Supply chain problems are
wicked and attempting to address them
sans appropriate programming tools - in the context of a large-scale company - proves an invariably costly learning experience. Effectively optimizing supply chain - a scattered network of physical and abstract complexities – requires a suite of modern, agile, and innovative programming paradigms. These paradigms are integral to the successful identification, consideration, and resolution of the vast and varied array of problems inherent to supply chain.
Watch the Lecture

Static Analysis
One need not be a computer programmer to think like one, and proper analysis of supply chain issues is best tackled with a programming mindset, not just programming tools. Traditional software solutions (such as ERPs) are designed in such a way that problems are addressed at
run-time rather than
compile-time.
[a] This is the difference between a
reactive solution and a
proactive one. This distinction is crucial because reactive solutions tend to be much more costly than proactive ones, both in terms of finances and bandwidth. These largely avoidable costs are precisely what a programming mindset aims to avoid, and
static analysis is the expression of this framework.
Static analysis involves inspecting a program (in this case, the optimization) without running it, as a means of identifying potential issues
before they can impact production. Lokad approaches static analysis through
Envision, its domain-specific language (DSL). This allows for the identification and correction of mistakes at the design-level (
in the programming language) as swiftly and conveniently as possible.
Consider a company in the process of building a warehouse. One does not erect the warehouse and then contemplate its layout. Rather, the strategic arrangement of aisles, racks and loading docks would be considered ahead of time, so as to identify potential bottlenecks in advance of construction. This allows for optimal design - and thus flow - within one's future warehouse. This careful blueprinting is analogous to the brand of static analysis Lokad accomplishes through Envision.
Static analysis, as described here, would model the underlying programming of the optimization and identify any potentially adversarial behaviors within the recipe
before installing it. These adversarial tendencies could include a bug that results in the accidental ordering of far more stock than needed. As a result, any such bugs would be expunged from the code before they have the chance to wreak havoc.
Array programming
In supply chain optimization, strict timing is essential. For instance, in a retail chain, data must be consolidated, optimized, and passed on to the warehouse management system within a 60-minute window. If calculations take too long, the entire supply chain's execution can be jeopardized. Array programming addresses this issue by eliminating certain classes of programming errors and guaranteeing calculation duration, thus providing supply chain practitioners with a predictable time horizon for the processing of data.
Also known as
data frame programming, this approach allows operations to be performed directly on data arrays, rather than isolated datum. Lokad does this by leveraging Envision, its DSL. Array programming can simplify data manipulation and analysis, such as by performing operations on entire columns of data rather than individual entries within each table. This dramatically increases the efficiency of the analysis and in turn reduces the chances of bugs in the programming.
Consider a warehouse manager who has two lists: List A is current stock levels, and List B is incoming shipments for the products in List A. Instead of going through each product one by one and manually adding the incoming shipments (List B) to the current stock levels (List A), a more efficient method would be to process both lists simultaneously, thus allowing you to update inventory levels for all products in one fell swoop. This would conserve both time and effort, and is essentially what array programming seeks to do.
[b] In reality, array programming makes it easier to parallelize and distribute computation of the vast amounts of data involved in supply chain optimization. By distributing computation across multiple machines, costs can be reduced and execution times shortened.
Hardware miscibility
One of the main bottlenecks in supply chain optimization is the limited number of supply chain scientists. These scientists are responsible for creating numerical recipes that factor clients’ strategies, as well as the antagonistic machinations of competitors, to produce actionable insights.
Not only can these experts be hard to source, but once they are they often must clear several hardware hurdles separating them from the speedy execution of their tasks.
Hardware miscibility - the ability for various components within a system to blend and work together - is crucial to removing these obstacles. There are three fundamental computing resources considered here:
- Compute: The processing power of a computer, provided by either the CPU or GPU.
- Memory: The data storage capacity of a computer, hosted through RAM or ROM.
- Bandwidth: The maximum rate at which information (data) can be transferred between different parts of a computer, or across a network of computers.
Processing large data sets is generally a time-consuming process, resulting in lower productivity as engineers await job execution. In a supply chain optimization, one could store snippets of code (representing routine intermediate calculation steps) on solid-state drives (SSDs). This simple step allows supply chain scientists to run similar
scripts featuring only minor changes much more quickly, thus significantly boosting productivity.
In the above example, one has leveraged a cheap
memory hack to lower the
compute overhead: the system notes that the script being processed is almost identical to previous ones, hence the compute can be performed in seconds rather than tens of minutes.
This kind of hardware miscibility allows companies to extract the greatest value from their dollars of investment.
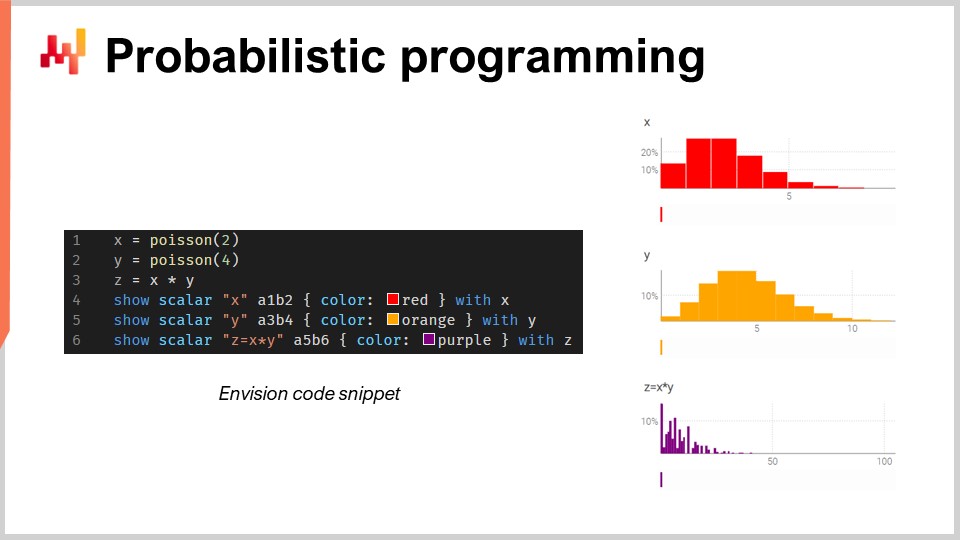
Probabilistic programming
There are an infinite number of possible future outcomes, they are just not all equally probable. Given this irreducible uncertainty, one's programming tool(s) must adopt a probabilistic forecasting paradigm. Though
Excel has historically been the bedrock of many supply chains, it cannot be deployed at scale using probabilistic forecasts, as this type of forecasting requires the capacity to process the algebra of random variables.
[c] Succinctly, Excel is primarily designed for deterministic data (i.e., fixed values, such as static whole numbers). Though it can be modified to perform some probability functions, it lacks the advanced functionality - and overall flexibility and expressiveness - required to cope with the complex random variable manipulation one encounters in probabilistic demand forecasting. Rather, a probabilistic programming language - such as Envision - is better suited to representing and processing the uncertainties one encounters in supply chain.
Consider an automotive aftermarket store selling brake pads. In this hypothetical scenario, customers must purchase brake pads in batches of 2 or 4 at a time, and the store must account for this uncertainty when forecasting demand.
If the store has access to a probabilistic programming language (as opposed to a sea of spreadsheets), they can much more accurately estimate the total consumption using the algebra of random variables - typically absent in general programming languages.
Differentiable programming
In the context of supply chain optimization, differentiable programming enables the numerical recipe to learn and adapt based on the data it is provided. Differentiable programming, once combined with a stochastic gradient descent, allows a supply chain scientist to discover complex patterns and relationships within the supply chain. Parameters are learned with every new programming iteration, and this process is repeated thousands of times. This is done to minimize the discrepancy between the current forecast model and past data.
[d] Cannibalization and substitution - within a single catalog - are two model issues worth unpacking in this context. In both scenarios, multiple products compete for the same clients, which presents a perplexing layer of forecasting complexity. The downstream effects of these forces are generally not captured by traditional time series forecasting, which primarily consider the trend, seasonality, and noise
for a single product, without accounting for the possibility of interaction(s).
Differentiable programming and stochastic gradient descent can be leveraged to address these problems, such as by analyzing the historical data of transactions linking clients and products. Envision is capable of performing such an investigation - named
affinity analysis - between customers and purchases by reading simple flat files containing sufficient historical depth: namely transactions, dates, products, clients, and purchase quantities.
[e] Using a mere handful of unique code, Envision can determine the affinity between a client and product, which permits the supply chain scientist to further optimize the numerical recipe that delivers the recommendation of interest.
[f]Versioning code & data
An overlooked element of long-term optimization viability is ensuring the numerical recipe - including every constituent snippet of code and crumb of data - can be sourced, tracked, and reproduced.
[g] Without this versioning capability, one's capacity to reverse-engineer the recipe is greatly diminished when maddening exceptions inevitably arise (
heisenbugs in computer circles).
Heisenbugs are pesky exceptions that cause issues in optimization calculations, but disappear when the process is rerun. This can make them inordinately difficult to fix, resulting in some initiatives failing and the supply chain reverting to Excel spreadsheets. To avoid heisenbugs, complete replicability of the optimization's logic and data is necessary. This requires versioning all the code and data used in the process, ensuring that the environment can be replicated to the exact conditions of any previous point in time.
Secure programming
Beyond rogue heisenbugs, the increased digitization of supply chain carries a consequent vulnerability to digital threats, such as cyberattacks and ransomware. There are two primary - and usually unwitting - vectors of chaos in this regard: the programmable system(s) one uses, and the people one allows to use them. Regarding the latter, it is very difficult to account for accidental incompetence (to say nothing of incidents of intentional malevolence); regarding the former, the intentional design-level choices one makes are paramount in sidestepping these landmines.
Rather than investing precious resources increasing one's cyber security team (in anticipation of
reactive behavior, such as firefighting), prudent decisions in the programming system design phase can eliminate entire classes of downstream headaches. By removing redundant features - such as an SQL database in Lokad's case - one can prevent predictable catastrophes - such as an SQL injection attack. Similarly, opting for append-only persistence layers (as Lokad does) means that deleting data (by friend or foe) is much more difficult.
[h] While Excel and Python have their boons, they lack the programming security necessary for the protection of all the code and data required for the type of scalable supply chain optimization discussed in these lectures.
Notes
a. Compile-time refers to the stage when a program's code is being converted into a machine-readable format before it is executed. Run-time refers to the stage when the program is actually being executed by the computer.
b. This is a very rough approximation of the process. Reality is much more complex, but that is the remit of computer boffins. For now, the thrust is that array programming results in a much more streamlined (and cost efficient) computation process, the benefits of which are plentiful in the context of supply chain.
c. In plain terms, this refers to the manipulation and combination of random values, such as computing the outcome of a dice roll (or several hundred thousand dice rolls, in the context of a large supply chain network). It encompasses everything from basic addition, subtraction and multiplication to far more complex functions like finding variances, covariances, and expected values.
d. Consider trying to perfect an actual recipe. There may be a baseline schema you draw on, but obtaining the perfect balance of ingredients - and preparation - proves elusive. There are, in fact, not only taste considerations to a recipe, but texture and appearance ones, too. To find the perfect iteration of the recipe, one makes minute adjustments and notes the results. Rather than experimenting with every conceivable condiment and cooking utensil, one makes educated tweaks based on the feedback one observes with each iteration (e.g., adding a soupçon more or less salt). With each iteration, one learns more about the optimal proportions, and the recipe evolves. At its core, this is what differentiable programming and stochastic gradient descent do with the numerical recipe in a supply chain optimization. Please review the lecture for the mathematical fine print.
e. When a strong affinity is identified between two products already in one’s catalog, it may indicate that they are complementary, meaning they are often purchased together. If customers are found to switch between two products with a high degree of similarity, it may suggest substitution. However, if a new product exhibits a strong affinity with an existing product and causes a decrease in the sales of the existing product, it may indicate cannibalization.
f. It should go without saying that these are simplified descriptions of the mathematical operations involved. That said, the mathematical operations are not terribly confounding, as explained in the lecture.
g. Popular versioning systems include Git and SVN. They allow multiple people to work on the same code (or any content) simultaneously and merge (or reject) changes.
h. Append-only persistence layer refers to a data storage strategy where new information is added to the database without modifying or deleting existing data. Lokad's append-only security design is covered in its extensive security FAQ.