Par Joannes Vermorel, novembre 2020Une prévision est dite probabiliste, plutôt que déterministe, si elle contient un ensemble de probabilités associées à tous les résultats futurs possibles, au lieu de désigner un résultat particulier comme "la" prévision. Les prévisions probabilistes sont importantes lorsque l'incertitude est irréductible, ce qui est presque toujours le cas lorsqu'il s'agit de systèmes complexes. Pour les supply chains, les prévisions probabilistes sont essentielles pour prendre des décisions robustes face à des conditions futures incertaines. En particulier, la demande et le délai de livraison, deux aspects clés de l'analyse de la supply chain, sont tous deux mieux traités par des prévisions probabilistes. La perspective probabiliste se prête naturellement à la hiérarchisation économique des décisions en fonction de leur rendement attendu mais incertain. Une grande variété de modèles statistiques fournit des prévisions probabilistes. Certaines sont structurellement proches de leurs homologues déterministes, tandis que d'autres sont très différentes. L'évaluation de la précision d'une prévision probabiliste nécessite des mesures spécifiques, qui diffèrent de leurs homologues déterministes. L'exploitation des prévisions probabilistes nécessite un outillage spécialisé qui diverge de ses homologues déterministes.
Prévisions déterministes vs. prévisions probabilistes
L'optimisation des supply chains repose sur la bonne anticipation des événements futurs. Numériquement, ces événements sont anticipés par des
prévisions, qui englobent une grande variété de méthodes numériques utilisées pour quantifier ces événements futurs. Depuis les années 1970, la forme de prévision la plus utilisée est la prévision déterministe de série chronologique : une quantité mesurée dans le temps - par exemple la demande en unités d'un produit - est projetée dans le futur. La section passée de la série chronologique constitue les données historiques, la section future de la série chronologique constitue la prévision.
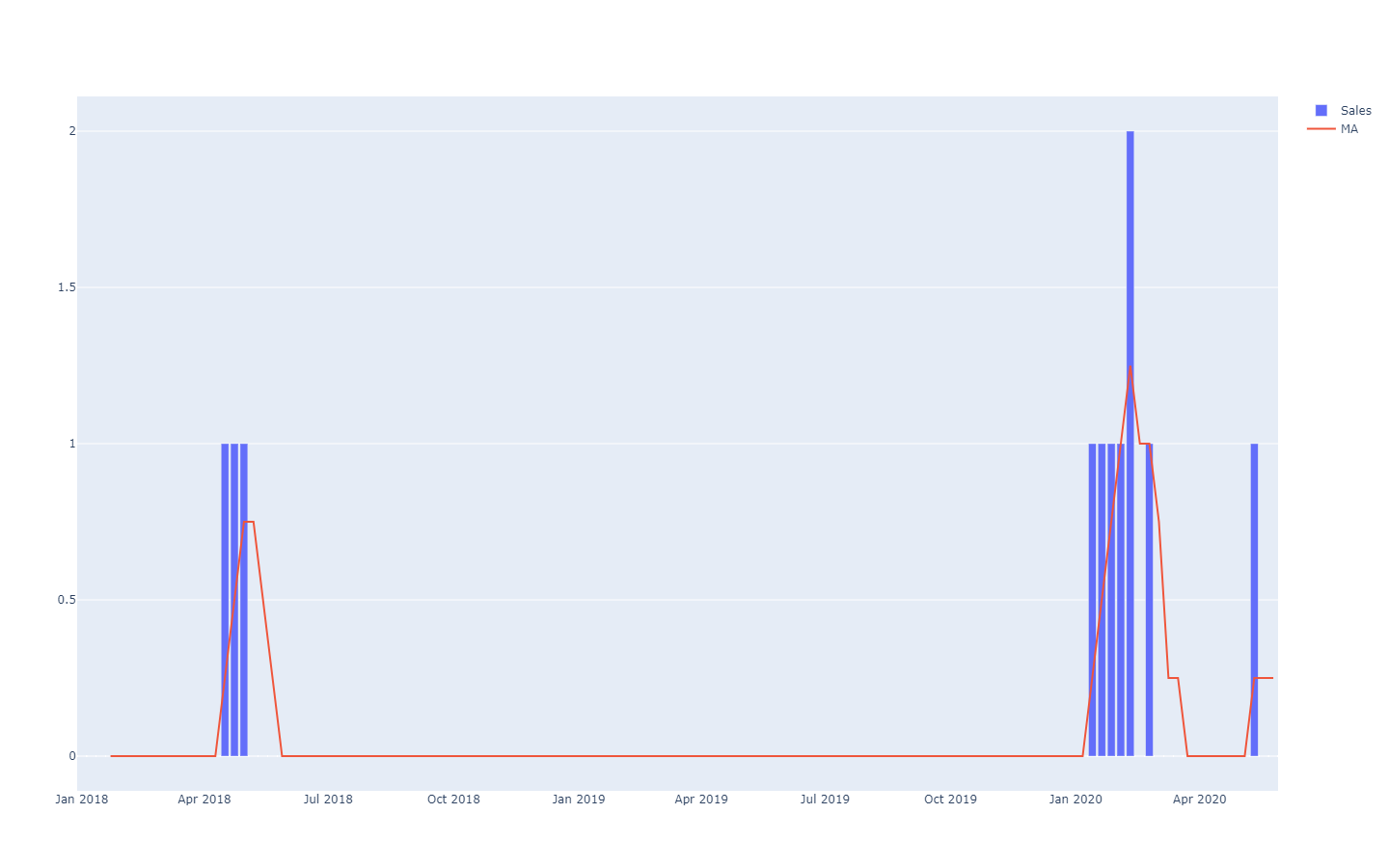
MA est l'abréviation de "moving average" (moyenne mobile), elle n'est pas très régulière dans les séries chronologiques éparses.Ces prévisions de séries chronologiques sont dites "déterministes" parce que pour chaque moment dans le futur, la prévision fournit une valeur unique qui est censée correspondre aussi étroitement que possible au résultat futur . En effet, bien que la prévision soit à valeur unique, il est généralement admis qu'elle a peu de chances d'être parfaitement correcte. Les résultats futurs divergeront de la prévision. L'adhésion de la prévision déterministe à ses résultats futurs est évaluée quantitativement par des mesures de précision, comme l'erreur quadratique moyenne (EQM) par exemple.
Les prévisions probabilistes adoptent une perspective différente sur l'anticipation des résultats futurs. Au lieu de produire une valeur comme étant le "meilleur" résultat, la prévision probabiliste consiste à attribuer une "probabilité" à chaque résultat possible. En d'autres termes, tous les événements futurs restent possibles, ils n'ont simplement pas la même probabilité. Vous trouverez ci-dessous la représentation d'une prévision probabiliste de séries chronologiques présentant l'"effet fusil", qui est généralement observé dans la plupart des situations du monde réel. Nous reviendrons plus en détail sur cette représentation par la suite.
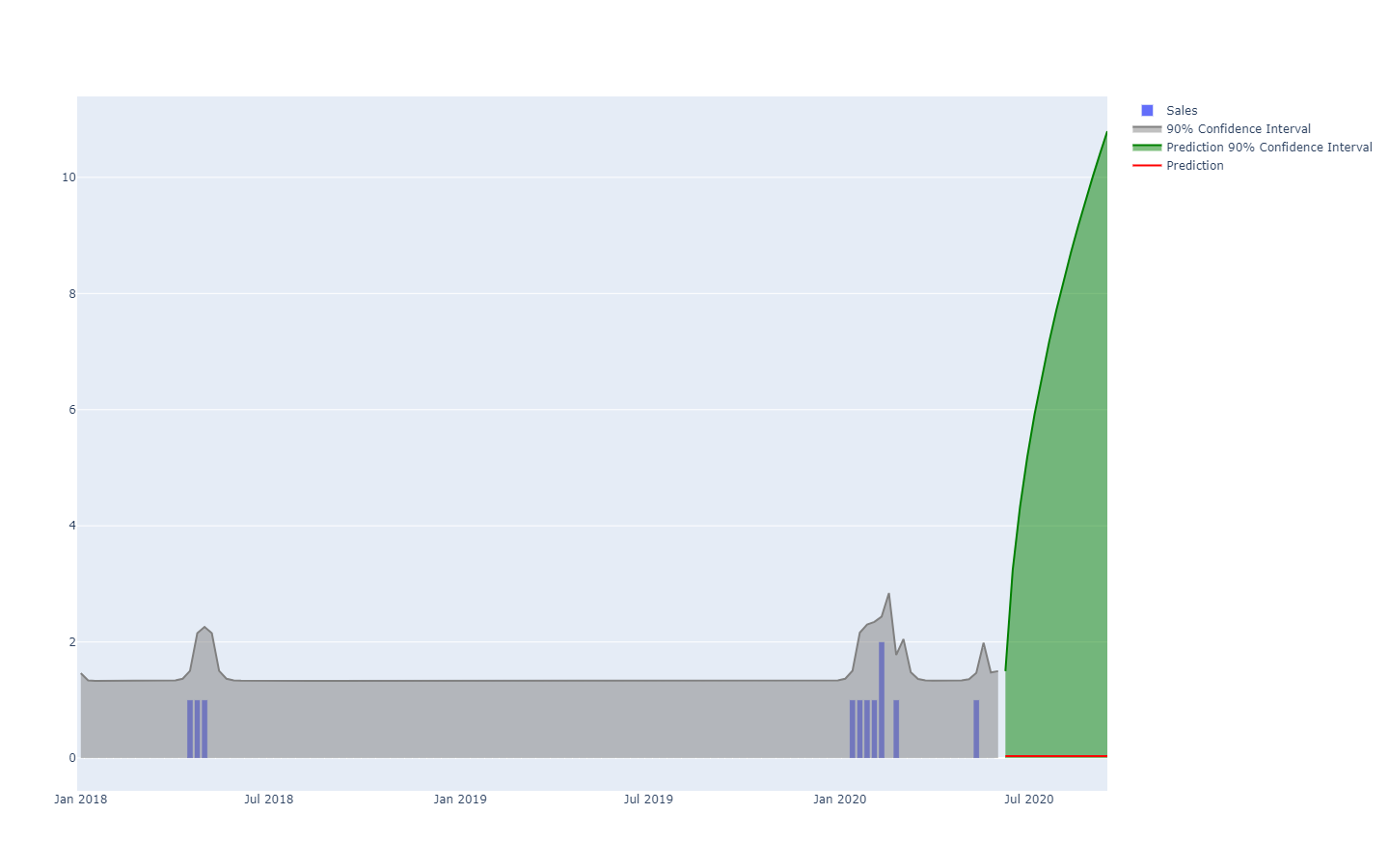
Une prévision probabiliste illustrant une situation à forte incertitude.La série chronologique, une quantité mesurée dans le temps, est probablement le modèle de données le plus connu et le plus utilisé. Ce modèle de données peut être prévu à la fois par des moyens déterministes ou probabilistes. Cependant, il existe de nombreux autres modèles de données, généralement plus riches, qui se prêtent également à des prévisions des deux types. Par exemple, une entreprise qui répare des moteurs à réaction peut souhaiter anticiper la liste exacte des pièces de rechange qui seront nécessaires pour une opération de maintenance à venir. Cette anticipation peut prendre la forme d'une prévision, mais il ne s'agira pas d'une prévision de série chronologique. La prévision déterministe associée à cette opération est la liste exacte des pièces et leurs quantités. A l'inverse, la prévision probabiliste est la probabilité pour chaque combinaison de pièces (quantités incluses) que cette combinaison spécifique soit celle qui sera nécessaire pour effectuer les réparations.
En outre, si le terme "prévision" met l'accent sur une anticipation quelconque, l'idée peut être généralisée à tout type de déclaration "déduite statistiquement" concernant un système, y compris pour ses propriétés passées (mais inconnues). La pratique de la prévision statistique est apparue au cours du XXe siècle, avant l'avènement de la perspective plus moderne de l'"apprentissage statistique", qui englobe toutes les extrapolations fondées sur des données qui peuvent être effectuées, indépendamment de toute dimension temporelle. Par souci de clarté, nous continuerons à utiliser le terme "prévision" dans ce qui suit, même si cet aspect temporel assimile toujours le passé au connu et le futur à l'inconnu. Par exemple, une entreprise peut souhaiter estimer les ventes qui auraient eu lieu pour un produit dans un magasin si le produit n'avait pas été en rupture de stock ce jour-là. Cette estimation est utile pour quantifier l'ampleur du problème en termes de qualité de service. Cependant, l'événement étant passé, le chiffre de vente "réel" ne sera jamais observé. Néanmoins, en supposant qu'il n'a pas encore été simplement observé, l'estimation statistique de la demande passée est un problème très proche de l'estimation de la demande future.
Les prévisions probabilistes sont plus riches - en termes d'informations - que leurs homologues déterministes. Alors que la prévision déterministe fournit une "meilleure estimation" du résultat futur, elle ne dit rien sur les alternatives. En fait, il est toujours possible de convertir une prévision probabiliste en sa variante déterministe en prenant la moyenne, la médiane, le mode, ... de la distribution de probabilité. Pourtant, l'inverse n'est pas vrai : il n'est pas possible de récupérer une prévision probabiliste à partir d'une prévision déterministe.
Pourtant, bien que les prévisions probabilistes soient statistiquement supérieures aux prévisions déterministes, elles restent peu utilisées dans la supply chain. Cependant, leur popularité n'a cessé de croître au cours de la dernière décennie. Historiquement, les prévisions probabilistes sont apparues plus tard, car elles nécessitent beaucoup plus de ressources informatiques. L'exploitation des prévisions probabilistes au service de la supply chain nécessite également des outils logiciels spécialisés, qui sont souvent indisponibles.
Cas d'utilisation dans la supply chain
L'optimisation d'une supply chain consiste à prendre la "bonne" décision - à un instant T- qui permettra d'aborder avec le plus de profit une situation future qui n'est qu'imparfaitement estimée. Toutefois, l'incertitude associée aux événements futurs est en grande partie irréductible. Ainsi, l'entreprise a besoin que sa décision soit robuste si l'anticipation de l'événement futur - c'est-à-dire la prévision - est imparfaite. C'est ce qui a été fait de manière "minimale" depuis le milieu du 20e siècle, par le biais de l'analyse du stock de sécurité. Cependant, comme nous le verrons plus loin, outre l'intérêt historique, il n'y a plus aucune raison de privilégier les stocks de sécurité par rapport aux méthodes numériques probabilistes "natives".
La démarche de prévision probabiliste adopte une position radicale vis-à-vis de l'incertitude : cette approche tente de "quantifier" l'incertitude autant que possible. Dans la supply chain, les coûts ont tendance à se concentrer sur les extrêmes statistiques : c'est la demande étonnamment élevée qui crée la rupture de stock, c'est la demande étonnamment faible qui crée la radiation de l'inventaire. Entre les deux, les stocks tournent très bien. Les prévisions probabilistes sont - en gros - une tentative de gérer ces situations à faible fréquence et à coût élevé qui sont omniprésentes dans les supply chains modernes. Les prévisions probabilistes peuvent et doivent être considérées comme un ingrédient essentiel de toute pratique de gestion des risques au sein de la supply chain.
De nombreux aspects des supply chains sont particulièrement propices à la prévision probabiliste, tels que :
- La demande : les vêtements, les accessoires, les pièces détachées, ainsi que de nombreux autres types de produits, sont généralement associés à une demande inconstante et/ou intermittente. Les lancements de produits peuvent être réussis ou manqués. Les promotions des concurrents peuvent temporairement et irrégulièrement cannibaliser de grandes parties des parts de marché.
- Les délais de production: les importations outre-mer peuvent entraîner toute une série de retards à tous les stades de la chaîne (production, transport, douane, réception, etc.). Même les fournisseurs locaux peuvent occasionnellement avoir de longs délais de livraison s'ils sont confrontés à un problème de rupture de stock. Les délais ont tendance à avoir lieu dans des distributions à "queue de poisson".
- Le rendement (produits frais) : la quantité et la qualité de la production de nombreux produits frais dépendent de conditions, telles que la météo, qui échappent au contrôle de l'entreprise. La prévision probabiliste quantifie ces facteurs pour l'ensemble de la saison et offre la possibilité de dépasser les prévisions météorologiques classiques.
- Les retours (e-commerce) : lorsqu'un client commande le même produit dans trois tailles différentes, il y a de fortes chances que deux de ces tailles soient retournées. Plus généralement, si de fortes différences régionales existent, les clients ont tendance à tirer parti des politiques de retour favorables, lorsqu'elles existent. La probabilité de retours pour chaque commande doit être évaluée.
- Les rebuts (aviation) : il s'agit des pièces d'aéronefs réparables - fréquemment appelées pièces rotatives - qui ne peuvent parfois pas être réparées. Dans ce cas, la pièce est mise au rebut, car elle est impropre à être montée à nouveau sur un avion. Bien qu'il ne soit généralement pas possible de savoir à l'avance si une pièce survivra ou non à sa réparation, il convient d'estimer la probabilité que la pièce soit mise au rebut.
- Les stocks (commerce de détail B2C) : les clients peuvent déplacer, endommager ou même voler des marchandises dans un commerce au détail. Ainsi, le niveau de stock électronique n'est qu'une approximation de la disponibilité réelle en rayon telle que perçue par les clients. Le niveau de stock, tel que perçu par les clients, doit être estimé par une prévision probabiliste.
- ...
Cette courte liste montre que les points pouvant faire l'objet d'une prévision probabiliste dépassent largement les seuls points traditionnels de "prévision de la demande". L'optimisation bien conçue d'une chaîne d'approvisionnement nécessite de prendre en compte toutes les sources d'incertitude pertinentes. Bien qu'il soit parfois possible de réduire l'incertitude - comme le souligne la production allégée - il y a généralement des compromis économiques à faire et, par conséquent, une certaine quantité d'incertitude reste irréductible.
Les prévisions, cependant, ne sont que des opinions éclairées sur l'avenir. Si les prévisions probabilistes peuvent être considérées comme des opinions d'une finesse remarquable, elles ne sont pas fondamentalement différentes de leurs homologues déterministes à cet égard. La valeur des prévisions probabilistes, du point de vue de la supply chain, réside dans la manière dont cette structure fine est exploitée pour prendre des décisions plus rentables. En particulier, les prévisions probabilistes ne sont pas censées être plus précises que leurs homologues déterministes si des mesures de précision déterministes sont utilisées pour évaluer la qualité des prévisions.
Une défense de la variabilité
Malgré ce que prônent de nombreuses approches de la supply chain, la variabilité est bien présente et inévitable, d'où la nécessité de disposer de prévisions probabilistes. La première fausse croyance est que la variabilité est nécessairement une mauvaise chose pour une supply chain ; il n'en est rien. La deuxième conception erronée est que la variabilité peut être éliminée par l'ingénierie ; ce n'est pas le cas.
La variabilité a des répercussions positives sur les supply chains dans de nombreuses situations. Par exemple, du côté de la demande, la plupart des secteurs verticaux sont motivés par la nouveauté, tels que la mode, les produits culturels, le grand et petit luxe luxe - tout comme les entreprises "à la mode ou à la traîne" (hit or miss). La plupart des nouveaux produits ne sont pas des réussites (misses), mais ceux qui réussissent (hits) génèrent des retours massifs. Une variabilité accrue est une bonne chose, car elle augmente la probabilité de rendements exceptionnels, tandis que les inconvénients restent limités (dans le pire des cas, l'ensemble du stock est amorti). Le flux incessant de nouveaux produits mis sur le marché assure le renouvellement constant des "succès", tandis que les anciens disparaissent.
Du côté de l'offre, un processus de sourcing qui garantit des offres de prix très variables est supérieur - toutes choses égales par ailleurs - à un processus alternatif qui génère des prix beaucoup plus cohérents (c'est-à-dire moins variables). En effet, l'option la moins chère est sélectionnée tandis que les autres sont écartées. Peu importe que le prix "moyen" de la source d'approvisionnement soit bas, ce qui compte c'est de découvrir des sources à bas prix. Ainsi, un bon processus de sourcing doit être conçu pour augmenter la variabilité, par exemple en mettant l'accent sur l'exploration systématique de nouveaux fournisseurs plutôt que de se limiter aux fournisseurs traditionnels.
Parfois, la variabilité peut être bénéfique de manière plus subtile. Par exemple, si une marque est trop prévisible en ce qui concerne ses opérations promotionnelles, les clients identifient le modèle et commencent à retarder leur achat car ils savent qu'une promotion est à venir et quand elle aura lieu. La variabilité - voire le caractère erratique - des activités promotionnelles peut dans une certaine mesure atténuer ce comportement.
Un autre exemple de ceci est la présence de facteurs de confusion au sein même de la supply chain. Si les nouveaux produits sont toujours lancés avec une campagne de pubs télévisées et diffusées à la radio, il devient statistiquement difficile de distinguer les impacts respectifs de la TV et de la radio. En ajoutant de la variabilité à l'intensité de la campagne en fonction du canal, on peut extraire plus d'informations statistiques de ces opérations, qui peuvent ensuite être transformées en informations permettant une meilleure allocation des ressources marketing.
Naturellement, il ne s'agit pas d'affirmer que toute forme variabilité est nécessairement bonne. La production allégée a raison de souligner que, du côté de la production de la supply chain, la variabilité est généralement préjudiciable, surtout lorsqu'il s'agit de varier les délais. En effet, les processus DEPS (dernier entré, premier sorti ou LIFO en anglais) peuvent se glisser accidentellement, ce qui, à son tour, exacerbe la variabilité des délais. Dans ces situations, la variabilité accidentelle doit être éliminée, souvent par un système plus performant, parfois par de meilleurs équipements ou installations.
La variabilité - même lorsqu'elle est préjudiciable - est souvent irréductible. Comme nous le verrons dans la section suivante, les supply chains obéissent à la loi des petits nombres. Il est illusoire de penser que l'on pourra un jour prédire de manière fiable le taux de remplissage des magasins - d'un point de vue déterministe - alors que les clients ne savent pas toujours eux-mêmes ce qu'ils sont sur le point d'acheter. Plus généralement, la réduction de la variabilité a toujours un coût (et la réduire encore plus), tandis que la réduction marginale de la variabilité n'apporte que des rendements décroissants. Ainsi, même lorsque la variabilité peut être réduite, à toutes fins utiles, elle ne peut que très rarement être entièrement éliminée en raison des implications économiques.
La loi des petits nombres
La loi des petits nombres de la supply chain peut être énoncée comme suit :
les petits nombres prédominent tout au long de la chaîne. Cette loi observable résulte des économies d'échelle et de quelques autres forces qui déterminent la plupart des aspects structurels des supply chains :
- un fournisseur qui livre des dizaines de milliers d'unités de matériaux par jour est susceptible d'avoir des quantités minimales de commande (QMC) ou des prix cassés qui empêchent de passer des commandes trop fréquemment. Le nombre de bons de commande transmis à un fournisseur un jour donné dépasse rarement un nombre à un chiffre.
- une usine qui produit des dizaines de milliers d'unités par jour est susceptible de fonctionner par lots importants de milliers d'unités. La résultat de la production est susceptible d'être emballée par palettes entières. Le nombre de lots au cours d'une journée donnée est tout au plus un petit nombre à deux chiffres.
- un entrepôt qui reçoit des dizaines de milliers d'unités par jour est susceptible d'être livré par camions, chaque camion déchargeant la totalité de sa cargaison dans l'entrepôt. Le nombre de livraisons par camion un jour donné dépasse rarement un nombre à deux chiffres, même pour les très grands entrepôts.
- un magasin de détail qui peut stocker des dizaines de milliers d'unités est susceptible de répartir son assortiment en milliers de références de produits distinctes. Le nombre d'unités détenues en stock pour chaque produit dépasse très rarement un nombre à un chiffre.
- ...
Naturellement, il est toujours possible de gonfler les chiffres en changeant l'unité de mesure, Par exemple, si au lieu de compter le nombre de palettes, on mesure le poids des palettes en grammes, ou leur valeur monétaire en centimes d'USD, les grands nombres apparaissent. Cependant, la loi des petits nombres doit être appréhendée avec la notion de comptage des choses dans une perspective de supply chain sensée. Si, en théorie, ce principe peut sembler assez subjectif, ce n'est pas le cas dans la pratique, en raison des aspects pratiques évidents des supply chain modernes qui comptent en paquets, boîtes, palettes, conteneurs, camions...
Cette loi est d'une grande importance dans une perspective de prévision probabiliste. Premièrement, elle souligne que les prévisions "discrètes" dominent dans les situations de la supply chain, c'est-à-dire que le résultat à anticiper (ou à décider) est un "nombre entier", par opposition à un nombre fractionnaire. Les prévisions probabilistes sont particulièrement adaptées aux situations "discrètes", car une probabilité peut être estimée pour chaque résultat discret. En revanche, les prévisions déterministes ont du mal avec les résultats discrets. Par exemple, qu'est-ce que cela signifie que les ventes quotidiennes estimées d'un produit sont de 1,3 unités ? Les unités ne sont pas vendues de manière fractionnée. Alors que des interprétations "discrètes" plus sensées peuvent être déduites de cet énoncé, sa contrepartie probabiliste (par exemple, 27% de chance de 0 unité de demande, 35% de chance de 1 unité de demande, 23% de chance de 2 unités de demande, etc.) est beaucoup plus directe, car elle prend en compte la nature discrète du phénomène concerné.
Deuxièmement, si les prévisions probabilistes peuvent sembler radicalement plus difficiles en termes de ressources informatiques brutes, ce n'est pas vraiment le cas en pratique, précisément en raison de la loi des petits nombres. En effet, pour en revenir aux ventes quotidiennes de produits évoquées plus haut, il est inutile d'évaluer numériquement les probabilités que la demande dépasse 100 un jour donné. Ces probabilités peuvent être arrondies à zéro - ou à une valeur arbitraire extrêmement faible. L'impact sur la précision numérique du modèle de la supply chain reste négligeable. En règle générale, il est raisonnable de considérer que les prévisions probabilistes nécessitent environ trois fois plus de ressources informatiques supplémentaires par rapport à leurs homologues déterministes. Cependant, malgré cette surcharge, les avantages en termes de performance de la supply chain dépassent largement le coût des ressources informatiques.
Indicateurs de précision pour les prévisions probabilistes
Quoi qu'il arrive, une prévision probabiliste raisonnablement bien conçue indique qu'il y avait effectivement une probabilité non nulle que ce résultat se produise. Ceci est curieux car, à première vue, on pourrait croire que les prévisions probabilistes sont en quelque sorte détachées de la réalité, tout comme une diseuse de bonne aventure qui fait des déclarations prophétiques très ambiguës dont on ne pourra jamais prouver qu'elles sont fausses, car la diseuse de bonne aventure peut toujours conjurer une explication ultérieure sur la bonne façon d'interpréter les prophéties a posteriori. En réalité, il existe de multiples façons d'évaluer quantitativement la qualité d'une prévision probabiliste. Certains de ces moyens sont des " indicateurs " similaires dans l'esprit aux indicateurs utilisés pour évaluer la précision des prévisions déterministes. D'autres moyens divergent de manière plus radicale et plus profonde par rapport à la perspective déterministe.
Passons rapidement en revue quatre approches distinctes pour évaluer la précision d'une prévision probabiliste :
- la fonction de perte pinball
- l'indice continu de probabilité (CRPS)
- la vraisemblance bayésienne
- la perspective générative contradictoire
La
fonction de perte pinball fournit une indicateur de précision pour une estimation quantile à extraire d'une prévision probabiliste. Par exemple, si l'on souhaite évaluer la quantité de stock qui a 98% de chance d'être supérieure ou égale à la demande des clients dans un magasin pour un produit donné, cette quantité peut être obtenue directement à partir des prévisions probabilistes en additionnant simplement les probabilités à partir de 0 unité de demande, 1 unité de demande, ... jusqu'à ce que la probabilité dépasse de peu 98%. La fonction de perte pinball fournit une mesure directe de la qualité de cette estimation partiale de la demande future. Elle peut être considérée comme un outil permettant d'évaluer la qualité de la fonction de densité cumulative de la prévision probabiliste sous tous ses angles.
L'
indice continu de probabilité (CRPS) fournit une évaluation, qui peut être interprétée comme la "quantité de déplacement" de la masse de probabilités qu'il faut pour déplacer toute la masse de probabilités vers le résultat observé. Il s'agit de la généralisation la plus directe de l'erreur absolue moyenne (MAE) vers une perspective probabiliste. La valeur CRPS est homogène avec l'unité de mesure du résultat lui-même. Cette perspective peut être généralisée à des espaces métriques arbitraires, au lieu de se limiter à des situations unidimensionnelles, grâce à ce que l'on appelle la "théorie du transport" et la distance de Monge-Kantorovich (qui dépasse le cadre du présent document).
La vraisemblance et sa
cousine l'entropie croisée adoptent la perspective bayésienne du
moindre degré de surprise : plus la probabilité des résultats observés est élevée, mieux c'est. Par exemple, nous avons deux modèles probabilistes, A et B : le modèle A stipule que la probabilité d'observer 0 unité de demande est de 50% pour un jour donné ; le modèle B stipule que la probabilité d'observer 0 unité de demande est de 1% pour un jour donné. Nous observons la demande sur 3 jours et obtenons les observations suivantes : 0, 0, 1 : 0, 0, 1. Le modèle A avait environ 10% de chances de générer ces observations, alors que pour le modèle B, la probabilité n'était que de 0,01%. Ainsi, le modèle B a beaucoup moins de chances d'être le bon modèle que le modèle A. La vraisemblance diffère de la perspective déterministe qui consiste à disposer d'un critère "absolu" valable pour évaluer les modèles. Au lieu de cela, elle fournit un mécanisme pour "comparer" les modèles, mais numériquement, le mécanisme ne peut pas vraiment être utilisé pour autre chose que la comparaison des modèles.
La perspective générative contradictoire est la perspective la plus moderne sur la question (Ian Goodfellow et al., 2014). En substance, cette perspective stipule que le " meilleur " modèle probabiliste est celui qui peut être utilisé pour générer des résultats - à la manière monte-carlo - qu'il est impossible de distinguer des résultats réels. Par exemple, si nous considérons la liste historique des transactions dans un hypermarché local, nous pourrions tronquer cette historique à un moment arbitraire du passé et utiliser le modèle probabiliste pour générer des transactions fausses mais réalistes par la suite. Le modèle serait considéré comme "parfait" s'il était impossible, par une analyse statistique, de retrouver le moment où l'ensemble de données passe des "vraies" aux "fausses" données. L'intérêt de l'approche générative contradictoire est d'"apprendre" les indicateurs qui exacerbent le défaut de tout modèle probabiliste. Au lieu de se concentrer sur une donnée particulière, cette perspective exploite de manière récursive les techniques d'apprentissage automatique pour "apprendre" les paramètres eux-mêmes.
La recherche de meilleurs moyens pour évaluer la qualité des prévisions probabilistes reste un domaine de recherche actif. Il n'y a pas de délimitation claire entre les deux questions "Comment produire une meilleure prévision ?" et "Comment dire si une prévision est meilleure ?". Des travaux récents ont considérablement estompé la frontière entre les deux, et il est probable que les prochaines percées impliqueront de nouveaux changements dans la manière même de considérer les prévisions probabilistes.
Probabilités infimes et log-vraisemblance
De très faibles probabilités apparaissent naturellement lorsque l'on examine une situation multidimensionnelle à travers le prisme des prévisions probabilistes. Ces faibles probabilités sont gênantes car les ordinateurs ne peuvent pas traiter des nombres infiniment précis. Les valeurs de probabilité brutes sont souvent "infimes" dans le sens où elles sont arrondies à zéro en raison des limites de la précision numérique. La solution à ce problème ne consiste pas à faire évoluer le logiciel vers des calculs de précision arbitraire - ce qui est très inefficace en termes de ressources informatiques - mais à utiliser le "log-trick", qui transforme les multiplications en additions. Cette astuce est utilisée - d'une manière ou d'une autre - par pratiquement tous les logiciels traitant des prévisions probabilistes.
Supposons que l'on dispose de variables aléatoires $X_1$, $X_2$, ..., $X_n$ représentant la demande du jour pour l'ensemble des $n$ produits distincts servis dans un magasin donné. Soit $\hat{x}_1$, $\hat{x}_2$, ..., $\hat{x}_n$ correspondant à la demande empirique observée en fin de journée pour chaque produit. Pour le premier produit - régi par $X_1$ - la probabilité d'observer $\hat{x}_1$ s'écrit $P(X_1 = \hat{x}_1)$. Supposons maintenant, de manière quelque peu exagérée, mais par souci de clarté, que tous les produits sont strictement indépendants du point de vue de la demande. La probabilité pour l'événement conjoint d'observer $\hat{x}_1$, $\hat{x}_2$, ..., $\hat{x}_n$ est :
$$P(X_1 = \hat{x}_1 \dots X_n = \hat{x}_n) = \prod_{k=1}^n P(X_k = \hat{x}_k)$$
Si $P(X_k = \hat{x}_k) \approx \frac{1}{2}$ (vague approximation) et $n = 10000$ alors la probabilité conjointe ci-dessus est de l'ordre de $\frac{1}{2^{10000}} \approx 5 * 10^{-3011}$, ce qui est une toute petite valeur. Cette valeur est une situation de soupassement, c'est à dire qu'elle est inférieure au plus petit nombre représentable, même en considérant les nombres à virgule flottante de 64 bits qui sont généralement utilisés pour le calcul scientifique.
Le "log-trick" consiste à travailler avec le logarithme de l'expression, c'est-à-dire :
$$\ln P(X_1 = \hat{x}_1 \dots X_n = \hat{x}_n) = \sum_{k=1}^n \ln P(X_k = \hat{x}_k)$$
Le logarithme transforme la série de multiplications en une série d'additions, ce qui s'avère beaucoup plus stable numériquement qu'une série de multiplications.
L'utilisation du "log-trick" est fréquente dès lors qu'il s'agit de prévisions probabilistes. La
log-vraisemblance est littéralement le logarithme de la vraisemblance (introduite précédemment), précisément parce que la vraisemblance brute serait généralement non représentable numériquement compte tenu des types courants de nombres à virgule flottante.
Formes algorithmiques des prévisions probabilistes
La question de la génération par ordinateur de prévisions probabilistes est presque aussi vaste que le domaine du machine learning lui-même. Les délimitations entre les deux domaines, si elles existent, sont principalement une question de choix subjectifs. Néanmoins, cette section présente une liste plutôt non exhaustive d'approches algorithmiques notables qui peuvent être utilisées pour obtenir des prévisions probabilistes.
Au début du 20e siècle, ou possiblement dès la fin du 19e siècle, est apparue l'idée des
stocks de sécurité, dans laquelle l'incertitude de la demande est modélisée par une distribution normale. Comme des tables de distribution normale pré-calculées avaient déjà été établies pour d'autres sciences, notamment en physique, l'application du stock de sécurité ne nécessitait que la multiplication d'un niveau de demande par un coefficient de "stock de sécurité" tiré d'une table préexistante. À titre anecdotique, de nombreux manuels sur la supply chain rédigés jusque dans les années 1990 contenaient encore des tableaux de la distribution normale dans leurs annexes. Malheureusement, le principal inconvénient de cette approche est que les distributions " normales " ne sont pas une proposition raisonnable pour les supply chain. Tout d'abord, en ce qui concerne les supply chains, on peut supposer que " rien " n'est jamais distribué " normalement ". Deuxièmement, la distribution normale est une distribution continue, ce qui est en contradiction avec la nature discrète des événements de la supply chain (voir "Loi des petits nombres" ci-dessus). Ainsi, si techniquement les "stocks de sécurité" ont une composante probabiliste, la méthodologie sous-jacente et les formules numériques sont résolument orientées vers la perspective déterministe. Cette approche est toutefois mentionnée ici par souci de clarté.
Au début des années 2000, les méthodes d'apprentissage ensemblistes- dont les représentants les plus connus sont probablement les forêts d'arbres décisionnels et les Gradient Boosting Trees - sont relativement simples à étendre à la perspective probabiliste malgré leurs origines déterministes. L'idée principale de l'apprentissage ensembliste est de combiner de nombreux indicateurs déterministes faibles, tels que les arbres de décision, en un indicateur déterministe supérieur. Cependant, il est possible d'ajuster le processus de combinaison pour obtenir des probabilités plutôt qu'un simple agrégat, transformant ainsi la méthode d'apprentissage ensembliste en une méthode de prévision probabiliste. Ces méthodes sont non paramétriques et capables de s'adapter à des distributions à queue large et/ou multimodales, telles qu'on les rencontre couramment dans la supply chain. Ces méthodes ont tendance à présenter deux inconvénients qu'il convient de noter. Tout d'abord, par sa construction même, la fonction de densité de probabilité produite par cette classe de modèles a tendance à inclure beaucoup de zéros, ce qui empêche toute tentative d'exploiter l'indicateur de la log-vraisemblance. Plus généralement, ces modèles ne correspondent pas vraiment à la perspective bayésienne, car des observations plus récentes sont régulièrement déclarées "impossibles" (c'est-à-dire de probabilité nulle) par le modèle. Ce problème peut toutefois être résolu par des méthodes de régularisation[1]. Deuxièmement, les modèles ont tendance à être aussi grands qu'une fraction appréciable de l'ensemble de données d'entrée, et l'opération "prédire" a tendance à être presque aussi coûteuse en calcul que l'opération "apprendre".
Les méthodes hyperparamétriques connues sous le nom de "deep learning", qui ont explosé dans les années 2010, étaient, presque "accidentellement", probabilistes. En effet, alors que la grande majorité des tâches dans lesquelles le deep learning se distingue vraiment (par exemple, la classification d'images) se concentrent uniquement sur des prévisions déterministes, il s'avère que l'indicateur de l'entropie croisée - une variante de la log-vraisemblance dont nous avons parlé plus haut - présente des gradients très prononcés qui sont souvent bien adaptés à la descente de gradient stochastique (SGD), qui se trouve au cœur des méthodes de deep learning. Par conséquent, les modèles d'apprentissage profond s'avèrent être conçus comme probabilistes, non pas parce que les probabilités étaient pertinentes, mais parce que la descente du gradient converge plus rapidement lorsque la fonction de perte reflète une prévision probabiliste. Ainsi, en ce qui concerne le deep learning, la supply chain se distingue par son intérêt pour le résultat probabiliste réel du modèle de deep learning, alors que la plupart des autres cas d'utilisation réduisent la distribution de probabilité à sa moyenne, sa médiane ou son mode. Les Mixture Densi Networks sont un type de réseau de deep learning axé sur l'apprentissage de distributions de probabilité complexes. Le résultat lui-même est une distribution paramétrique, potentiellement composée de fonctions gaussiennes. Cependant, contrairement aux "stocks de sécurité", un mélange de plusieurs fonctions gaussiennes peut, en pratique, refléter les comportements type queue de poisson observés dans les supply chains. Alors que les méthodes de deep learning sont souvent considérées comme étant à la pointe de la technologie, il faut noter qu'obtenir une stabilité numérique, en particulier lorsqu'il s'agit de mélanges de densité, reste un peu une "science obscure".
La programmation différentiable est une descendante du deep learning, qui a gagné en popularité à la toute fin des années 2010. Elle partage de nombreux attributs techniques avec le deep learning, mais diffère considérablement de ce dernier dans son objectif. Alors que le deep learning se concentre sur l'apprentissage de fonctions complexes arbitraires (par exemple, jouer au Go) en accumulant un grand nombre de fonctions simples (par exemple, des couches convolutives), la programmation différentiable se concentre sur la structure fine du processus d'apprentissage. La structure la plus fine et la plus expressive, presque littéralement, peut être mise en forme comme un programme impliquant des embranchements, des boucles, des appels de fonctions, etc. La programmation différentiable présente un grand intérêt pour la supply chain, car les problèmes ont tendance à se présenter de manière très structurée, et ces structures sont connues des experts[2]. Par exemple, les ventes d'une chemise donnée peuvent être cannibalisées par une autre chemise d'une couleur différente, mais elles ne seront pas cannibalisées par les ventes d'une chemise trois fois plus grande ou plus petite. De tels prérequis structurels sont essentiels pour obtenir une grande efficacité dans les données. En effet, du point de vue de la supply chain, la quantité de données tend à être très limitée (cf. la loi des petits nombres). Par conséquent, le fait de "cadrer" structurellement le problème permet de s'assurer que les modèles statistiques souhaités sont bien appris, même lorsque les données sont limitées. Les prérequis structurels permettent également de résoudre les problèmes de stabilité numérique. Par rapport aux méthodes d'ensemble, les prérequis structurels ont tendance à prendre moins de temps que l'ingénierie des caractéristiques ; la gestion des modèles est également simplifiée. En revanche, la programmation différentiable reste une perspective assez embryonnaire à ce jour.
La perspective de Monte Carlo (1930 / 1940) peut être utilisée pour aborder les prévisions probabilistes sous un angle différent. Les modèles examinés jusqu'à présent fournissent des fonctions de densité de probabilité (PDF) explicites. Cependant, dans la perspective de Monte Carlo, un modèle peut être remplacé par un générateur - ou échantillonneur - qui génère aléatoirement des résultats possibles (parfois appelés " déviations "). Les PDFs peuvent être récupérées en calculant la moyenne des résultats du générateur, bien que les PDFs soient souvent complètement ignorées afin de réduire les exigences en termes de ressources informatiques. En effet, le générateur est souvent conçu pour être beaucoup plus compact - en termes de données - que les PDFs qu'il représente. La plupart des méthodes de deep learning - y compris celles énumérées ci-dessus pour traiter directement les prévisions probabilistes - peuvent contribuer à l'apprentissage d'un générateur. Les générateurs peuvent prendre la forme de modèles paramétriques de faible envergure (par exemple, des modèles d'espace d'état) ou de modèles hyperparamétriques (par exemple, les modèles LSTM et GRU dans le deep learning). Les méthodes d'ensemble sont rarement utilisées pour soutenir les processus génératifs en raison de leurs coûts de calcul élevés pour leurs opérations de "prédiction", qui sont largement utilisées pour soutenir l'approche de Monte Carlo.
Travailler avec des prévisions probabilistes
Obtenir des informations et des décisions utiles à partir de prévisions probabilistes nécessite des outils numériques spécialisés. Contrairement aux prévisions déterministes où les nombres sont simples, les prévisions elles-mêmes sont soit explicites, soit des fonctions de densité de probabilité, soit des générateurs de Monte Carlo. La qualité de l'outillage probabiliste est, en pratique, aussi importante que la qualité des prévisions probabilistes. Sans cet outillage, l'exploitation des prévisions probabilistes se transforme en un processus déterministe (plus de détails à ce sujet dans la section "Antipatterns" ci-dessous).
Par exemple, l'outillage doit être capable d'effectuer des tâches telles que :
- Combiner l'imprévisibilité du délai de production avec celle du délai de transport, afin d'obtenir l'imprévisibilité "totale" du délai.
- Combiner l'imprévisibilité de la demande avec l'imprévisibilité du délai, pour obtenir l'imprévisibilité "totale" de la demande à couvrir par le stock sur le point d'être commandé.
- Combinez l'imprévisibilité des retours de commande (e-commerce) avec l'imprévisibilité de la date d'arrivée de la commande du fournisseur en transit, pour obtenir le possible délai de livraison au client.
- Augmenter la prévision de la demande, produite par une méthode statistique, avec un risque résiduel dérivé manuellement d'une connaissance précise d'un contexte non reflété par les données historiques, comme une pandémie.
- Combiner l'imprésivibilité de la demande avec l'imprévisibilité de l'état du stock par rapport à la date de péremption (commerce de détail alimentaire), pour obtenir le stock possiblement restant en fin de journée.
- ...
Une fois que toutes les prévisions probabilistes - et pas seulement celles de la demande - sont correctement combinées, l'optimisation des décisions de la supply chain doit avoir lieu. Cela implique une perspective probabiliste sur les contraintes, ainsi que sur la fonction de score. Toutefois, cet aspect de l'outillage dépasse le cadre du présent document.
Il existe deux grandes " catégories " d'outils pour travailler avec les prévisions probabilistes : premièrement, l'algèbre sur les variables aléatoires, deuxièmement, la programmation probabiliste. Ces deux types d'outils se complètent mutuellement car ils ne présentent pas les mêmes avantages et inconvénients.
Une étude algébrique des variables aléatoires consiste généralement à travailler sur des fonctions de densité de probabilité explicites. L'algèbre prend en charge les opérations arithmétiques habituelles (addition, soustraction, multiplication, etc.) mais transposées à leurs équivalents probabilistes, traitant fréquemment les variables aléatoires comme statistiquement indépendantes. L'algèbre offre une stabilité numérique presque égale à celle de son homologue déterministe (c'est-à-dire les nombres simples). Tous les résultats intermédiaires peuvent être conservés pour une utilisation ultérieure, ce qui s'avère très pratique pour organiser et corriger le flux de données. En revanche, l'expressivité de ces algèbres tend à être limitée, car il n'est généralement pas possible d'exprimer toutes les dépendances conditionnelles subtiles qui existent entre les variables aléatoires.
La programmation probabiliste adopte une perspective de Monte Carlo face au problème. La logique est écrite une fois, en s'en tenant généralement à une perspective entièrement déterministe, mais elle est exécutée de nombreuses fois par l'intermédiaire de l'outil ( à savoir le processus de Monte Carlo) afin de recueillir les statistiques souhaitées. L'expressivité maximale est obtenue par des constructions "programmatiques" : il est possible de modéliser des dépendances arbitraires et complexes entre les variables aléatoires. L'écriture de la logique elle-même par le biais de la programmation probabiliste a aussi tendance à être légèrement plus facile par rapport à un calcul algébrique deq variables aléatoires, car la logique ne comprend que des nombres réguliers. En revanche, il y a un compromis constant entre la stabilité numérique (puisque plus d'itérations donnent une meilleure précision) et les ressources informatiques (plus d'itérations coûtent plus cher). En outre, les résultats intermédiaires ne sont pas facilement accessibles, car leur existence n'est que transitoire - précisément pour alléger la pression sur les ressources informatiques...
Les recherches récentes en deep learning montrent également que d'autres approches existent en plus des deux présentées ci-dessus. Par exemple, les auto-encodeurs variationnels offrent des perspectives pour effectuer des opérations sur des "espaces latents", donnant des résultats impressionnants tout en recherchant des transformations très complexes sur les données (ex : enlever automatiquement les lunettes d'un portrait photo). Bien que ces approches soient conceptuellement absolument fascinantes, elles n'ont pas montré - à ce jour - une grande pertinence pratique dans la résolution des problèmes de supply chain.
Représentation des prévisions probabilistes
La manière la plus simple de représenter une distribution de probabilité discrète est un histogramme, où l'axe vertical indique la probabilité et l'axe horizontal la valeur de la variable aléatoire concernée. Par exemple, une prévision probabiliste d'un délai d'exécution peut être affichée comme suit :
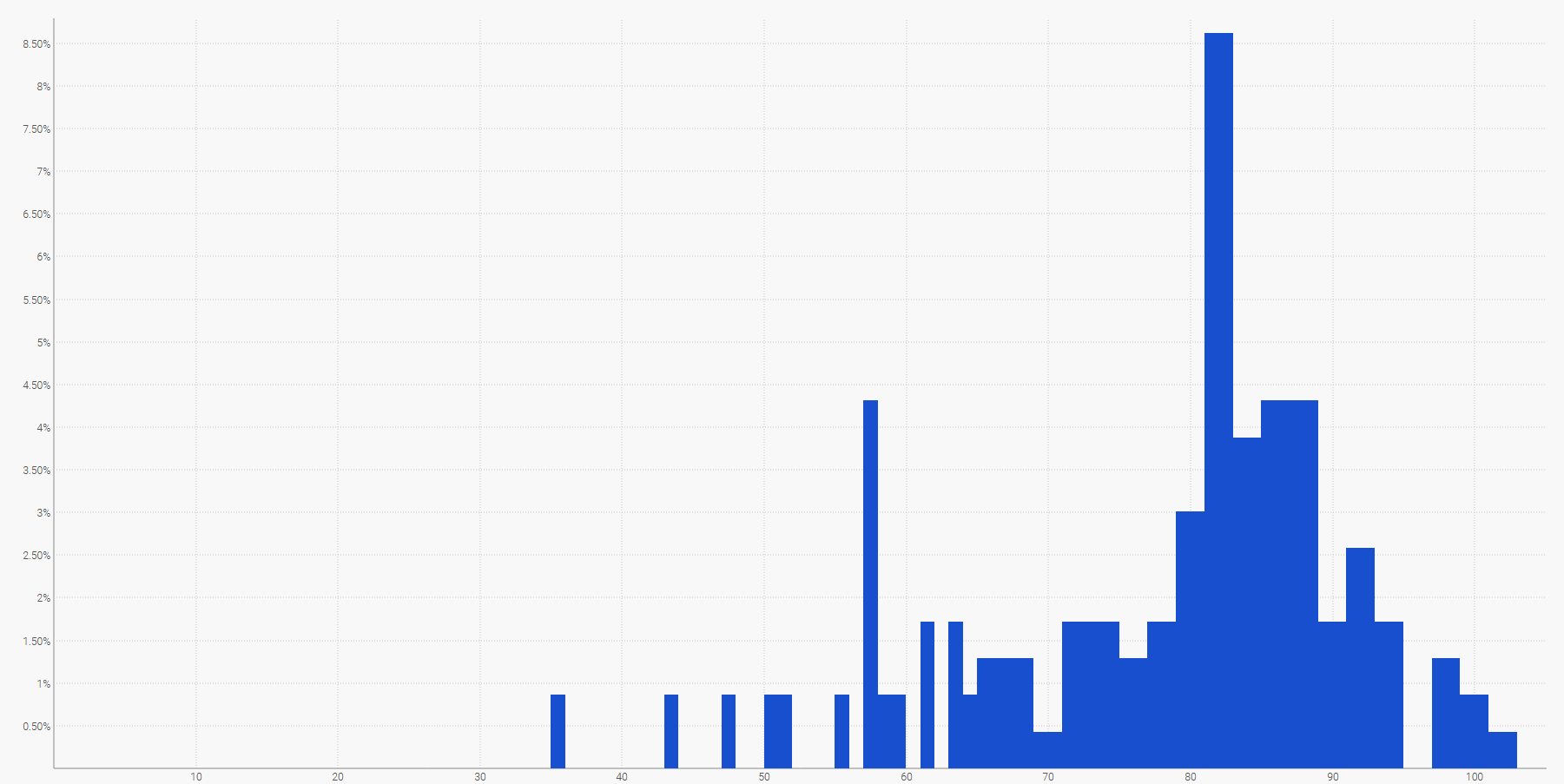
Une distribution empirique des délais observés en tranches journalières.La demande future, additionnée sur une période donnée, peut également être représentée par un histogramme. Plus généralement, l'histogramme est bien adapté à toutes les variables aléatoires unidimensionnelles par rapport à $\mathbb{Z}$, l'ensemble des entiers relatifs.
La représentation de l'équivalent probabiliste d'une série chronologique dans un même espace- c'est-à-dire une quantité variant sur des périodes de temps distinctes et de même longueur - est déjà beaucoup plus difficile. En effet, contrairement à la variable aléatoire unidimensionnelle, il n'existe pas de représentation canonique d'une telle distribution. Attention, on ne peut pas supposer que les périodes sont indépendantes. Ainsi, s'il est possible de représenter une série temporelle "probabiliste" en alignant une série d'histogrammes - un par période -, cette représentation rendrait bien mal compte de la manière dont les événements se déroulent dans une supply chain.
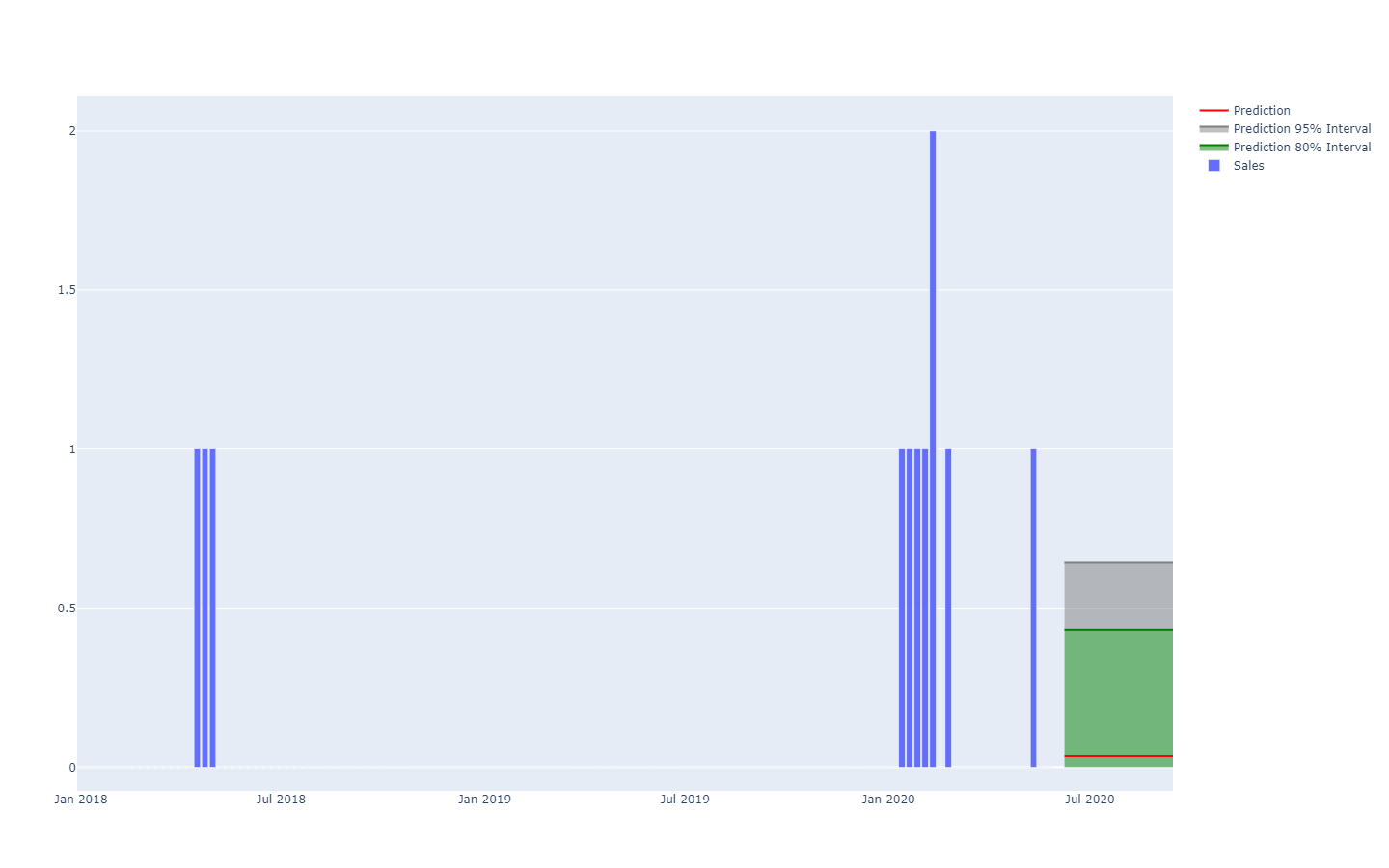
Une prévision probabiliste de la demande représentée par des seuils quantiles.Par exemple, il n'est pas complètement impossible qu'un produit nouvellement lancé soit performant et atteigne des volumes de vente élevés (un hit). Il n'est pas non plus improbable que le même produit nouvellement lancé échoue et génère de faibles volumes de ventes (un miss). Cependant, de vastes oscillations quotidiennes entre les niveaux de vente "hit" et "miss" sont extrêmement improbables.
Les intervalles de prédiction, tels qu'on les rencontre couramment dans la littérature sur la supply chain, sont quelque peu trompeurs. Ils ont tendance à mettre l'accent sur les situations de faible incertitude qui ne sont pas représentatives des situations réelles de la supply chain ;
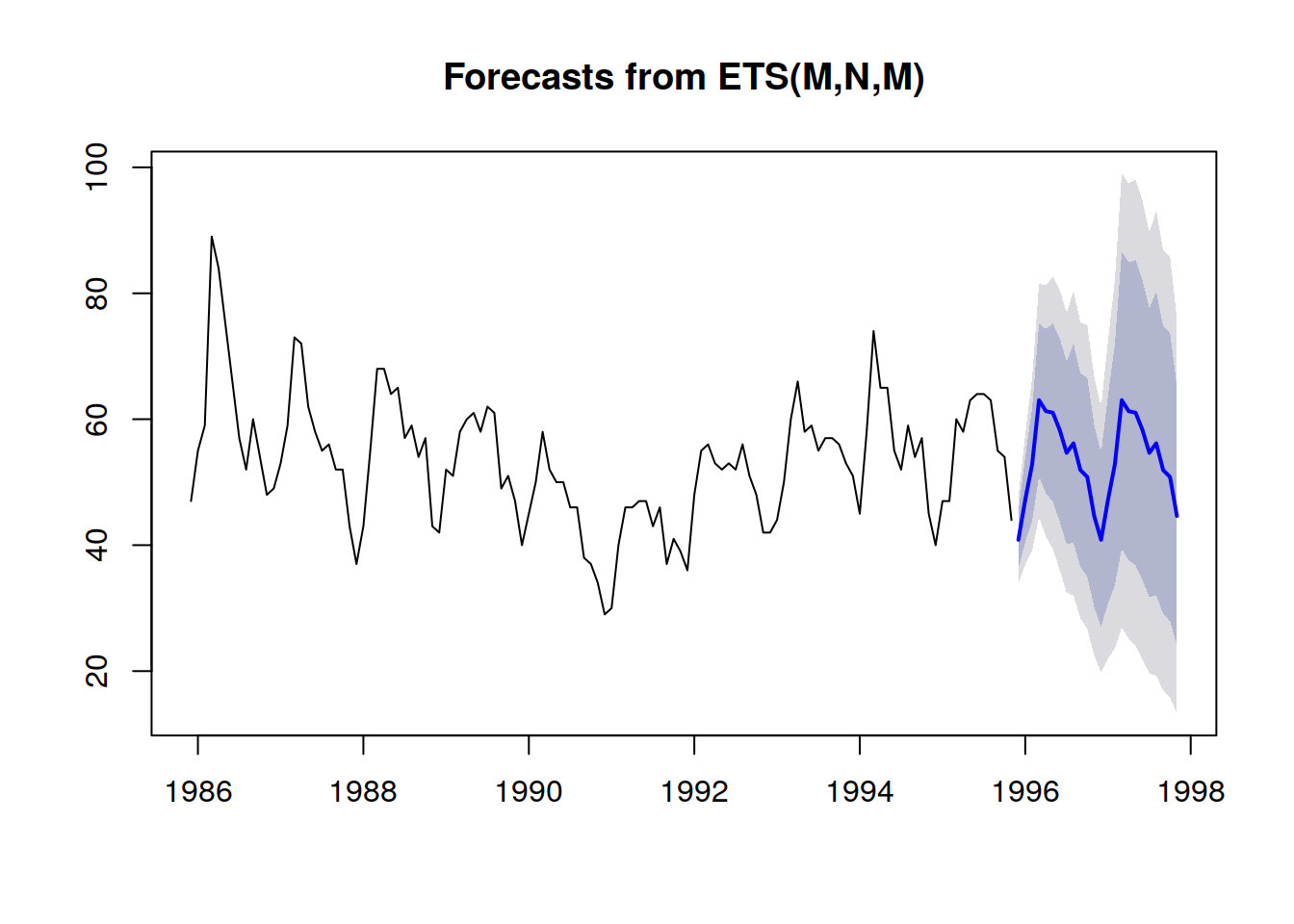
Extrait de Visualization of probabilistic forecasts, de Rob J Hyndman, 21 novembre 2014Remarquez comment ces intervalles de prédiction correspondent exactement aux distributions de probabilité, mises côte à côte avec un schéma de coloration pour souligner les seuils de quantile spécifiques.
Une meilleure représentation - c'est-à-dire une représentation qui ne met pas en valeur les fortes dépendances inter-périodes - consiste à examiner les valeurs "cumulées" dans le temps, en prenant les quantiles de celles-ci, puis en les distinguant pour retrouver les augmentations par période (voir la première illustration d'une prévision probabiliste donnée au début du présent article). La représentation est la même, mais la "sémantique" sous-jacente est différente. Nous examinons maintenant les quantiles par rapport aux "scénarios", en soulignant les scénarios extrêmement favorables (resp. défavorables).
Anti-modèles des prévisions probabilistes
Les prévisions probabilistes bousculent la façon dont de nombreuses personnes pensent "intuitivement" à l'avenir. Dans cette section, nous abordons certains des aspects les plus fréquemment mal compris de la prévision probabiliste.
Les événements "imprévisibles" n'existent pas
Du point de vue déterministe, il est impossible de prédire le résultat de la loterie, car les chances d'avoir raison sont de "une sur un million". En revanche, d'un point de vue probabiliste, le problème est simple : chaque billet a une chance sur un million de gagner. La variance très élevée du résultat ne doit pas être confondue avec une certaine "inconnaissabilité" du phénomène lui-même, qui peut être parfaitement bien compris, comme c'est le cas pour une loterie. La prévision probabiliste consiste à quantifier et à structurer la variance, et non à l'éliminer.
Les distributions " normales " n'existent pas
Les distributions normales, également appelées fonctions gaussiennes, sont omniprésentes dans les manuels de supply chain et de physique. Pourtant, dans le domaine des activités humaines, rien ou presque n'est distribué "normalement". Les distributions normales, par leur conception même, rendent les écarts importants (par rapport aux écarts moyens) extrêmement rares, au point d'être exclus par le modèle comme étant tout simplement impossibles - c'est-à-dire que les chances sont inférieures à une sur un milliard. La demande, le délai de livraison, les retours sont autant de modèles qui ne sont catégoriquement pas distribués normalement. Le seul avantage des distributions normales est qu'elles sont bien adaptées à l'élaboration d'exercices pour les étudiants, car elles se prêtent à des solutions analytiques explicites.
La présélection des probabilités
Lorsqu'on est confronté à une distribution de probabilités, il est tentant de choisir un point de la distribution, éventuellement la moyenne ou la médiane, et de se fonder sur ce chiffre pour procéder à la prévision. Ce processus va à l'encontre de l'essence même de la dimension probabiliste de la prévision. Les probabilités ne devraient pas être réduites à une seule estimation ponctuelle, car quel que soit le point choisi, ce processus entraîne une perte massive d'informations. Ainsi, bien que cela soit quelque peu perturbant, les probabilités sont destinées à être préservées en tant que telles aussi longtemps que possible. Le point d'effondrement est généralement la décision finale de la supply chain, qui maximise les rendements tout en faisant face à un avenir incertain.
Supprimer les valeurs statistiques aberrantes
La plupart des méthodes numériques classiques - fermement ancrées dans la perspective déterministe des prévisions (par exemple, les moyennes mobiles) - ont du mal lorsqu'elle rencontre des valeurs statistiques aberrantes. Ainsi, de nombreuses entreprises mettent en place des processus pour "nettoyer" manuellement les données historiques de ces valeurs aberrantes. Cependant, la nécessité d'un tel processus de nettoyage ne fait que souligner les déficiences de ces méthodes numériques. Au contraire, les aberrations statistiques sont un ingrédient essentiel de la prévision probabiliste, car elles permettent d'avoir une meilleure idée de ce qui se passe "à la queue" de la distribution. En d'autres termes, ces valeurs aberrantes sont la clé pour quantifier la probabilité de rencontrer d'autres valeurs aberrantes.
Apporter des solutions mal adaptées
Des outils spécialisés sont nécessaires pour manipuler les distributions de probabilité. La production de la prévision probabiliste n'est qu'une étape parmi d'autres pour apporter une valeur réelle à l'entreprise. De nombreux praticiens de la supply chain finissent par rejeter les prévisions probabilistes, faute d'outils appropriés pour les utiliser. De nombreux éditeurs de logiciels d'entreprise ont rejoint le mouvement et prétendent désormais prendre en charge les "prévisions probabilistes" (au même titre que l'"IA" et la "blockchain"), mais ne sont jamais allés plus loin que la mise en œuvre cosmétique de quelques modèles probabilistes (voir la section ci-dessus). La présentation d'un modèle de prévision probabiliste ne vaut pratiquement rien sans l'outillage complet permettant de tirer parti de ses résultats numériques.
Notes
[1]: La fonction
smooth() d'Envision est pratique pour régulariser des variables aléatoires par un processus d'échantillonnage discret ou équivalent.
[2]: La connaissance préalable de la structure du problème ne doit pas être confondue avec la connaissance préalable de la solution elle-même. Les "systèmes experts", conçus dans les années 1950 comme une collection de règles écrites à la main, ont échoué, car, dans la pratique, les experts humains ne parviennent pas à traduire littéralement leur intuition en règles numériques. Les a priori structurels, tels qu'ils sont utilisés dans la programmation différentiable, décrivent le principe, et non les détails, de la solution.


