传统预测的奇异之处
首页 » 资源 » 此处
2016 年 5 月更新:本页面侧重于传统预测,传统预测适用于 Lokad 作为需求预测工具使用,而不是作为库存优化工具使用的情形。概率预测则是一种截然不同并且更加强大的方法,任何时候只要是执行库存优化,都应当使用这种方法。
统计学是一门反直观的科学。所以 Lokad 的预测引擎作为一种统计 Web 应用,也许会提供令人费解的结果。在本文中,我们将介绍传统预测,也即每日、每周或每月预测。
使用入门
在这里,我们将假设您已入门,并且已使用 Lokad 生成了首个 Microsoft Excel 报告。如果您想知道对特定列的解释,请参考文档。建议您仔细检查输入数据是否正确,并根据从贵公司现有系统获取的值来仔细核对 Lokad 中报告的历史值。后验分析与模式选择
在探讨实际预测前,我们要简单回顾一下 Lokad生成这些预测的过程。我们的预测引擎包含一个大型的预测模式库,其中涵盖原生模式以及各种复杂模式。 对于每个时序,Lokad 会执行后验分析,也就是回溯过去,截断数据,并只利用截断的数据生成预测,然后衡量结果的准确度。此过程会每天、每周或每月(取决于所给定的历史数据适用的周期)重复执行。最后,对于每种模式的每个时序,预测引擎工具收集了一组准确度测量结果,根据该结果可选择最准确的预测模式。 这种选择机制严格地由性能驱动。打个比方,使用这种逻辑并不就表示必须要对X 产品应用季节性模式;季节性模式只是存在于预测引擎中而已,当这些模式的表现超过其他模式时,就应当选择这些模式。
平滑预测与不稳定的历史记录
大多数时候历史数据相对来说不太稳定,尤其是在考虑 SKU 或产品之类的解聚水平时。下图中的蓝色线表示样本时序。红色线表示该时序的试验性预测。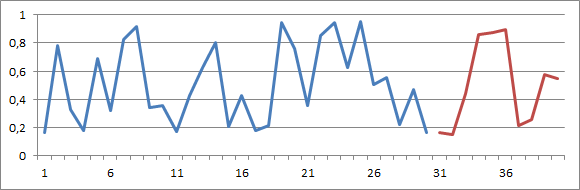
这种预测视觉上看上去不错,因为它再现了过去观察到的那种波动。但从统计的角度而言,这种预测普遍不准确。时序实际上是由介于 0 和 1 之间的随机值组成的。这里面没有可供了解的模式,有的只是噪点而已。
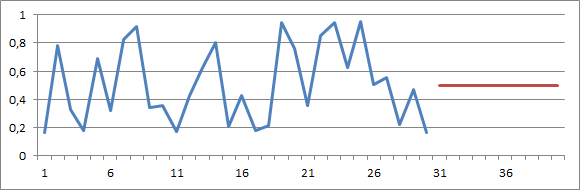
在上图中,我们修正了预测:现在它是一条位于 0.5 处的平直线。从视觉上看,该预测似乎与历史记录相矛盾:它呈现了在数据中从未观察到过的规则性。但从统计的角度说,该预测比之前的预测准确多了。
这一观念其实是统计学的一个常规(但并不是太直观)方面:历史需求越不稳定,预测越平滑。任何表现不同的预测系统,其实准确度低得多。
简单却不失高效的预测模式
尽管预测引擎包含非常复杂的模式,但有时仍需对特定数据集应用非常简单的模式(在模式选择过程中此类模式的表现超过其他模式时)。在其他许多示例中,我们对以下项目进行了建模:
- 平滑上一个周期(每周或每月预测):预测均匀重复上一周或上个月观察到的值。
- 一年的季节性(每周或每月预测):预测完全重复一年前(相应于 12 个月或 52 周)观察到的值。
- 一周循环(每日预测):预测完全重复一周前观察到的值,匹配星期模式。
- 平滑每年平均数(每周或每月预测):预测均匀重复过去一年的平均历史需求。
使用这些模式生成预测本身没什么问题,问题在于确定使用较复杂的模式比使用较简单的模式更好的确切时机,这也正是 Lokad 为什么如此重要的原因。
但从客户的角度说,平滑预测 – 尤其是提前 12 个月预测 – 往往结果令人失望,例如当 Lokad 传回的值中未发现业务专家预期的季节性模式时。不过,我们的预测引擎拥有许多季节性模式,并且每次会使用这些模式进行标杆分析。因此在选择非季节性的模式时,意味着这种模式在数量上其表现不会超过所有季节性模式。在此类情况下强行使用季节性模式只会降低准确度 – 但我们确实承认,这种模式不是很直观。
“准确度”栏
准确度栏为可选栏目,默认情况下该栏处于未激活状态。它表示传统预测预期的预测误差率。您不妨将这项功能视为系统的自我诊断。在这里我们不会讲解准确度指标实际定义的技术细节,简单地说,它就是一个百分比值:100% 表示预测完全准确,0% 表示预测完全不准确。对于预测过程(无论是统计过程还是其他过程)而言,100% 的准确度是不切实际的。在考量低销售量时,误差 +1 或 -1 可能会导致按百分比表示的准确度值低于 50%。准确度的总体水平是反直观的,它并非预测方法所产生的后果,而是数据本身的聚合水平所产生的后果。
比方说,如果我们预测全国每天的耗电量,准确度为 99.5% 的预测可能会被视为预测不准,而预测生鲜食品的促销时,准确度 30% 也可能会视为预测得不错。但是,这并不表示利用一种更好的预测方法也无法改进预测准确度。
就预测而言,预测不存在绝对的好或坏;唯一重要的问题在于这些预测相比既有的预测或替代性预测孰优孰劣。