Por Joannes Vermorel, noviembre de 2020Se dice que un pronóstico es probabilístico (en lugar de determinístico) si contiene un conjunto de probabilidades asociadas con todos los resultados futuros posibles en lugar de señalar un resultado particular como "el" pronóstico. Los pronósticos probabilísticos son importantes cuando la incertidumbre es inevitable, algo que casi siempre aparece en sistemas complejos. Para las cadenas de suministro, los pronósticos probabilísticos son esenciales para elaborar decisiones sólidas frente a condiciones futuras inciertas. Estos pronósticos son los que mejor abordan, en particular, dos aspectos clave del análisis de la cadena de suministro: la demanda y el tiempo de entrega. La perspectiva probabilística se presta por naturaleza a la priorización económica de las decisiones sobre la base de los rendimientos esperados (aunque inciertos) que se espera de ellas. Existe una gran variedad de modelos estadísticos que entregan pronósticos probabilísticos. Desde un punto de vista estructural, algunos se acercan más a sus contrapartes determinísticas, mientras que otros son muy diferentes. Evaluar la precisión de un pronóstico probabilístico requiere métricas específicas, que difieren de sus contrapartes determinísticas. El aprovechamiento de los pronósticos probabilísticos requiere herramientas especializadas que divergen de las de sus contrapartes determinísticas.
Pronóstico determinístico vs. probabilístico
La optimización de las cadenas de suministro depende de la anticipación adecuada de eventos futuros. A nivel numérico, estos eventos se anticipan a través de
pronósticos, que incluyen una amplia variedad de métodos numéricos utilizados para cuantificar estos eventos futuros. Desde de los años 70, la forma más utilizada de pronóstico ha sido el pronóstico de series de tiempo determinístico: una cantidad medida en el tiempo —por ejemplo, la demanda en unidades de un producto— se proyecta en el futuro. La sección del pasado de las series de tiempo son los datos históricos, mientras que la sección del futuro es el pronóstico.
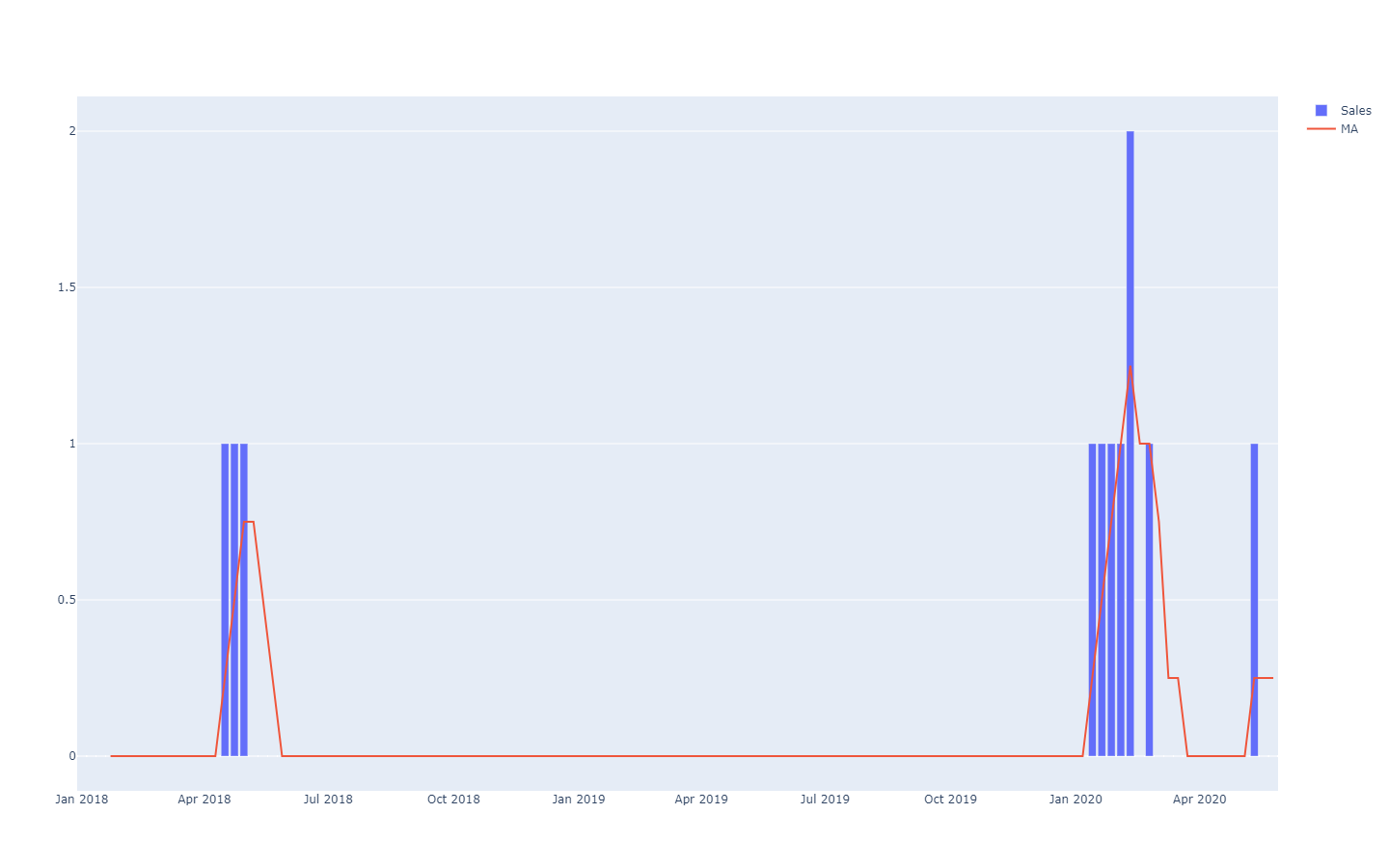
MA corresponde a "media móvil", que no ofrece resultados particularmente buenos en series de tiempo escasas.Estos pronósticos de series de tiempo se denominan "determinísticos" porque para cada punto de tiempo en el futuro, el pronóstico proporciona un solo valor que se espera que corresponda lo más posible con el resultado futuro. Si bien el pronóstico es de un solo valor, es sabido que tiene pocas probabilidades de ser totalmente correcto, y los resultados futuros diferirán del pronóstico. La adhesión del pronóstico determinístico a sus resultados futuros se evalúa cuantitativamente a través de métricas de precisión, como el error cuadrático medio (MSE).
Los pronósticos probabilísticos adoptan una perspectiva diferente cuando se trata de anticipar los resultados futuros. En lugar de producir un valor como el "mejor" resultado, el pronóstico probabilístico consiste en asignar una
probabilidad a cada resultado posible. Dicho de otra manera, todos los eventos futuros son posibles, pero no igualmente probables. A continuación se incluye la visualización de un pronóstico de series de tiempo probabilístico que muestra el "efecto escopeta" que generalmente se observa en la mayoría de las situaciones reales. Trataremos esta visualización en más detalle en la próxima sección.
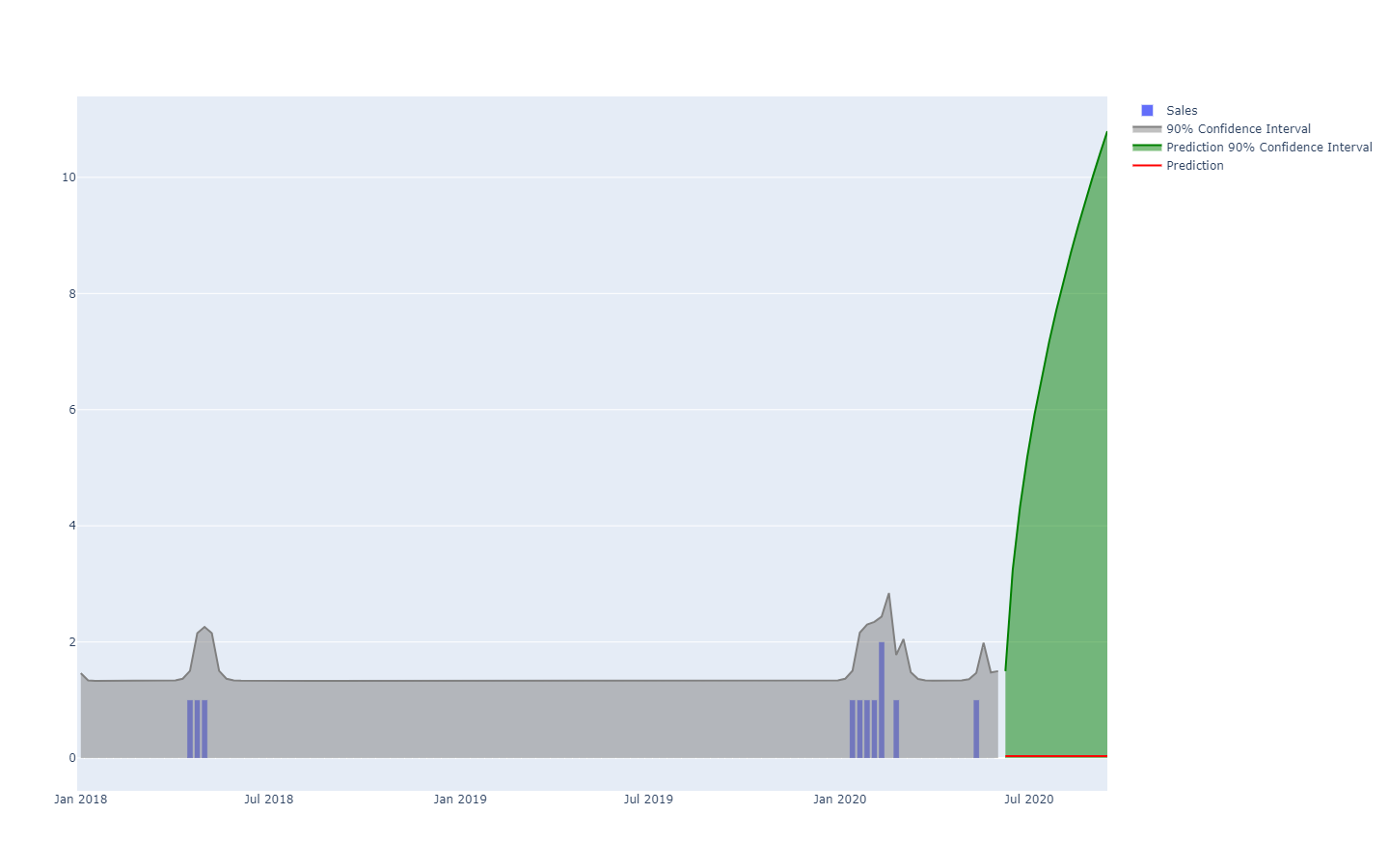
Pronóstico probabilístico que ilustra una situación de alta incertidumbre.Las series de tiempo (una cantidad medida a lo largo del tiempo) probablemente sean el modelo de datos más conocido y utilizado. Este modelo puede pronosticarse a través de medios determinísticos o probabilísticos. Sin embargo, existen muchos modelos de datos alternativos, generalmente más ricos, que también se prestan a pronósticos de ambos tipos. Por ejemplo, una empresa que repara motores de reacción podría querer anticipar la lista exacta de piezas de recambio que se necesitarán para una operación de mantenimiento próxima. Esta anticipación puede adoptar la forma de un pronóstico, pero no será un pronóstico de series de tiempo. El pronóstico determinístico asociado con esta operación es la lista exacta de piezas y sus cantidades. En cambio, el pronóstico probabilístico es la probabilidad que cada combinación de piezas (cantidades incluidas) tiene de ser la combinación específica que se necesite para llevar a cabo las reparaciones.
Además, si bien el término "pronóstico" pone el énfasis en una anticipación de algún tipo, la idea puede generalizarse a cualquier clase de afirmación "deducida estadísticamente" sobre un sistema, incluida la de sus propiedades pasadas (pero desconocidas). La práctica del pronóstico estadístico surgió durante el siglo XX, antes de la llegada de la perspectiva moderna del "aprendizaje estadístico", que incluye todas las extrapolaciones impulsadas por datos que pueden realizarse, independientemente de la dimensión temporal. Para que resulte claro, seguiremos usando el término "pronóstico" a continuación, aunque el aspecto temporal equipare siempre el pasado con lo conocido y el futuro con lo desconocido. Por ejemplo, una empresa podría querer calcular las ventas que se hubieran podido realizar de un producto en una tienda si el producto no hubiera estado agotado ese día. El cálculo es útil para cuantificar la magnitud del problema en términos de calidad de servicio. Sin embargo, debido a que el evento es pasado, la cifra de ventas "reales" no se verá nunca. No obstante (suponiendo que esto no se hubiera advertido ya) el cálculo estadístico de la demanda pasada es un problema muy cercano al cálculo de la demanda futura.
Los pronósticos probabilísticos son más ricos —en términos de información— que sus contrapartes determinísticas. Si bien el pronóstico determinístico proporciona la "mejor conjetura" del resultado futuro, no dice nada sobre las alternativas. De hecho, siempre se puede convertir un pronóstico probabilístico en su contraparte determinística tomando la media, la mediana, el modo, etc. de la distribución de probabilidad. Sin embargo, lo contrario no resulta verdadero: no es posible obtener un pronóstico probabilístico a partir de uno determinístico.
No obstante, a pesar de ser estadísticamente superiores a los pronósticos determinísticos, los pronósticos probabilísticos siguen siendo poco utilizados en la cadena de suministro, aunque su popularidad ha ido en continuo aumento en los últimos diez años. Históricamente, los pronósticos probabilísticos surgieron más tarde, ya que requieren muchos más recursos informáticos. Además, el uso de los pronósticos probabilísticos para los objetivos de la cadena de suministro requiere herramientas de software especializadas, que a menudo no están disponibles.
Casos de uso en la cadena de suministro
La optimización de una cadena de suministro consiste en tomar la decisión "correcta" —en el momento presente— que abordará del modo más rentable posible una situación futura que se estima solo de modo aproximado. Sin embargo, la incertidumbre asociada a los eventos futuros es, en gran medida, inevitable. Por lo tanto, la empresa necesita que la decisión sea sólida si la anticipación del evento futuro —es decir, el pronóstico— es imperfecta. Esto se ha hecho "mínimamente" desde mediados del siglo XX a través del análisis del stock de seguridad. Sin embargo, como veremos a continuación, dejando de lado el interés histórico, ya no hay motivo para preferir los stocks de seguridad por sobre las recetas numéricas probabilísticas "nativas".
La perspectiva de pronóstico probabilístico toma una posición radical con respecto a la incertidumbre: su abordaje intenta
cuantificar la incertidumbre en la mayor medida posible. En la cadena de suministro, los costos tienden a concentrarse en los extremos estadísticos: es la demanda inesperadamente alta la que crea desabastecimientos, y la demanda inesperadamente baja la que crea pérdida de inventario. En medio, el inventario rota sin problemas. Los pronósticos probabilísticos son —dicho crudamente— un intento de gestionar estas situaciones de baja frecuencia y altos costos que son omnipresentes en las cadenas de suministro modernas. Los pronósticos probabilísticos pueden y deberían verse como un ingrediente central de cualquier práctica de gestión de riesgos dentro de la cadena de suministro.
Muchos aspectos de las cadenas de suministro son particularmente adecuados para el pronósticos probabilístico. Por ejemplo, los siguientes:
- Demanda: prendas, accesorios, piezas de recambio, así como otros tipos de productos, tienden a asociarse con la demanda errática o intermitente. Los lanzamientos de producto pueden ser muy irregulares y extremos (un éxito o un fracaso). Las promociones de competidores pueden canibalizar de modo temporal y errático grandes porciones de las cuotas de mercado.
- Tiempo de entrega: las importaciones de ultramar pueden incurrir en toda una serie de retrasos en cualquier punto de la cadena (producción, transporte, aduanas, recepción, etc.): Incluso los proveedores locales pueden, de modo menos frecuente, tener tiempos de entrega prolongados si se enfrentan a un problema de desabastecimiento. Los tiempos de entrega tienden a ser distribuciones de "cola gruesa" (fat-tail).
- Rendimiento (alimentos frescos): la cantidad y la calidad de la producción de muchos productos frescos dependen de condiciones, como el clima, que están fuera del control de la empresa. El pronóstico probabilístico cuantifica estos factores para toda la temporada y ofrece la posibilidad de ir más allá del horizonte de relevancia de los pronósticos de tiempo clásicos.
- Devoluciones (e-commerce): cuando un cliente hace un pedido del mismo producto en tres tallas diferentes, hay altas probabilidades de que dos de esas tallas se devuelvan. En general, si bien hay grandes diferencias regionales, los clientes tienden a aprovechar las políticas de devolución favorables, cuando existen. La probabilidad de devoluciones de cada pedido es algo que debería evaluarse.
- Chatarra (aviación): las piezas reparables de los aviones, que se denominan rotables, a veces no pueden ser reparadas. En este caso, la pieza se desecha, ya que no es apta para ser montada nuevamente en un avión. Si bien a menudo no es posible saber de antemano si una pieza sobrevivirá a la reparación o no, las probabilidades de tener una parte desechada (chatarra) es algo que debería calcularse.
- Stocks (B2C minorista): los clientes pueden reemplazar, dañar o incluso robar productos de una tienda minorista. Es por eso que el nivel de stock electrónico es solo una aproximación de la disponibilidad real en anaquel El nivel de stock, como lo perciben los clientes, es algo que debería calcularse a través de un pronóstico probabilístico.
- Etcétera.
Esta breve lista ilustra que las perspectivas aptas para un pronóstico probabilístico exceden enormemente la perspectiva única tradicional del "pronóstico de demanda". La optimización bien diseñada de una cadena de suministro exige que se consideren todas las fuentes relevantes de incertidumbre. Si bien a veces es posible reducir la incertidumbre —como lo destaca la producción Lean— generalmente esto implica compensaciones económicas y, como resultado, existe un cierto grado de incertidumbre que no puede evitarse.
Los pronósticos, sin embargo, no son más que opiniones fundamentadas sobre el futuro. Si bien los pronósticos probabilísticos pueden considerarse opiniones considerablemente detalladas, no son, en esencia, diferentes de sus contrapartes determinísticas en este sentido. El valor de los pronósticos probabilísticos —en lo que a la cadena de suministro concierne— se encuentra en la manera en que se aprovecha esta estructura detallada para entregar decisiones más rentables. En particular, generalmente no se espera que los pronósticos probabilísticos sean más precisos que sus contrapartes determinísticas si se utilizan métricas de precisión determinísticas para evaluar la calidad de los pronósticos.
En defensa de la variabilidad
A pesar de lo que muchos abordajes de la cadena de suministro defienden, la variabilidad ha llegado para quedarse, y por eso se necesitan pronósticos probabilísticos. El primer error es considerar que la variabilidad es necesariamente algo malo para la cadena de suministro: no lo es. El segundo error es pensar que esa variabilidad puede eliminarse mediante el diseño: no se puede.
En muchas situaciones, la variabilidad tiene consecuencias positivas para las cadenas de suministro. Por ejemplo, del lado de la demanda, la mayoría de los sectores se ven impulsados por la novedad, como en el caso de la moda, los productos culturales y el lujo (
soft y
hard), ya que son en los que vale el concepto de los extremos: "éxito o fracaso". La mayoría de los nuevos productos no son éxitos, pero los que llegan a serlo generan rendimientos enormes. La variabilidad adicional es buena, porque aumenta la probabilidad de rendimientos desmesurados, mientras que las desventajas tienen un límite (en el peor de los casos, se pierde todo el inventario). El flujo interminable de nuevos productos que se lanzan al mercado asegura la renovación constante de los éxitos, mientras que los productos viejos van menguando.
Del lado del suministro, un proceso de abastecimiento que asegura ofertas de precios altamente variables es superior —suponiendo que todos los demás factores se mantienen iguales— a un proceso alternativo que genera precios mucho más consistentes (es decir, menos variables). De hecho, se selecciona la opción de menor precio, mientras que las otras se descartan. No importa si el precio "promedio" seleccionado es bajo; lo que importa es descubrir fuentes con menor precio. Por lo tanto, un buen proceso de abastecimiento debería estar diseñado para aumentar la variabilidad; por ejemplo, poniendo el énfasis en la búsqueda rutinaria de nuevos proveedores, en lugar de restringir el proceso de aprovisionamiento a los viejos conocidos.
A veces, la variabilidad puede ser beneficiosa por motivos más imperceptibles. Por ejemplo, si una marca es demasiado predecible en sus operaciones promocionales, los clientes identifican el patrón y comienzan a retrasar su compra, ya que saben que se aproxima una promoción y cuándo. La variabilidad —e incluso el carácter errático— de las actividades promocionales en cierta medida mitiga este comportamiento.
Otro ejemplo es la presencia de factores de confusión dentro de la cadena de suministro misma. Si los nuevos productos se lanzan siempre con campañas en TV y radio, se vuelve estadísticamente difícil distinguir los impactos respectivos de la TV y la radio. La adición de variabilidad a la intensidad de cada una de las campañas según el canal asegura que se pueda extraer más información estadística de esas operaciones posteriormente, lo que luego puede convertirse en información estratégica para una mejor asignación de los recursos de marketing.
Naturalmente, no toda la variabilidad es buena. La producción Lean tiene razón en destacar que, del lado de la producción de la cadena de suministro, la variabilidad a menudo es perjudicial, especialmente cuando se trata de retrasos variables. De hecho, pueden aparecer accidentalmente procesos LIFO (primero en entrar, primero en salir), lo que, a su vez, exacerba la variabilidad del tiempo de entrega. En esas situaciones, la variabilidad accidental debería eliminarse por diseño, generalmente a través de un mejor proceso, a veces con equipos o instalaciones mejores.
No obstante, la variabilidad —aún cuando es perjudicial— es a menudo inevitable. Como veremos en la próxima sección, las cadenas de suministro acatan la ley de los pequeños números. Es ilusorio pensar que el nivel de tienda puede pronosticarse de modo fiable —desde una perspectiva determinística— cuando ni siquiera los clientes saben siempre lo que están por comprar. En general, reducir la variabilidad tiene un costo (y reducirla ulteriormente cuesta aún más), mientras que la reducción marginal de la variabilidad solo acarrea rendimientos decrecientes. Por lo tanto, incluso cuando la variabilidad puede reducirse, desde todo punto de vista, raramente puede eliminarse por completo debido a las consecuencias económicas.
La ley de los pequeños números
La ley de cadena de suministro de los pequeños números puede enunciarse del siguiente modo:
los números pequeños prevalecen por todas partes en la cadena de suministro. Esta ley observacional deriva de las economías de escala y algunas otras fuerzas que impulsan la mayor parte de los aspectos estructurales de las cadenas de suministro:
- Un proveedor que abastece decenas de miles de unidades de materiales por día es probable que tenga cantidades mínimas de pedido (MOQ) o descuentos de precios que evitan pedidos de compra demasiado frecuentes. La cantidad de pedidos de compra que se realizan en un determinado día a un proveedor raramente superan los números de una cifra.
- Una fábrica que produce decenas de miles de unidades por día es probable que opere a través de grandes lotes de miles de unidades. Es probable que la producción se empaquete en palets enteros. La cantidad de lotes durante un día determinado será, como mucho, un número pequeño de dos cifras.
- Un almacén que recibe decenas de miles de unidades por día es probable que las reciba en camiones, y que cada camión descargue toda su carga en el almacén. La cantidad de entregas de camión en un día determinado raramente superará un número de dos cifras, incluso para almacenes muy grandes.
- Una tienda minorista que almacena decenas de miles de unidades en stock es probable que reparta su surtido en miles de referencias de producto distintas. La cantidad de unidades almacenadas en stock para cada producto raramente superará un número de una cifra.
- Etcétera.
Naturalmente, es posible inflar los números cambiando la unidad de medida. Por ejemplo, en lugar de contar la cantidad de palets, contamos la cantidad de
gramos de palets, o sus valores monetarios en centavos de USD, y entonces aparecen números grandes. Sin embargo, la ley de los pequeños números debería comprenderse con la noción de contar cosas desde una perspectiva sensata de cadena de suministro. Si bien, en teoría, este principio puede parecer relativamente subjetivo, no es así en la realidad, debido a las cuestiones prácticas de las cadenas de suministro modernas: paquetes, cajas, palets, contenedores, camiones, etc.
Esta ley es altamente relevante para la perspectiva del pronóstico probabilístico. En primer lugar, expone que los pronósticos
discretos dominan en situaciones de cadena de suministro; es decir, el resultado que debe anticiparse (o decidirse) es un
entero, en lugar de un número fraccionario. Los pronósticos probabilísticos son particularmente adecuados para las situaciones
discretas, porque es posible calcular una probabilidad para cada resultado discreto. Al contrario, para los pronósticos determinísticos resulta difícil afrontar los resultados discretos. Por ejemplo, ¿qué significa que las ventas diarias esperadas de un producto sean 1,3 unidades? Las unidades no se venden por fracción. Si bien pueden deducirse interpretaciones "discretas" más sensatas de esta afirmación, su contraparte probabilística (por ej., 27 % de probabilidad de 0 unidades de demanda, 35 % de probabilidad de 1 unidad de demanda, 23 % de probabilidad de 2 unidades de demanda, etc.) es mucho más directa, porque acepta y adopta la naturaleza discreta del fenómeno en cuestión.
En segundo lugar, si bien los pronósticos probabilísticos pueden parecer radicalmente más complejos en términos de recursos informáticos, esto no es así en la práctica, precisamente debido a la ley de los pequeños números. De hecho, volviendo al caso de las ventas diarias de productos presentada antes, no tiene sentido evaluar numéricamente las probabilidades en las que la demanda superará los 100 en un día determinado. Esas probabilidades pueden redondearse a cero o a cualquier otro valor pequeño arbitrario. El impacto en la precisión numérica del modelo de cadena de suministro seguirá siendo insignificante. Como regla general, es razonable considerar que los pronósticos probabilísticos requieren aproximadamente tres veces más recursos informáticos que sus contrapartes determinísticas. Sin embargo, a pesar de esta sobrecarga, los beneficios en términos de rendimiento de cadena de suministro superan ampliamente el costo de los recursos informáticos.
Métricas de precisión para pronósticos probabilísticos
Independientemente de lo que suceda, un pronóstico probabilístico razonablemente bien diseñado indica que, de hecho, existía una probabilidad diferente de cero de que este se produjera este resultado. Esto es interesante, porque, a primera vista, puede parecer que los pronósticos probabilísticos sean de algún modo inmunes a la realidad, al igual que un adivino que hace afirmaciones proféticas ambiguas cuya incorrección no puede siquiera demostrarse, ya que el adivino siempre puede inventarse una explicación sucesiva sobre cómo debe interpretarse la profecía a posteriori. En la realidad, existen muchas maneras de evaluar cuantitativamente la calidad de un pronóstico probabilístico. Algunas de estas maneras son "métricas" que se asemejan, en esencia, a las métricas utilizadas para evaluar la precisión de los pronósticos determinísticos. Otras se desvían hacia formas más radicales y profundas comparadas con la perspectiva determinística.
Revisemos brevemente cuatro abordajes diferentes para evaluar la precisión de un pronóstico probabilístico:
- la función de pérdida pinball
- las CRPS (puntuaciones rango de probabilidad continuo)
- la probabilidad bayesiana
- la perspectiva de redes generativas antagónicas
La
función de pérdida pinball proporciona una métrica de precisión para derivar una estima de cuantil de un pronóstico probabilístico. Por ejemplo, si deseamos evaluar la cantidad de stock que tiene un 98 % de probabilidad de ser mayor o igual que la demanda de cliente de un determinado producto en una tienda, esta cantidad puede obtenerse directamente de los pronósticos probabilísticos simplemente sumando las probabilidades comenzando con 0 unidades de demanda, 1 unidad de demanda, etc., hasta que la probabilidad supere el 98 %. La función de pérdida
pinball proporciona una medida directa de la calidad de este cálculo sesgado de la demanda futura. Puede verse como una herramienta para evaluar la calidad de cualquier punto de la función de densidad acumulativa del pronóstico probabilístico.
Las
puntuaciones de rango de probabilidad continuo (CRPS) proporcionan una métrica que puede interpretarse como la "cantidad de desplazamiento" de la masa de probabilidades que requiere llevar toda la masa de probabilidad hasta el resultado observado. Es la generalización más directa del error absoluto medio (MAE) hacia una perspectiva probabilística. El valor CRPS es homogéneo con la unidad de medida del resultado mismo. Esta perspectiva puede generalizarse a espacios métricos arbitrarios, en lugar de solo a situaciones unidimensionales, a través de lo que se conoce como la "teoría de la transportación" y el problema Monge-Kantorovich (que excede el alcance del presente documento).
La probabilidad y su prima, la
la entropía cruzada, adoptan la perspectiva bayesiana del
menor grado de sorpresa: cuanto mayor sea la probabilidad de los resultados observados, mejor. Por ejemplo, tenemos dos modelos probabilísticos: A y B. El modelo A establece que la probabilidad de observar 0 unidades de demanda es del 50 % en un determinado día cualquiera, mientras que el modelo B establece que la probabilidad de observar 0 unidades de demanda es del 1 % en un determinado día cualquiera. Observamos la demanda durante 3 días y obtenemos las siguientes observaciones: 0, 0, 1. El modelo A tenía apenas un 10 % de probabilidad de generar estas observaciones, mientras que el modelo B tiene solo 0,01 %. Por lo tanto, el modelo B tiene muchas menos probabilidades de ser el modelo correcto comparado con el modelo A. La probabilidad difiere de la perspectiva determinística de tener un criterio
absoluto significativo para evaluar los modelos. En cambio, proporciona un mecanismo para
comparar modelos; no obstante, a nivel numérico, no puede utilizarse más que para comparar modelos.
La perspectiva de redes antagónicas generativas es la perspectiva más moderna en este tema (Ian Goodfellow
et al., 2014). Esencialmente, esta perspectiva establece que el "mejor" modelo probabilístico es aquel que se puede utilizar para generar resultados —al estilo Monte Carlo— que no puedan distinguirse de los resultados reales. Por ejemplo, si consideráramos la lista histórica de transacciones de un hipermercado local, podríamos truncar este historial en un punto arbitrario del tiempo en el pasado y utilizar el modelo probabilístico para generar transacciones falsas, pero realistas, en adelante. El modelo se consideraría "perfecto" si fuera imposible, a través de un análisis estadístico, recuperar el punto en el tiempo en el que el conjunto de datos pasa de los datos "reales" a los datos "falsos". La idea central del abordaje de redes antagónicas generativas es "aprender" las métricas que exacerban la falla de cualquier modelo probabilístico. En lugar de concentrarse en una métrica en particular, esta perspectiva aprovecha de forma recursiva las técnicas de machine learning para "aprender" las métricas mismas.
La búsqueda de formas mejores de acceder a la calidad de los pronósticos probabilísticos sigue siento un área activa de investigación. No existe una delimitación clara entre las preguntas "¿Cómo se elabora un pronóstico mejor?" y "¿Cómo se determina si un pronóstico es mejor?", ya que trabajos recientes han difuminado considerablemente los límites entre ambas, y es probable que los próximos avances impliquen aún mayores cambios incluso en la manera misma en que se miran los pronósticos probabilísticos.
Probabilidades extremadamente pequeñas y probabilidad logarítmica
Las probabilidades muy pequeñas surgen naturalmente cuando se observa una situación pluridimensional a través del prisma de los pronósticos probabilísticos. Esas probabilidades pequeñas son problemáticas, porque las computadoras no procesan números indefinidamente precisos. Los valores de probabilidad "brutos" son a menudo "insignificantemente" pequeños, al punto que se redondean a cero debido a los límites de la precisión numérica. La solución a este problema no es actualizar el software para que admitan cálculos de precisión arbitraria —algo que resulta muy ineficiente en términos de recursos informáticos— sino utilizar el "truco logarítmico", que transforma multiplicaciones en sumas. Este es un truco que, de una forma u otra, aprovechan casi todos los software que trabajan con pronósticos probabilísticos.
Supongamos que tenemos $X_1$, $X_2$, …, $X_n$ variables aleatorias que representan la demanda del día de los $n$ productos distintos ofrecidos en una determinada tienda. Supongamos que $\hat{x}_1$, $\hat{x}_2$, .., $\hat{x}_n$ corresponden a la demanda empírica observada al final del día para cada producto. Para el primer producto —gobernado por $X_1$— la probabilidad de observar $\hat{x}_1$ se escribe $P(X_1 = \hat{x}_1)$. Ahora, supongamos —indebidamente, pero para que resulte claro— que todos los productos son estrictamente independientes en cuanto a la demanda. La probabilidad de que el evento conjunto de observar $\hat{x}_1$, $\hat{x}_2$, .., $\hat{x}_n$ es:
$$P(X_1 = \hat{x}_1 \dots X_n = \hat{x}_n) = \prod_{k=1}^n P(X_k = \hat{x}_k)$$
If $P(X_k = \hat{x}_k) \approx \frac{1}{2}$ (aproximación grosera) y $n = 10000$ luego la probabilidad conjunta anterior es del orden de $\frac{1}{2^{10000}} \approx 5 * 10^{-3011}$, que es un valor muy pequeño. Este valor "subdesborda", es decir, va por debajo del número pequeño representable, incluso considerando números de coma flotante de 64 bits que generalmente se utilizan en el cálculo científico.
El "truco logarítmico" consiste en trabajar con el logaritmo de la expresión, es decir:
$$\ln P(X_1 = \hat{x}_1 \dots X_n = \hat{x}_n) = \sum_{k=1}^n \ln P(X_k = \hat{x}_k)$$
El logaritmo convierte la serie de multiplicaciones en serie de sumas, lo que resulta mucho más estable numéricamente que una serie de multiplicaciones.
El uso del "truco logarítmico" es frecuente cuando hay pronósticos probabilísticos involucrados. La "probabilidad logarítmica" es casi literalmente el logaritmo de la probabilidad (presentado anteriormente), precisamente porque la probabilidad "bruta" sería, en general, numéricamente irrepresentable considerando los tipos comunes de números de coma flotante.
Formas algorítmicas de pronósticos probabilísticos
La cuestión de la generación de los pronósticos probabilísticos impulsada por computadoras es casi tan vasta como el campo del machine learning mismo. Los límites entre ambos campos, si los hubiera, son principalmente cuestión de elecciones subjetivas. No obstante, esta sección presenta una lista bastante electiva de abordajes logarítmicos destacados que pueden utilizarse para obtener pronósticos probabilísticos.
A principios del siglo XX (posiblemente a fines del siglo XIX), surgió la idea del
stock de seguridad, en el que la incertidumbre de la demanda se modela siguiendo una distribución normal. Debido a que ya se habían establecidos tablas precalculadas de la distribución normal para otras ciencias (principalmente la física), la aplicación del stock de seguridad solo requirió una multiplicación de un nivel de demanda por un coeficiente de "stock de seguridad" obtenido de una tabla preexistente. A título anecdótico, muchos manuales de cadena de suministro que se escribieron hasta los años 90 seguían incluyendo tablas de la distribución normal en sus apéndices. Lamentablemente, la principal desventaja de este abordaje es que las distribuciones "normales" no son una propuesta razonable para las cadenas de suministro. En primer lugar, podemos suponer con seguridad que
nada se distribuye
normalmente en las cadenas de suministro. En segundo lugar, la distribución normal es una distribución continua, algo que se opone a la naturaleza discreta de los eventos de la cadena de suministro (consulte la sección "Ley de los pequeños números" más arriba). Por lo tanto, si bien técnicamente los "stocks de seguridad" tienen un componente probabilístico, la metodología y las recetas numéricas subyacentes están sin dudas orientadas hacia una perspectiva determinística. No obstante, este abordaje se incluye aquí para que resulte claro.
Adelantemos a principios de los años 2000, cuando aparecen los métodos de aprendizaje de ensamble —cuyos representantes más conocidos son probablemente los bosques aleatorios y los árboles aumentados de gradiente— que resultan fácilmente ampliables desde sus orígenes determinísticos a la perspectiva probabilística. La idea clave detrás del aprendizaje de ensamble es combinar varios factores predictivos débiles y determinísticos, como los árboles de decisión, en un factor predictivo determinístico superior. Es posible, no obstante, ajustar el proceso de combinación para obtener probabilidades en lugar de simplemente un agregado, lo que convierte al método de aprendizaje de ensamble en un método de pronóstico probabilístico. Estos métodos son no paramétricos y capaces de incluir distribuciones de cola gruesa o multimodales, que se encuentran comúnmente en la cadena de suministro. Estos métodos suelen tener dos inconvenientes significativos. En primer lugar, por diseño, la función de probabilidad de densidad elaborada por esta clase de modelos tiende a incluir muchos ceros, lo que impide cualquier intento de aprovechar la métrica de probabilidad logarítimica. En general, estos modelos no se adecuan a la perspectiva bayesiana, ya que tienden a declarar que las observaciones más nuevas son "imposibles" (es decir, le asignan cero probabilidad). Este problema, no obstante, puede resolverse a través de métodos de regularización[1]. En segundo lugar, los modelos suelen tener la misma dimensión que una fracción considerable del conjunto de datos de entrada, y la operación "pronosticar" tiende a ser casi tan costosa a nivel computacional como la operación "aprender".
Los métodos hiperparamétricos, conocidos en conjunto con el nombre de "deep learning", que emergieron con fuerza en la década de 2010, fueron, casi "accidentalmente", probabilísticos. De hecho, si bien la gran mayoría de las tareas en las que el deep learning realmente se luce (por ej., la clasificación de imágenes) se concentran solo en pronósticos determinísticos, resulta ser que la métrica de entropía cruzada —una variante de la probabilidad logarítmica de la que hablábamos antes— muestra gradientes pronunciados que a menudo se adecuan al descenso estocástico de gradiente (SGD), algo central en los métodos de deep learning. Por lo tanto, los modelos de deep learning resultan estar diseñados como probabilísticos, no porque las probabilidades sean de interés, sino porque el descenso de gradiente converge más rápidamente cuando la función de pérdida refleja un pronóstico probabilístico. Por lo tanto, con respecto al deep learning, la cadena de suministro se destaca por su interés en el resultado probabilístico real del modelo de deep learning, mientras que la mayoría de los demás casos de uso reducen la distribución de probabilidad a su media, su mediana o su moda. Las redes de densidad de mezcla (
Mixture Density Networks) son un tipo de red de deep learning orientada hacia el aprendizaje de distribuciones de probabilidad complejas. El resultado en sí es una distribución paramétrica, posiblemente compuesta de gaussianas. Sin embargo, a diferencia de los stocks de seguridad, una mezcla de varias distribuciones gaussianas puede, en la práctica, reflejar los comportamientos de cola gruesa que se observan en las cadenas de suministro. Es preciso señalar que, aunque los métodos de deep learning a menudo se consideran de vanguardia, lograr una estabilidad numérica, especialmente con mezclas de densidad de por medio, sigue siendo un "arte oscura".
La programación diferenciable es un descendiente del deep learning que se hizo popular a fines de la década de 2010. Comparte muchos atributos técnicos con el deep learning, pero difiere significativamente en enfoque. Mientras que el deep learning se concentra en el aprendizaje de funciones complejas arbitrarias (por ej. jugar a Go) apilando una gran cantidad de funciones simples (por ej., capas convolucionales), la programación diferenciable se concentra en la estructura fina del proceso de aprendizaje. La estructura más fina y expresiva puede, casi literalmente, formatearse como un programa, que incluye ramas, bucles, llamadas de función, etc. La programación diferenciable es de gran interés para la cadena de suministro porque los problemas tienden a presentarse en formas altamente estructuradas, y esas estructuras son conocidas para los expertos [2]. Por ejemplo, las ventas de una determinada camiseta pueden ser canibalizadas por las de otra camiseta de un color diferente, pero no serán canibalizadas por las ventas de una camiseta tres tallas superior o inferior. Estos conocimientos previos estructurales son claves para lograr una alta eficiencia de los datos. De hecho, desde una perspectiva de cadena de suministro, la cantidad de datos tiende a ser muy limitada (vea la sección sobre la ley de los pequeños números). Por lo tanto, el "enmarcado" estructural del problema ayuda a asegurar que los patrones estadísticos deseados se aprendan, aún cuando los datos sean limitados. Los conocimientos previos estructurales (o
structural priors) también ayudan a abordar los problemas de estabilidad numérica. Comparados con los métodos de ensamble, los conocimientos previos estructurales tienden a requerir menos tiempo que el diseño de funciones a ser más simples de mantener. Como aspecto desfavorable, la programación diferenciable sigue siendo una perspectiva relativamente incipiente a la fecha.
El método Monte Carlo (1930/1940) puede utilizarse para abordar pronósticos probabilísticos desde otro ángulo. Los modelos discutidos hasta ahora proporcionan funciones de densidad de probabilidad explícitas (PDF). Desde una perspectiva Monte Carlo, sin embargo, un modelo puede ser reemplazado por un generador —o
sampler— de resultados aleatorios posibles. Las PDF pueden recuperarse promediando los resultados del generador, aunque este tipo de funciones suelen pasarse por alto para reducir los requisitos de recursos informáticos. De hecho, el generador a menudo está diseñado para ser mucho más compacto —en términos de datos— que la PDF que representa. La mayoría de los modelos de machine learning —incluidos los enumerados anteriormente para afrontar directamente los pronósticos probabilísticos— pueden contribuir al aprendizaje de un generador. Los generadores pueden asumir la forma de modelos paramétricos de baja dimensión (por ej., los modelos de espacio de estado) o modelos hiperparamétricos (por ej., los modelos LSTM y GRU en el deep learning). Los métodos de ensamble raramente se utilizan para respaldar procesos generativos debido a los altos costos de cálculo de sus operaciones de "pronóstico", muy requeridas por el método Monte Carlo.
Trabajar con pronósticos probabilísticos
Para derivar información estratégica y decisiones útiles de los pronósticos probabilísticos se necesitan herramientas numéricas especializadas. A diferencia de los pronósticos determinísticos, en los que hay números simples, los pronósticos mismos son explícitos, funciones de densidad de probabilidad o generadores Monte Carlo. La calidad de las herramientas probabilísticas es, en la práctica, tan importante como la calidad de los pronósticos probabilísticos. Sin esta herramienta, la explotación de los pronósticos probabilísticos se convierte en un proceso determinístico (hablaremos más al respecto en la sección "Antipatrones" a continuación).
Por ejemplo, estas herramientas deberían ser capaces de realizar tareas como las siguientes:
- Combinar el tiempo de entrega de producción incierto con el tiempo de entrega de transporte incierto para obtener el tiempo de entrega incierto "total".
- Combinar la demanda incierta con el tiempo de entrega incierto para obtener la demanda incierta "total" que debe cubrir el stock que se pedirá.
- Combinar las devoluciones de pedidos inciertas (e-commerce) con la fecha de llegada incierta del pedido del proveedor en tránsito para obtener el tiempo de entrega al cliente incierto.
- Aumentar el pronóstico de demanda, elaborado por un método estadístico, con un riesgo colateral derivado manualmente de una comprensión de alto nivel de un contexto no reflejado en los datos históricos, como una pandemia.
- Combinar la demanda incierta con un estado incierto del stock con respecto a la fecha de vencimiento (sector minorista de alimentos) para obtener la cantidad incierta de sobrante de stock de final del día.
- Etcétera.
Una vez que se combinan adecuadamente todos los pronósticos probabilísticos —no solo los de demanda—, debería tener lugar la optimización de las decisiones de cadena de suministro. Esto implica una perspectiva probabilística de las limitaciones, así como la función de puntuación. Sin embargo, este aspecto de las herramientas excede el objetivo de este documento.
Existen dos "formas" generales de herramientas que trabajan con pronósticos probabilísticos: álgebra sobre variables aleatorias y programación probabilística. Estas dos formas se complementan, ya que no tienen la misma combinación de pros y contras.
Un álgebra de variables aleatorias generalmente funciona en funciones de densidad de probabilidad explícitas. El álgebra admite las operaciones aritméticas habituales (suma, resta, multiplicación, etc.), pero extrapoladas a sus contrapartes probabilísticas, a menudo tratando las variables aleatorias como estadísticamente independientes. El álgebra proporciona una estabilidad numérica que es casi igual a la de su contraparte determinística (es decir, números simples). Todos los resultados intermedios pueden almacenarse para se utilizados más tarde, lo que resulta útil para organizar y resolver problemas del pipeline de datos. Como desventaja, la expresividad de estas álgebras tiende a ser limitada, ya que generalmente no es posible expresar todas las dependencias condicionales sutiles que existen entre variables aleatorias.
La programación probabilística adopta una perspectiva Monte Carlo para abordar el problema. La lógica se escribe una sola vez, generalmente adhiriendo a una perspectiva totalmente determinística, pero se ejecuta muchas veces a través de la herramienta (es decir, el proceso Monte Carlo) para recopilar las estadísticas deseadas. La máxima expresividad se logra a través de construcciones "programáticas", que permiten modelar dependencias arbitrarias y complejas entre variables aleatorias. Escribir la lógica misma mediante la programación probabilística suele ser, además, levemente más fácil cuando se la compara con un álgebra de variables aleatorias, ya que la lógica incluye solo números regulares. Como desventaja, cabe mencionar la compensación constante necesaria entre la estabilidad numérica (más iteraciones generan mejor precisión) y los recursos informáticos (más iteraciones cuestan más dinero). Además, los resultados intermedios no suelen ser inmediatamente accesibles, ya que su existencia es transitoria, precisamente para aliviar la presión sobre los recursos informáticos.
Trabajos recientes en deep learning también indican que existen otros abordajes además de los dos presentados arriba. Por ejemplo, los autocodificadores variacionales ofrecen perspectivas para realizar operaciones sobre
espacios latentes con excelentes resultados al tiempo que buscan transformaciones muy complejas en los datos (por ejemplo, eliminar automáticamente gafas de una foto retrato). Si bien estos abordajes son conceptualmente muy interesantes, hasta la fecha no han demostrado demasiada relevancia práctica para tratar los problemas de la cadena de suministro.
Visualización de pronósticos probabilísticos
El modo más sencillo de visualizar una distribución de probabilidad discreta es un histograma, en el que el eje vertical indica la probabilidad y el horizontal, el valor de la variable aleatoria de interés. Por ejemplo, un pronóstico probabilístico de un tiempo de entrega puede mostrarse del siguiente modo:
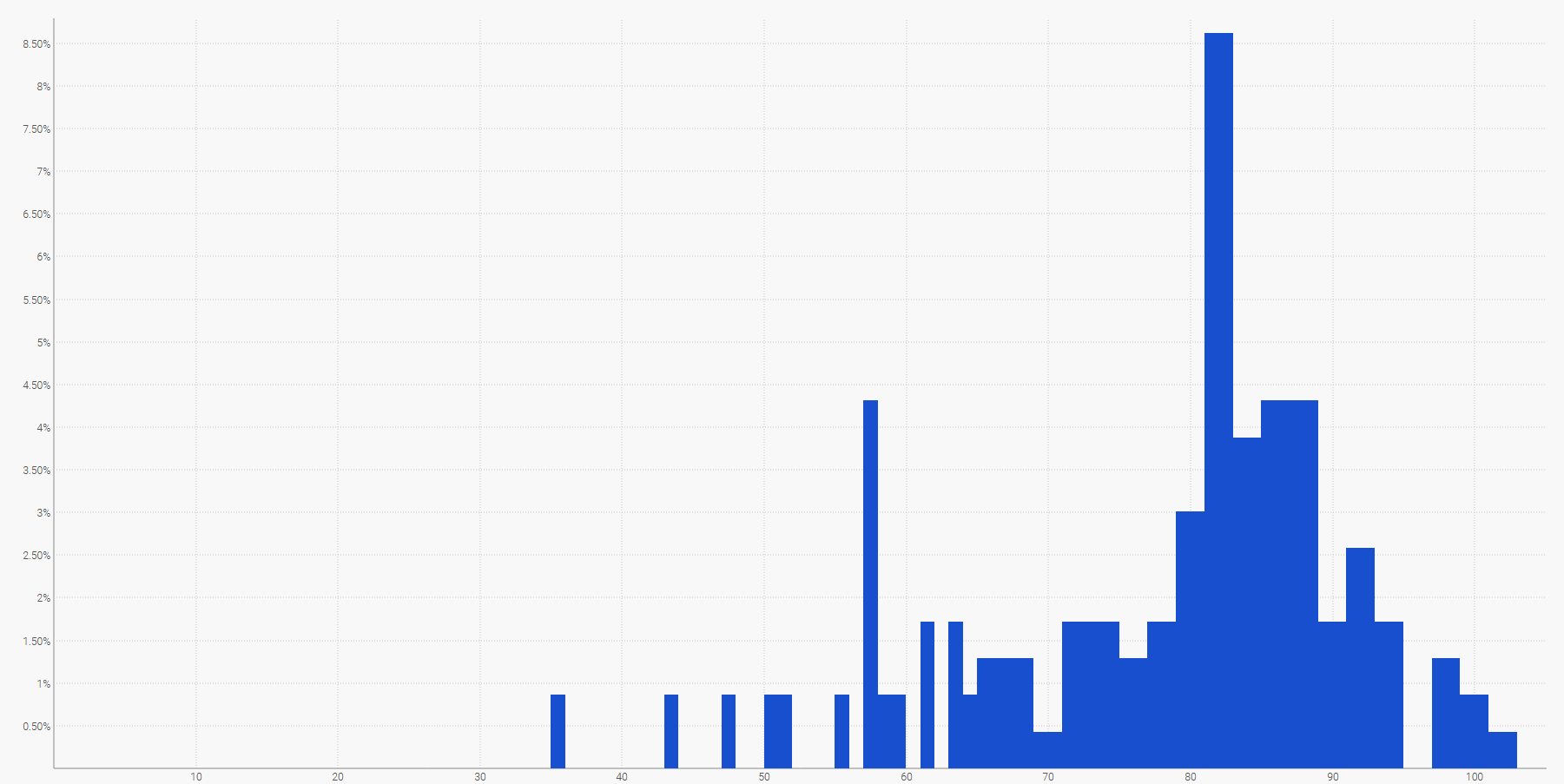
Distribución empírica de los tiempos de entrega observados en cubos (buckets) diarios.La demanda futura, sumada a lo largo de un período de tiempo específico, también puede representarse con un histograma. En general, el histograma es adecuado para todas las variables aleatorias unidimensionales superiores a $\mathbb{Z}$, el conjunto de enteros relativos.
La visualización del equivalente probabilístico de una serie de tiempo equidistante — es decir, una cantidad que varía a lo largo de períodos de tiempo discretos de igual longitud— ya es mucho más compleja. De hecho, a diferencia de la variable aleatoria unidimensional, no existe una visualización canónica de una distribución de ese tipo. Es importante considerar que no se puede suponer que los períodos sean independientes. Por lo tanto, si bien es posible representar una serie de tiempo "probabilística" alineando una serie de histogramas —uno por período—, el resultado sería una pésima representación de la manera en que suceden los eventos en una cadena de suministro.
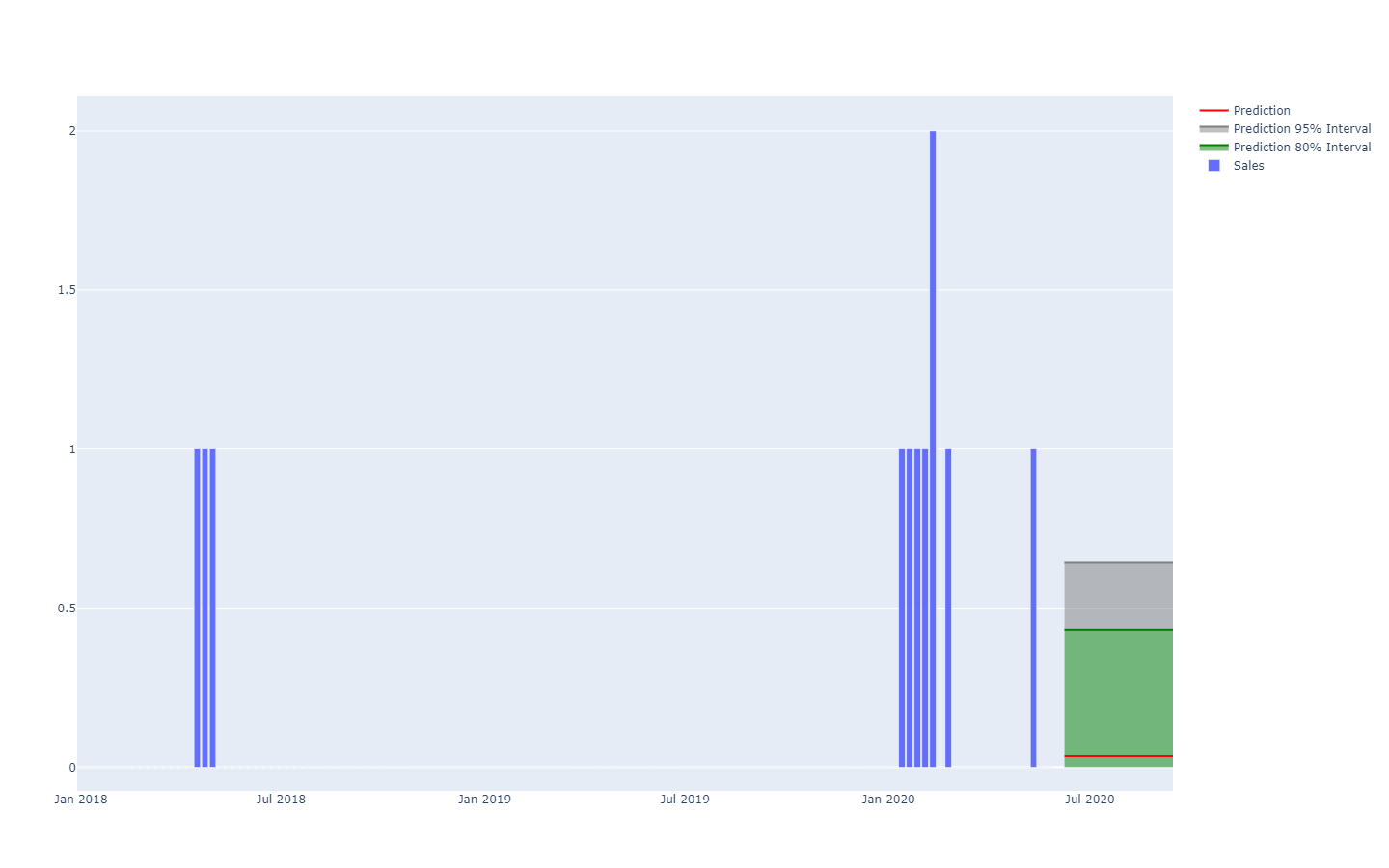
Pronóstico probabilístico de demanda representado mediante umbrales de cuantiles.Por ejemplo, no es demasiado improbable que un producto que acaba de lanzarse tenga un buen rendimiento y alcance volúmenes de ventas altos (un éxito). Tampoco es demasiado improbable que el mismo producto apenas lanzado fracase y genere volúmenes de ventas bajos (un fracaso). Sin embargo, es muy improbable que haya amplias oscilaciones entre niveles altos y bajos de ventas diarias (éxitos y fracasos).
Los intervalos de predicción, como se encuentran comúnmente en la bibliografía de cadena de suministro, son un tanto engañosos, ya que tienden a poner el énfasis en las situaciones de baja incertidumbre, que no son representativas de las situaciones reales de cadena de suministro.
Extracto de Visualization of probabilistic forecasts, de Rob J Hyndman, 21 de noviembre de 2014Vea cómo, puestos junto a un esquema de coloración para delinear umbrales de cuantiles específicos, estos intervalos de predicción coinciden exactamente con las distribuciones de probabilidad.
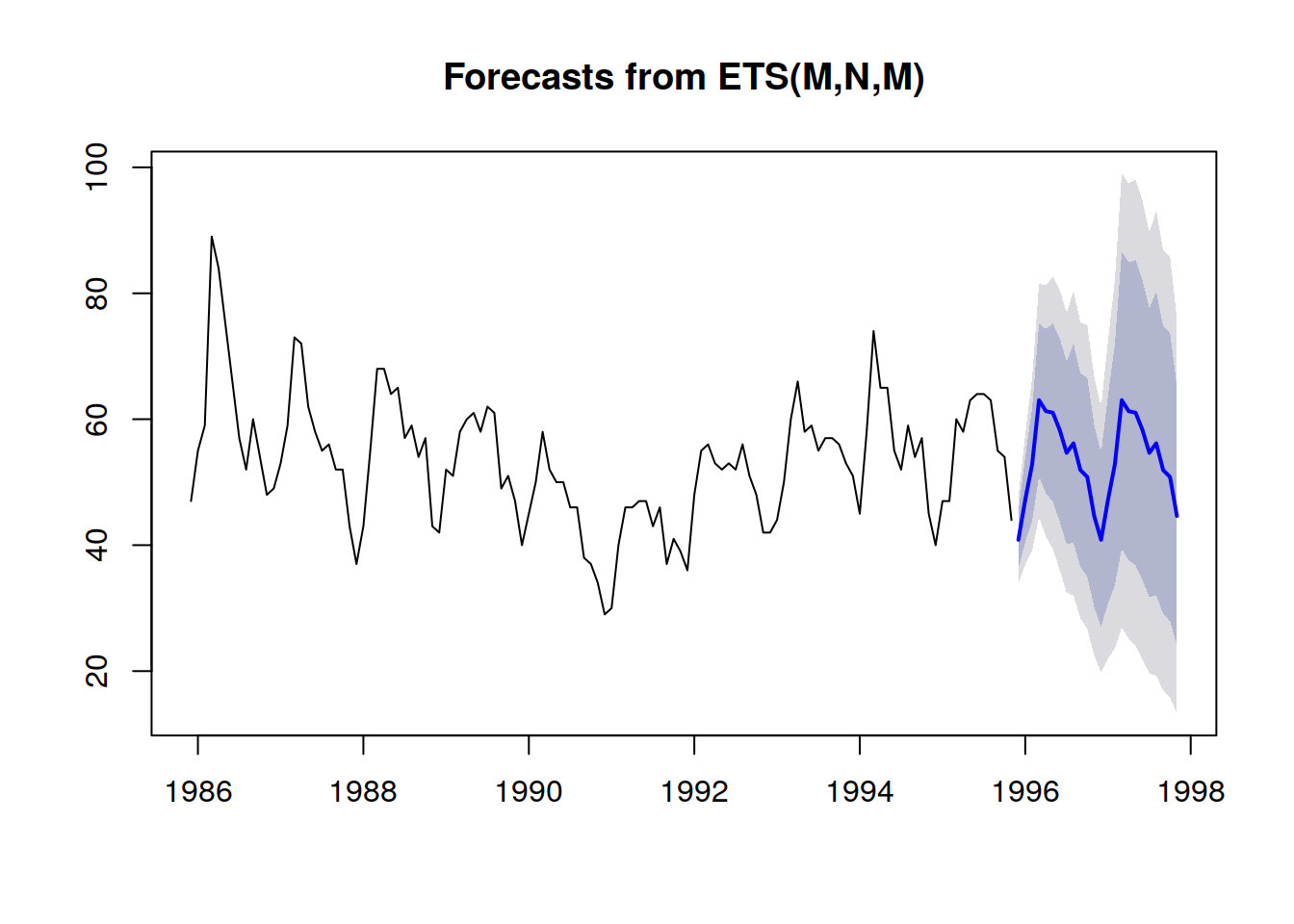
Es posible obtener una mejor representación —es decir, una que no mejora las fuertes dependencias entre períodos— observando los valores
acumulativos a lo largo del tiempo, tomar los cuantiles de estos y luego diferenciar para obtener incrementos por período (vea la primera ilustración de un pronóstico probabilístico proporcionada al comienzo de este artículo). La visualización es la misma, pero la
semántica subyacente difiere. Ahora observamos cuantiles en
escenarios, que muestran los escenarios extremadamente favorables (con respecto a los desfavorables).
Antipatrones en el pronóstico probabilístico
Los pronósticos probabilísticos cuestionan la manera en que muchos piensan "de manera intuitiva" en el futuro. En esta sección, repasamos algunos de los aspectos más incomprendidos del pronóstico probabilístico.
No existen los eventos "impredecibles"
Desde la perspectiva determinística, pronosticar el resultado de la lotería es imposible, ya que las probabilidades de acertar son "una en un millón". Sin embargo, desde una perspectiva probabilística, el problema es trivial: cada boleto tiene una probabilidad de "uno en un millón" de ganar. La altísima varianza del resultado no debería confundirse con el aspecto de "incognoscibilidad" del fenómeno mismo, que puede perfectamente comprenderse, como en el caso de la lotería. El pronóstico probabilístico tiene como objetivo cuantificar y estructurar la varianza, no eliminarla.
No existen las distribuciones "normales"
Las distribuciones normales, también conocidas como distribuciones gaussianas, son omnipresentes en los manuales tanto de cadena de suministro como de física. No obstante, cuando se trata de asuntos humanos, casi nada se distribuye "normalmente". Las distribuciones normales, por diseño, hacen que las grandes desviaciones (comparadas con las desviaciones promedio) sean muy raras, hasta el punto que el modelo mismo las excluye considerándolas imposibles; es decir, las probabilidades son menos de una en mil millones. La demanda, el tiempo de entrega, las devoluciones son patrones que categóricamente no muestran una distribución normal. La única ventaja de las distribuciones normales es que son adecuadas para realizar ejercicios de manual para los estudiantes, ya que se prestan a soluciones analíticas explícitas.
Eligiendo probabilidades
Al enfrentarse a una distribución de probabilidad, resulta tentador elegir un puno de la distribución, posiblemente la media o la mediana, y proceder sobre la base de ese número. Este proceso va en contra de la esencia misma del aspecto probabilístico del pronóstico. Las probabilidades no deberían reducirse a una estima de un solo punto, porque, independientemente del punto que se elija, este proceso incurre en una enorme pérdida de información. Por lo tanto, aunque pueda resultar un poco inquietante, las probabilidades están pensadas para ser preservadas como tales el mayor tiempo posible. El punto de quiebre es generalmente la última decisión de la cadena de suministro, que maximiza los retornos al tiempo que afronta futuros inciertos.
Eliminación de valores estadísticos atípicos
La mayoría de los métodos numéricos clásicos —firmemente anclados en la perspectiva determinística de los pronósticos (por ej., las medias móviles)— se comportan muy mal cuando se encuentran con valores estadísticos atípicos. Por lo tanto, muchas empresas establecen procesos para "limpiar" manualmente esos valores atípicos de los datos históricos. Sin embargo, esta necesidad de un proceso de limpieza de tal envergadura no hace más que poner en evidencia las deficiencias de esos métodos numéricos. Los valores estadísticos atípicos son, en realidad, un ingrediente esencial del pronóstico probabilístico, ya que contribuyen a tener una mejor idea de lo que está pasando
en la cola de la distribución. Dicho de otro modo, esos valores atípicos son la clave para cuantificar la probabilidad de encontrar más valores atípicos.
Armarse con las herramientas equivocadas
Se requieren herramientas especializadas para manipular distribuciones de probabilidad. La elaboración del pronóstico probabilístico es solo uno de los muchos pasos para entregar un valor real a cualquier la empresa. Muchos profesionales de la cadena de suministro acaban desestimando los pronósticos probabilísticos por falta de herramientas adecuadas para hacer algo con ellos. Muchos proveedores de software empresarial se han unido al movimiento y ahora afirman admitir el "pronóstico probabilístico" (junto con la 'IA" y la "blockchain"), pero en realidad no han logrado hacer más que una implementación cosmética de unos pocos modelos probabilísticos (vea la sección anterior). Mostrar un modelo de pronóstico probabilístico no vale nada sin las herramientas que se necesitan para aprovechar sus resultados numéricos.
Notas
[1]: La función
smooth() en Envision es útil para regularizar las variables aleatorias a través de un proceso de muestra discreto de algún tipo.
[2]: El conocimiento previo sobre la estructura del problema no debería confundirse con el conocimiento previo de la solución misma. Los "sistemas expertos" que fueron líderes allá por los años 50 como una recopilación de reglas escritas a mano fallaron, porque, en la práctica. los expertos humanos fallan en la traducción literal de su intuición en reglas numéricas. Los
structural priors (o conocimientos previos estructurales), como se usan en la programación diferenciable, delinean el principio, no los detalles, de la solución.


