By Joannes Vermorel, December 2022La BI (Business Intelligence) fait référence à une catégorie de logiciels d'entreprise dédiés à la production de rapports analytiques principalement basés sur les données transactionnelles collectées par les différents systèmes d'affaires que l'entreprise utilise pour fonctionner. La BI est destinée à offrir des capacités de reporting en libre-service aux utilisateurs qui ne sont pas des spécialistes de l'informatique. Ces capacités d'auto-assistance peuvent aller de l'ajustement des paramètres des rapports existants à la création de rapports entièrement nouveaux. La plupart des grandes entreprises disposent d'au moins un système de BI en plus de leurs systèmes transactionnels, qui comprennent souvent un ERP.
Origines
Le rapport analytique moderne est apparu avec les premiers prévisionnistes économiques
[1] [2]principalement aux États-Unis, au début du 20e siècle. Cette première version s'est avérée extrêmement populaire auprès de la presse grand public et a bénéficié d'une large diffusion. Cette popularité a démontré qu'il existait un intérêt prononcé pour les rapports quantitatifs denses en information. Dans les années 1980, de nombreuses grandes entreprises ont commencé à conserver leurs transactions commerciales sous forme d'enregistrements électroniques, stockés dans des bases de données transactionnelles, en s'appuyant généralement sur les premières solutions
ERP. Ces solutions ERP étaient principalement destinées à rationaliser les processus existants, à améliorer la productivité et la fiabilité. Cependant, beaucoup ont compris l'énorme potentiel inexploité de ces enregistrements et, en 1983, SAP a introduit le langage de programmation ABAP
[3] dédié à la génération de rapports basés sur les données collectées dans l'ERP lui-même.
Cependant, les systèmes de bases de données relationnelles, tels qu'ils étaient vendus dans les années 1980, présentaient deux limites majeures en ce qui concerne la production de rapports analytiques. Tout d'abord, la conception des rapports devait être confiée à des spécialistes informatiques hautement qualifiés. Cela rendait le processus lent et coûteux, limitant fortement la diversité des rapports qui pouvaient être introduits. Deuxièmement, la génération des rapports était très éprouvante pour le matériel informatique. Les rapports ne pouvaient généralement être produits que pendant la nuit (et en lot), lorsque les opérations de l'entreprise avaient cessé. Dans une certaine mesure, cela reflétait les limites du matériel informatique de l'époque, mais aussi les limites des
logiciels.
Au début des années 1990, les progrès du matériel informatique ont permis l'émergence d'une classe différente de solutions logicielles
[4], les solutions de
Business Intelligence. Le coût de la RAM (mémoire vive) n'a cessé de
diminuer, tandis que sa capacité de stockage n'a cessé d
'augmenter. Par conséquent, le stockage d'une version spécialisée et plus compacte des données commerciales
en mémoire (en RAM) pour un accès immédiat est devenu une solution viable, tant du point de vue technologique qu'économique. Ces développements ont permis de remédier aux deux principales limites des systèmes de reporting tels qu'ils avaient été mis en œuvre dix ans plus tôt : les nouveaux logiciels front-end étaient beaucoup plus accessibles aux non-spécialistes et les nouveaux logiciels back-end dotés de technologies OLAP (voir ci-dessous) - ont éliminé certaines des principales contraintes informatiques. Grâce à ces avancées, à la fin de la décennie, les solutions de BI étaient devenues courantes dans les grandes entreprises
Le matériel informatique ayant continué à progresser, une nouvelle génération d'outils de BI est apparue
[5] à la fin des années 2000. Les systèmes de bases de données relationnelles des années 1980, qui étaient incapables de produire des rapports de manière pratique, sont devenus, dans les années 2000, de plus en plus capables de conserver en mémoire vive l'historique complet des transactions d'une entreprise. Par conséquent, des requêtes analytiques complexes pouvaient être réalisées en quelques secondes
sans recours à un back-end OLAP dédié. Ainsi, les solutions de BI se sont concentrées sur le front-end, offrant des interfaces utilisateur web encore plus accessibles - principalement SaaS (Software-as-a-Service) - tout en présentant des tableaux de bord de plus en plus interactifs qui exploitent la polyvalence du back-end relationnel.
OLAP et cubes multidimensionnels
OLAP est l'abréviation de
online analytical processing (traitement analytique en ligne). OLAP est associé à la conception du back-end d'une solution BI. Ce terme, inventé en 1993 par Edgar Codd, fédère une série d'idées de conception de logiciels
[6], la plupart antérieures aux années 1990, certaines remontant aux années 1960. Ces idées de conception ont contribué à l'émergence de l'informatique décisionnelle en tant que catégorie distincte de produits logiciels dans les années 1990. OLAP a relevé le défi de pouvoir produire des rapports analytiques récents
en temps voulu, même lorsque la quantité de données impliquée dans la production du rapport était trop importante pour être traitée rapidement.
La technique la plus simple pour produire un nouveau rapport analytique consiste à
lire les données au moins une fois. Toutefois, si l'ensemble des données est si volumineux
[7] que sa lecture intégrale prend des heures (voire des jours), la production d'un nouveau rapport prendra également des heures ou des jours. Ainsi, pour produire un rapport actualisé en quelques secondes, la technique ne peut pas impliquer la relecture de l'ensemble des données à chaque fois qu'un renouvellement du rapport est demandé.
OLAP propose d'exploiter des structures de données plus petites et plus compactes - reflétant les rapports d'intérêt. Ces structures de données spécifiques sont destinées à être mises à jour au fur et à mesure que de nouvelles données sont disponibles. Par conséquent, lorsqu'un nouveau rapport est demandé, le système de BI ne doit pas relire l'ensemble des données historiques, mais uniquement la structure de données compacte qui contient toutes les informations nécessaires pour générer le rapport. De plus, si la structure de données est suffisamment petite, elle peut être conservée en mémoire (en RAM) et donc être accessible plus rapidement que le stockage persistant utilisé pour les données transactionnelles.
Prenons l'exemple suivant : imaginez un réseau de vente au détail exploitant 100 hypermarchés. Le directeur financier veut un rapport sur les ventes totales en euros par magasin et par jour au cours des trois dernières années. Les données historiques brutes sur les ventes des trois dernières années représentent plus d'un milliard de lignes de données (tous les codes-barres scannés dans tous les magasins pendant cette période), et plus de 50 Go dans leur format tabulaire brut. Cependant, un tableau de 100 colonnes (1 par hypermarché) et 1095 lignes (3 ans * 365 jours) correspond à moins de 0,5MB (à raison de 4 octets par numéro). En outre, chaque fois qu'une transaction a lieu, les cellules correspondantes du tableau peuvent être mises à jour en conséquence. La création et la maintenance d'un tel tableau illustrent ce à quoi ressemble un système OLAP sous le capot.
Les structures de données compactes décrites ci-dessus prennent généralement la forme d'un
cube OLAP, également appelé cube multidimensionnel. Les cellules existent dans le cube à l'intersection des dimensions discrètes qui définissent la structure globale du cube. Chaque cellule contient une mesure (ou valeur) extraite des données transactionnelles d'origine, souvent appelées
tableaux des valeurs. Cette structure de données est similaire aux tableaux multidimensionnels que l'on trouve dans la plupart des langages de programmation courants. Le cube OLAP se prête à des opérations efficaces de projection ou d'agrégation le long des dimensions (comme la sommation et la moyenne), étant donné que le cube reste suffisamment petit pour tenir dans la mémoire de l'ordinateur.
Rapports interactifs et visualisation des données
Rendre les capacités de reporting accessibles aux utilisateurs finaux qui ne sont pas des spécialistes de l'informatique a été un facteur clé dans l'adoption des outils de BI. La technologie a donc adopté une conception WYSIWYG (
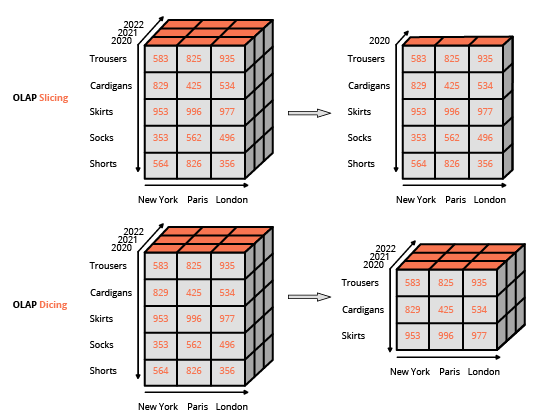
what-you-see-is-what-you-get), reposant sur des interfaces utilisateur complètes. Cette approche diffère de l'approche habituelle pour interagir avec une base de données relationnelle, qui consiste à composer des requêtes en utilisant un langage spécialisé (comme SQL). L'interface habituelle pour manipuler un cube OLAP est une interface matricielle, comme les tableaux croisés dynamiques dans un tableur, qui permet aux utilisateurs d'appliquer des filtres (appelés
slice and dice ) et d'effectuer des agrégations (moyenne, min, max, somme, etc.).
Sauf pour le traitement d'ensembles de données particulièrement volumineux, le besoin de cubes OLAP a baissé à la fin des années 2000, parallèlement aux énormes progrès réalisés dans le matériel informatique. De nouveaux outils de BI "légers" ont été introduits en mettant l'accent exclusivement sur le front-end. Les outils de BI légers étaient principalement conçus pour interagir avec des bases de données relationnelles, contrairement à leurs prédécesseurs "lourds" qui exploitaient des back-ends intégrés comportant des cubes OLAP. Cette évolution a été possible parce que les performances des bases de données relationnelles, à l'époque, permettaient généralement d'exécuter des requêtes complexes sur l'ensemble des données en quelques secondes - là encore, tant que l'ensemble de données restait inférieur à une certaine taille. Les outils de BI légers peuvent être considérés comme des éditeurs WYSIWYG unifiés pour les différents dialectes SQL qu'ils supportent. (En fait, sous le capot, ces outils de BI génèrent des requêtes SQL). Le principal défi technique était l'optimisation des requêtes générées, afin de minimiser le temps de réponse de la base de données relationnelle sous-jacente.
Les capacités de
visualisation des données des outils de BI se limitaient essentiellement à la présentation des données du côté client, par le biais d'une application de bureau ou Web. Les capacités de présentation ont progressé régulièrement jusqu'aux années 2000, lorsque le matériel de l'utilisateur final (par exemple, les stations de travail et les ordinateurs portables) a commencé à dépasser largement (en termes de calcul) ce qui était nécessaire pour la visualisation des données. De nos jours, même les visualisations de données les plus élaborées sont des processus peu contraignants, dont l'ampleur est éclipsée par la consommation de ressources informatiques associées à l'extraction et à la transformation des données sous-jacentes visualisées.
L'impact organisationnel de la BI
Si la facilité d'accès a été un facteur décisif pour l'adoption de la plupart des outils de BI, il est difficile de naviguer dans le champ des données des grandes entreprises, ne serait-ce qu'en raison de la diversité des données disponibles. De plus, même si l'outil de BI est relativement accessible, la logique de reporting que les entreprises mettent en œuvre par le biais des outils de BI tend à refléter la complexité de l'entreprise et, par conséquent, la logique elle-même peut être beaucoup moins accessible que l'outil qui soutient son exécution.
En conséquence, l'adoption d'outils de BI a conduit - pour la plupart des grandes entreprises - à la création d'équipes d'analyse dédiées, qui opèrent généralement comme une fonction de soutien aux côtés du département informatique. Comme le prévoit la loi de Parkinson,
le travail s'étend de manière à remplir le temps disponible pour sa réalisation ; ces équipes ont tendance à s'étendre au fil du temps, parallèlement au nombre de rapports générés, indépendamment des avantages (perçus ou réels) que l'entreprise tire de l'accès à ces rapports.
Limites techniques de la BI
Comme souvent, il y a un compromis entre les vertus des outils de BI, c'est-à-dire qu'une plus grande facilité d'accès se fait au détriment de
l'expressivité ; dans ce cas, les transformations appliquées aux données sont limitées à une classe relativement étroite de filtres et d'agrégations. Il s'agit là de la première limite majeure, car de nombreuses questions commerciales - si ce n'est la plupart - ne peuvent être abordées avec ces opérateurs (par exemple,
quel est le risque de résiliation d'un client ?). Bien sûr, il est
possible d'introduire des opérateurs avancés dans l'interface utilisateur de la BI, mais de telles fonctionnalités "avancées" vont à l'encontre
[8]de l'objectif initial de rendre l'outil facilement accessible aux utilisateurs non techniques. En tant que telle, la conception de requêtes de données avancées n'est pas différente de la création de logiciels, une tâche qui s'avère intrinsèquement difficile. Anecdotiquement, la plupart des outils de BI offrent la possibilité d'écrire des requêtes "brutes" (typiquement en SQL ou dans un dialecte similaire à SQL), retombant ainsi sur le chemin technique que l'outil était censé éliminer.
La deuxième limite majeure est la
performance. Cette limite se présente sous deux formes distinctes, respectivement pour les outils de BI légers et lourds. Les outils de BI légers comprennent généralement une logique sophistiquée pour optimiser les requêtes de base de données qu'ils génèrent. Cependant, ces outils sont en fin de compte limités par les performances que peut offrir la base de données servant de back-end. Une requête apparemment simple peut s'avérer inefficace dans l'exécution, entraînant des temps de réponse longs. Un ingénieur en bases de données peut certainement modifier et améliorer la base de données pour répondre à cette préoccupation. Cependant, une fois de plus, cette solution va à l'encontre de l'objectif initial qui est de rendre l'outil de BI accessible aux utilisateurs non techniques.
Les outils de BI lourds voient leurs performances limitées par la conception des cubes OLAP eux-mêmes. Tout d'abord, la quantité de RAM nécessaire pour garder en mémoire un cube multidimensionnel augmente rapidement au fur et à mesure que les dimensions du cube augmentent. Même un nombre modéré de dimensions (par exemple, 10) peut entraîner de graves problèmes liés à l'empreinte mémoire du cube. Plus généralement, les conceptions en mémoire (les cubes OLAP étant les plus fréquents) ont généralement des problèmes liés à la mémoire.
En outre, le cube est une représentation
avec perte des données transactionnelles d'origine : aucune analyse effectuée avec le cube ne peut récupérer des informations qui ont été perdues en premier lieu. Rappelons l'exemple de l'hypermarché. Dans un tel scénario, les paniers ne peuvent pas être représentés dans un cube. Ainsi, l'information "acheté ensemble" est perdue. La conception globale du "cube" de l'OLAP limite sévèrement les données qui peuvent même être représentées ; cependant, cette limite est précisément ce qui rend la propriété "en ligne" possible en premier lieu.
Les limites commerciales de la BI
L'introduction d'outils de BI dans une entreprise est moins transformatrice qu'il n'y paraît. En d'autres termes, la production de chiffres, en soi, n'a aucune valeur pour l'entreprise si aucune action n'est associée à ces chiffres. La conception même des outils de BI met l'accent sur une production "illimitée" de rapports, mais la conception ne soutient aucun plan d'action réel. En fait, dans la plupart des situations, le peu d'expressivité des outils de BI s'avère trop limitatif lorsqu'il s'agit d'automatiser quoi que ce soit sur la base des rapports de BI.
En outre, l'outil de BI a tendance à exacerber les tendances bureaucratiques des grandes entreprises. Des preuves anecdotiques, des chiffres approximatifs et un jugement sûr suffisent souvent à établir les priorités d'une entreprise. Cependant, l'existence d'un outil d'analyse autonome- comme la BI - offre de nombreuses occasions de tergiverser et de brouiller les pistes avec un flot incessant de mesures discutables et non exploitables.
Les outils de BI sont vulnérables aux problèmes de
conception en comité, où les idées de chacun sont incluses dans le projet. La nature libre-service de l'outil met l'accent sur une approche largement inclusive lorsqu'il s'agit d'introduire de nouveaux rapports. En conséquence, la complexité du champ des rapports tend à s'accroître au fil du temps, indépendamment de la complexité des activités que ces rapports sont censés refléter. Le terme
vanity metrics est devenu largement utilisé pour désigner des mesures - généralement mises en œuvre par le biais d'un outil de BI - comme celles-ci, qui ne contribuent pas aux résultats de l'entreprise.
L'avis de Lokad
Compte tenu des capacités du matériel informatique moderne, il est facile d'utiliser un système d'établissement de rapports pour produire 1 million de chiffres par jour ; il est difficile de produire 10
chiffres par jour qui méritent d'être lus. Si un outil de BI utilisé à petites doses est une bonne chose pour la plupart des entreprises, à plus fortes doses, il devient un poison.
Dans la pratique, la BI ne permet qu'une quantité limitée d'informations. L'introduction d'un nombre croissant de rapports a un rendement rapidement décroissant en termes de nouvelles perspectives (ou d'améliorations) obtenues grâce à chaque rapport supplémentaire. Il faut garder en tête que la profondeur des analyses de données accessibles à partir d'un outil de BI est
limitée par la conception, car les requêtes doivent rester facilement accessibles aux non-spécialistes par le biais de l'interface utilisateur.
En outre, même si les données permettent d'acquérir de nouvelles connaissances, cela ne signifie pas que l'entreprise peut en tirer quelque chose d'exploitable. La BI est, à la base, une technologie de
reporting : elle ne met pas l'accent sur un appel à l'action pour l'entreprise. Le paradigme de la BI n'est pas orienté vers l'automatisation des décisions d'affaires (même les plus banales).
Lokad
offre des capacités étendues de reporting sur mesure, comme la BI. Cependant, contrairement à la BI, Lokad vise l'optimisation des décisions d'affaires, plus spécifiquement de celles concernant la chaîne d'approvisionnement. Dans la pratique, nous recommandons qu'un
supply chain scientist soit chargé de la conception, puis de la maintenance, de la recette numérique qui génère - par le biais de Lokad - les décisions d'intérêt pour la chaîne d'approvisionnement.
References
1. Fortune Tellers: The Story of America's First Economic Forecasters, Walter Friedman (2013).
2. A Selection of Early Forecasting & Business Charts, Walter Friedman (2014) (PDF)
3. ABAP est un langage de programmation lancé par SAP en 1983. De l'allemand Allgemeiner Berichts-Aufbereitungs-Prozessor, il signifie processeur de préparation de rapports généraux. Ce langage a été introduit en tant que précurseur des systèmes de BI pour compléter l'ERP (également appelé SAP) avec des capacités de reporting. L'objectif de l'ABAP était d'alléger les frais généraux d'ingénierie associés à la mise en œuvre de rapports personnalisés. Dans les années 1990, ABAP a été reconverti en langage de configuration et d'extension pour l'ERP lui-même. Le langage a également été renommé en anglais Advanced Business Application Programming pour refléter ce changement d'orientation.
4. BusinessObjects, fondé en 1990 et racheté par SAP en 2008, est l'archétype des solutions de BI qui a fait surface dans les années 90.
5. Tableau, fondé en 2003 et racheté par Salesforce en 2019, est l'archétype des solutions de BI qui a fait surface dans les années 2000.
6. The origins of today’s OLAP products, Nigel Pendse, mise à jour en août 2007.
7. Depuis les années 1950, le matériel informatique n'a cessé de progresser. Cependant, chaque fois qu'il est devenu moins coûteux de "traiter" davantage de données, il est également devenu moins coûteux de "stocker" davantage de données. En conséquence, depuis les années 1970, la quantité de données commerciales a augmenté presque aussi rapidement que les capacités du matériel informatique. Ainsi, la notion de "trop de données" est en grande partie une cible mouvante.
8. Entre la fin des années 90 et le début des années 2000, beaucoup d'entreprises de logiciels ont tenté, en vain, de remplacer les langages de programmation avec des outils visuels. Voir aussi, Lego Programming, Joel Spolsky, décembre 2006.