使用 Envision 聚合数据
首页 » 资源 » 此处
所谓数据聚合,即通过使用称之为“聚合器”的特殊函数组合多个表行的过程。任何时候进行求和、求平均值、计数或求中间值的计算,都会使用聚合器来进行计算。聚合也为组合来自于不同表的数据提供了途径。Envision 提供了丰富的语法来支持所有这些应用方案。在本页面,我们将详细介绍和说明如何对 Envision 使用聚合器。
脚本示例
在本页面,从您的 Lokad 账户中的/sample 路径应同样可以访问样本数据集。下面这段脚本的复杂程度一般,它说明了 Envision 中可用的数据聚合模式。数据聚合既可在磁贴外部进行,也可在磁贴内部进行。建议您先阅读通过 ENVISION 执行计算,这样将大大有助于您理解本页的内容。
read "/sample/Lokad_Items.tsv" as Items
read "/sample/Lokad_Orders.tsv" as Orders
read "/sample/Lokad_PurchaseOrders.tsv" as PO
expect Orders.Quantity : number
show label "Filtering data with Envision" a1f1 tomato
oend := max(Orders.Date)
currency := mode(Orders.Currency)
totalPurchased := sum(PO.NetAmount)
totalSold := sum(Orders.NetAmount) when date >= oend - 365
show table "Total purchased{$}" a2c2 with totalPurchased
show table "Sold over 1 year{$}" d2f2 with totalSold
VolumeSold = sum(Orders.NetAmount)
UnitSold = median(Orders.Quantity)
show table "Top sellers" a3f4 tomato with
Name
VolumeSold as "Sold{$}"
UnitSold as "Median"
order by VolumeSold desc
avgRet := avg(distinct(Orders.Date) by Orders.Client)
avgQty := avg(sum(Orders.Quantity) by [Orders.Client, Orders.Date])
show table "Average client returns" a5c5 with round(avgRet)
show table "Average backet quantity" d5f5 with avgQty
Orders.Brand = Brand
show table "Top Suppliers" a6f7 tomato with
Supplier
distinct(Category) as "Categories"
sum(Orders.NetAmount) as "Sold{$}"
mode(Orders.Brand) if (Orders.Brand != "Fellowes") as "Most frequent brand sold"
group by Supplier
order by sum(Orders.NetAmount) desc
我们建议您先将这段脚本复制-粘贴到您的 Lokad 账户,然后运行该脚本以便观察生成的仪表板。如果一切正常,应当可以看到如下面所示的仪表板。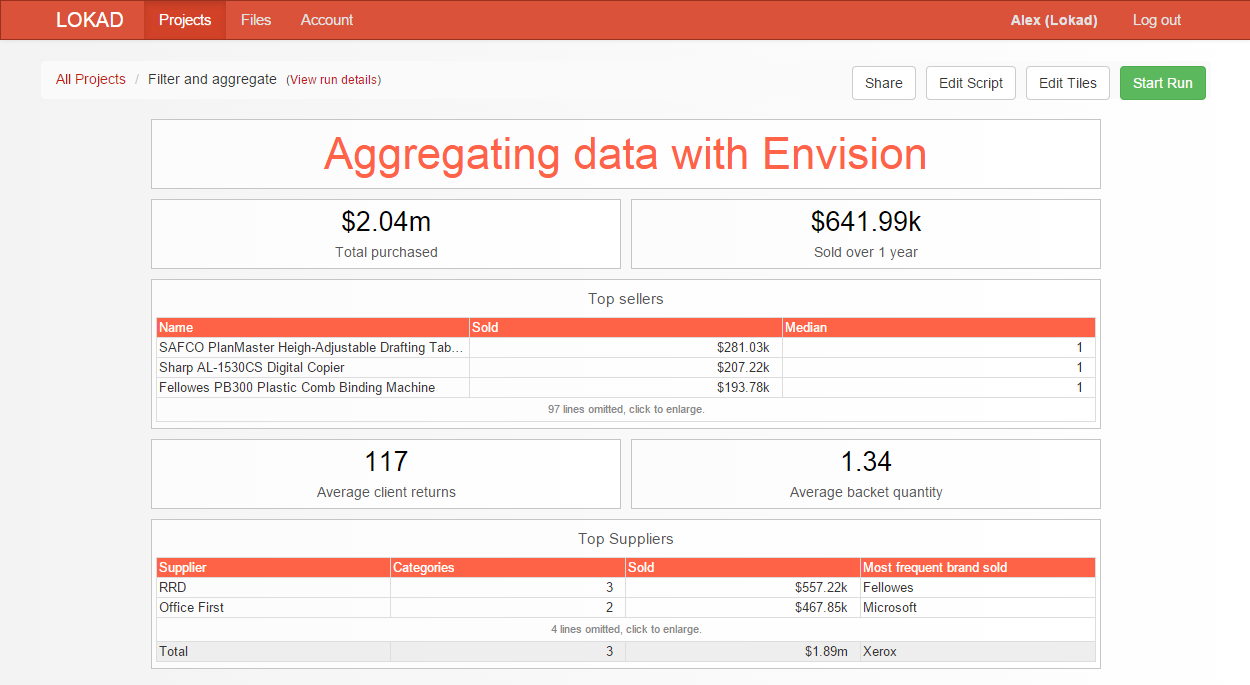
用于单值聚合的标量
在 Envision 中,没有“项目”仿射性的变量被称为“标量变量”(该变量不会附加在Items 表的任何一行)。与 Excel 相似,Envision 变量默认为类似于 Excel 的列:这些变量为向量,且同时存储了多个值(实际上是每个项目存储一个值)。但是,可能有的变量与单个 Excel 单元一样只存储一个值:这样的变量即标量变量。上面的脚本说明了计算两个标量变量的过程;为了清楚起见,我们将相关行复制到下面。
totalPurchased := sum(PO.NetAmount)
totalSold := sum(Orders.NetAmount) when date >= oend - 365
show table "Total purchased{$}" a2c2 with totalPurchased
show table "Sold over 1 year{$}" d2f2 with totalSold
从这几行代码可以突出几个方面。首先,第 1 行和第 2 行的两项赋值是使用标量赋值运算符执行的。这里使用的运算符是 :=,而不是普通的赋值运算符 =,说明聚合结果应为与项目无关的单一值。
其次,变量 totalPurchased 和 tableSold 的名称以小写字母开始。尽管在 Envision 中变量名称不区分大小写,但这两个变量在本例中的拼写并非偶然。作为一种编码习惯,我们建议将包含标量值的变量的第一个字母采用小写。相比之下,表名和列名则应以大写字母开始。遵循这些原则可以提高脚本的可读性且更易于调试。
第三,在表只有一列的情况下,标量聚合默认为在 show table 语句中进行。例如,第 1 行和第 3 行可以结合为一行,如下所示。
show table "Total purchased{$}" a2c2 with sum(PO.NetAmount)
与 Envision 中的任何数值变量一样,也可以使用数值标量变量执行任意计算。举例来说,在定义 totalPurchased 和 totalSold 后,可以在 Envision 脚本的末尾对以下计算相加(尽管从商业角度来说可能意义不大):
mySum := (totalSold - totalPurchased) / 2 show table "My Sum" with mySum
多值聚合
Envision 也支持执行多值聚合,通常是聚合给定表的数据并将结果投射到另一个表的多个行。因此,聚合是对来自于不同表的数据进行组合的一种最常用的方法。具体来说,提取历史表便是一种常见的情形,即对于已经使用Date 列进行了索引的表,将该表聚合成一个与 Items 表进行了对准的向量。上面的第一段脚本通过一个显示畅销产品的表诠释了这种模式,即项目按照其相应的销售量排序,最高值排在最上方。为了清楚起见,我们将脚本的相关行复制到下面。
VolumeSold = sum(Orders.NetAmount)
UnitSold = median(Orders.Quantity)
show table "Top sellers" a3f4 tomato with
Name
VolumeSold as "Sold{$}"
UnitSold as "Median"
order by VolumeSold desc
第 1 行和第 2 行执行了聚合,其方式与上文所述的标量聚合极其相似。但是,执行赋值使用的是等号 =,而未采用标量赋值所使用的 := 运算符。由于 VolumeSold 和 UnitSold 皆为 Items 表中的向量,因此,这些变量类似于 Excel 中的列,每个项目包含一个值。在 Envision 中,
sum 和 median 是一种被称为“聚合器”的特殊函数。Envision 中拥有其他许多聚合器,例如 avg、min、max、first、last 等等。为了简明起见,本页面不会一一介绍 Envision 中的所有聚合器;但如果您想了解更多信息,可以查看 ENVISION 中的聚合器列表。这两项聚合的结果显示在通过第 3 行至第 7 行定义的表中。
VolumeSold 和 UnitSold 这两个向量作为参数列出在关键字 with 后面,其值显示在表中。最后来看第 7 行,order by 语句指示该表应从具有最高 VolumeSold 值的项目开始排序。熟悉 SQL 中
GROUP BY 语法的读者可能会好奇 Envision 在第 1 行计算 sum 时是如何知道应使用哪个组的。在默认情况下,Envision 使用列执行分组,列在赋值右边相当于“键”的作用。如果变量属于 Items 表(即表名为隐式),则作为(主)键的列将作为 Id 列。这说明了为什么使用 = 符号可以获得根据项目执行的聚合。使用 by 显式聚合组
到目前为止,我们执行的聚合采用 Envision 的隐式聚合模式。但是,使用可选关键字 by 可以修改所有聚合器的行为,该关键字用于显式指定适用的组。我们来了解一下 by 关键字的使用方法:
VolumeSold = sum(Orders.NetAmount) SameVolumeSold = sum(Orders.NetAmount) by Id // Same!第 2 行被赋给名称为
SameVolumeSold 的第二个向量,但该向量的值与第 1 行的一个向量 VolumeSold 完全相同。实际上,在第 1 行也隐式使用了选项 by Id。从直观上来说,在使用了 by Id 选项时,相当于先是根据分组目标创建组,其次是相当于针对每个组单独计算聚合器。
by 选项为构建十分复杂的聚合提供了可能,从本页顶部的脚本可以说明这一点。我们来回顾一下通过 by 选项执行聚合的这两行脚本。
avgRet := avg(distinct(Orders.Date) by Orders.Client) avgQty := avg(sum(Orders.Quantity) by [Orders.Client, Orders.Date])聚合器
distinct 用于对每组中观察到的不同值进行计数。在第 1 行,Orders 表的行数先根据其相应的 Client 值分组;然后对每个客户的不同订购日期进行计数。从直观上说,这种聚合可以解读为对返回每个客户的次数计数。然后,该结果使用 avg 聚合器(该聚合器包含内部 distinct 聚合)重新聚合为单一标量值。标量
avgQty 可以解读为每个篮子采购的件数。计算是从 sum() by 语句开始,但在 by 选项后,不是一个变量,而是两个用逗号分隔且在括号中列出的变量:[Orders.Client, Orders.Date]。这种语法应理解为为每对 Client 和 Date 创建一个组。从商业的角度说,同一天采购的所有件数应视为同一个篮子,这一点对于大部分情形都很合理。最后是对 avg 进行外部调用,生成了针对所有对计算的所有 sum 聚合的最终平均值。一般而言,
by 选项支持任意个遵循语法 [arg1, arg2, …, argN]}} 的变量。但在实际中,很少遇到需要同时对 4 个以上变量分组的情形。此外,参数顺序不影响用于计算聚合的组。使用 group by 在表中显式聚合
有时通过聚合可以生成新表,相比非聚合的原始表,新表在仪表板中使用更贴切。基于此,Envision 还支持直接从磁贴声明语句聚合数据。该种 Envision 功能可视化的最直接的途径就是聚合要显示在表中的数据。而这正是本页顶部脚本所实现的功能。我们再来看一下复制到下面的相关代码行。
Orders.Brand = Brand
show table "Top Suppliers" a6f7 tomato with
Supplier
distinct(Category) as "Categories"
sum(Orders.NetAmount) as "Sold{$}"
mode(Orders.Brand) if (Orders.Brand != "Fellowes") as "Most frequent brand sold"
group by Supplier
order by sum(Orders.NetAmount) desc
show table 语句从第 2 行延展至第 8 行,具体地说,聚合是在第 7 行用 group by 语句指定的,该语句的语义与上文所介绍的 by 选项完全相同。关于这一点,您可能会纳闷,如果语义相同,那为什么 Envision 不使用关键字 by 而要使用 group by。第 6 行的 if 为聚合器过滤器,下一节会进行介绍。答案很简单:在给定磁贴的
with 后面所使用的表达式列表中,可以使用 by 选项(但此处不会对此情形加以说明)。因此 group by 可对作为表达式一部分的 by 语句,以及作为一个整体应用于磁贴的 group by 语句加以区分。换言之,group by 适用于 with 关键字后面列出的所有表达式,而 by 语句只能产生局部影响。 在使用
group by 时,在 with 关键字后面传递给磁贴的所有表达式应具备聚合能力。例如,下面的第 1 行脚本是错误的,因为在指定了 group by Supplier 时 Name 不提供聚合模式。
show table "WRONG!" with Name group by Supplier但是,如果我们通过引入聚合器对这段脚本进行修改,例如引入
distinct,则 Envision 脚本就会变得有效。
show table "CORRECT!" with distinct(Name) group by Supplier这条规则唯一的例外就是聚合目标本身。在这一节开头的脚本中,第 7 行为
group by Supplier 语句。在第 3 行,虽然在没有提供任何聚合器的情况下列出了变量 Supplier,但这段脚本仍然有效,这正是因为是根据 Supplier 变量进行分组的。暴露聚合器的需求同样适用于第 8 行的
order by 语句。实际上,该表先是按供应商聚合,然后根据 Id 列排序 – 除非指定了其他排序。因此,Envision 需要每组计算一个值,以便对所有这些组进行排序。这正是通过语句 group by sum(Orders.NetAmount) 实现的。我们使用
table 磁贴说明了 group by ,但这种语法并非特定于 table 磁贴,大多数其他磁贴同样可以使用这种模式。例如,使用通过 Brand 聚合的 barchart 磁贴,可以对本页最上方列出的脚本进行扩展:
show barchart "Sales by brand" with sum(Orders.NetAmount) group by Brand
group by 还支持多组,即使用与上文所述的一个 by 选项完全相同的语法,来按多个向量或多个表达式分组。聚合过滤器
Envision 聚合器还通过if 关键字支持过滤器。上面这段脚本在第 6 行使用了一个这样的过滤器:
Orders.Brand = Brand
show table "Top Suppliers" a6f7 tomato with
Supplier
distinct(Category) as "Categories"
sum(Orders.NetAmount) as "Sold{$}"
mode(Orders.Brand) if (Orders.Brand != "Fellowes") as "Most frequent brand sold"
group by Supplier
order by sum(Orders.NetAmount) desc
其中,品牌 Fellowes 通过 if 过滤器显式排除在报告范围外。过滤器在磁贴语句中非常有用,因为它们具有单独过滤每列的能力。相比之下,磁贴语句外部的 where 过滤器则可以过滤掉 Orders 表中对所有列不重要的选定行。过滤器也可以进行内联使用:
TwoAndMore = sum(Orders.1) if (Orders.Quantity >= 2)