えると、σL2 = (k + α) σ2最後に、再発注点を以下のように表すことができます。
R = D + σL * cdf(P)エクセルを使った再発注点の計算
この項では マイクロソフト・エクセルを使ってどのように再発注点を計算するかを詳しく述べます。エクセルサンプルシートをご覧になることをお勧めします。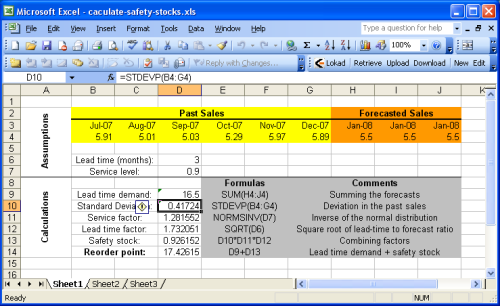
サンプルシートは二つのセクションに分かれています。上部に仮定、下部に計算があることがお分かりでしょう。売上(または需要)はこのガイドでは取り扱いませんので、予測は仮定の一部としています。詳細は、弊社サイト エクセルを使った売上げ予測チュートリアルをご参照ください。
前項で紹介されている方程式のほとんどは非常に平易な演算で、マイクロソフト・エクセルで簡単に行うことができます。しかし、2つの関数に注目してください。
NORMSINV(Microsoft KB):累積正規分布を推定します。上述ではcdfと表しています。STDEV(Microsoft KB):標準偏差を推定します。上述ではσと表しています。標準偏差σ分散の平方根iσ2であることを思い出してください。
簡易化するために、サービスファクターを計算する際、1番目のシートはヒューリスティック
σ2 = E[ (yt - y')2 ] を実行しません。このアプローチは Sheet2 で実行されます。(エクセルドキュメントの2番目のスプレッドシートです)この例では固定された予測を仮定しているので、再発注点をはこのヒューリスティックがあるなしにかかわらず同じものとなっています。ソフトウェア開発者の皆さまへ
この項は、自動化された在庫管理に補充機能を追加して実行したいソフトウェア開発者のためのものです。このガイドで説明した方程式のほとんどは、通常の開発ツールで何ら問題なく実行できます。もし、 .NETを使う場合、 Math.NET Iridium を使うことをお勧めします。これはオープンソースの数学ライブラリで C# 言語で書かれており、標準偏差作用素と累積正規分布機能を備えています。
もしくは、標準偏差はその定義に基づいて簡単に再実行することができます。the Wikipedia pageをご覧ください。累積正規分布はもう少し複雑になりますが、 Peter J. Acklam 氏が good algorithm を提供しており、多くの言語で実行されています。これら2つの方法に使われるコードは10行程度です。