Von Joannes Vermorel, November 2020Eine Vorhersage wird als probabilistisch, statt als deterministisch, betrachtet, wenn sie eine Reihe von Wahrscheinlichkeiten zu allen möglichen Zukunftsszenarien enthält und sich nicht nur auf ein mögliches Ergebnis, das als „Vorhersage“ dargestellt wird, beschränkt. Probabilistische Vorhersagen sind von Bedeutung, wenn sich die Ungewissheit nicht eingrenzen lässt, was praktisch bei jedem komplexen System der Fall ist. Für Supply-Chains sind probabilistische Vorhersagen wesentlich, um robuste Entscheidungen bei einer ungewissen Zukunft treffen zu können. Die probabilistische Vorhersage legt ein besonderes Augenmerk auf den Bedarf und die Durchlaufzeit, zwei grundlegende Aspekte der Supply-Chain-Analyse. Zusätzlich eignet sich der probabilistische Ansatz von Natur aus für die finanzielle Priorisierung von Entscheidungen nach den zu erwartenden, wenngleich ungewissen, Gewinnen. Eine Vielzahl an statistischen Modellen liefern probabilistische Vorhersagen. Strukturell betrachtet, ähneln manche eher den deterministischen Prognosen, während andere stark davon abweichen. Zur Feststellung der Genauigkeit einer probabilistischen Vorhersage sind spezifische Kennzahlen erforderlich, die sich von denen für deterministische Prognosen unterscheiden. Auch die Tools für die Auswertung von probabilistischen Vorhersagen, die speziell darauf abgestimmt sein müssen, sind unterschiedlich.
Deterministische vs. probabilistische Vorhersagen
Die Optimierung von Supply-Chains stützt sich auf die korrekte Einschätzung künftiger Ereignisse. Nummerisch betrachtet werden diese Ereignisse über „Vorhersagen oder Prognosen“ eingeschätzt, die eine Vielzahl an nummerischen Methoden zur Quantifizierung von Zukunftsereignissen umfasst. Seit den 70-er Jahren ist die am meisten verbreitete Prognoseart die deterministische Zeitreihenprognose, bei der eine Menge, die für eine bestimmte Zeit gemessen wird, etwa der Bedarf an einem Produkt in Einheiten, in die Zukunft projiziert wird. Der Abschnitt der Zeitreihe, der die Vergangenheit betrifft, besteht aus historischen Daten und der Abschnitt der Zeitreihe, der die Zukunft abdeckt, stellt die Prognose dar.
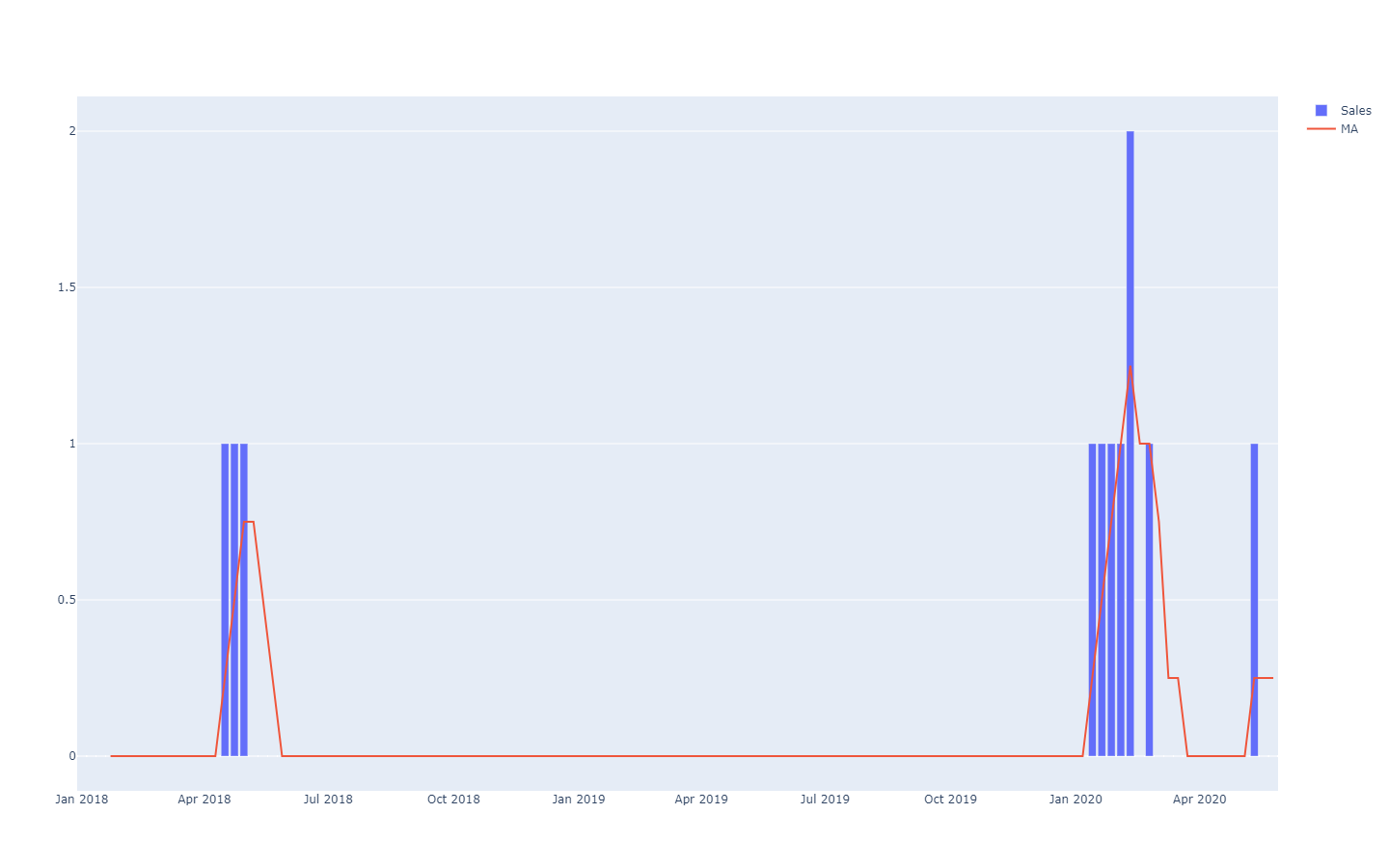 MA steht dabei für "moving average" (gleitender Mittelwert) und funktioniert bei Zeitreihen mit wenigen Daten nicht besonders gut.
MA steht dabei für "moving average" (gleitender Mittelwert) und funktioniert bei Zeitreihen mit wenigen Daten nicht besonders gut.Diese Zeitreihenprognose werden als
deterministisch bezeichnet, weil für jeden künftigen Zeitpunkt die Prognose einen einzigen Wert bietet, der so gut wie möglich dem künftigen Ergebnis entsprechen soll. Da die Prognose mit nur einem Wert arbeitet, versteht sich, dass die Wahrscheinlichkeit, dass die Prognose vollkommen richtig liegt, recht gering ist. Die Ergebnisse in der Zukunft werden von der Prognose abweichen. Wie sehr die deterministische Prognose mit den künftigen Ergebnissen übereinstimmt, wird anhand von Kennzahlen für Genauigkeit, wie etwa der mittleren quadratischen Abweichung (MSE), beurteilt.
Probabilistische Vorhersagen hingegen nehmen eine andere Perspektive beim Prognostizieren der künftigen Ergebnissen ein. Statt einen Wert als „bestes“ Ergebnis zu liefern, wird bei probabilistischen Vorhersagen jedem möglichen Zukunftsszenario eine „Wahrscheinlichkeit“ zugeordnet. Anders gesagt, sind alle künftigen Ereignisse weiterhin möglich, treten jedoch nicht mit derselben Wahrscheinlichkeit auf. Hierunter finden Sie die Visualisierung einer probabilistischen Zeitreihenprognose, in der „shotgun effect“ zu sehen ist, der in den meisten realen Fällen gewöhnlich erkennbar ist. Weiter unten gehen wir näher auf diese Visualisierung ein.
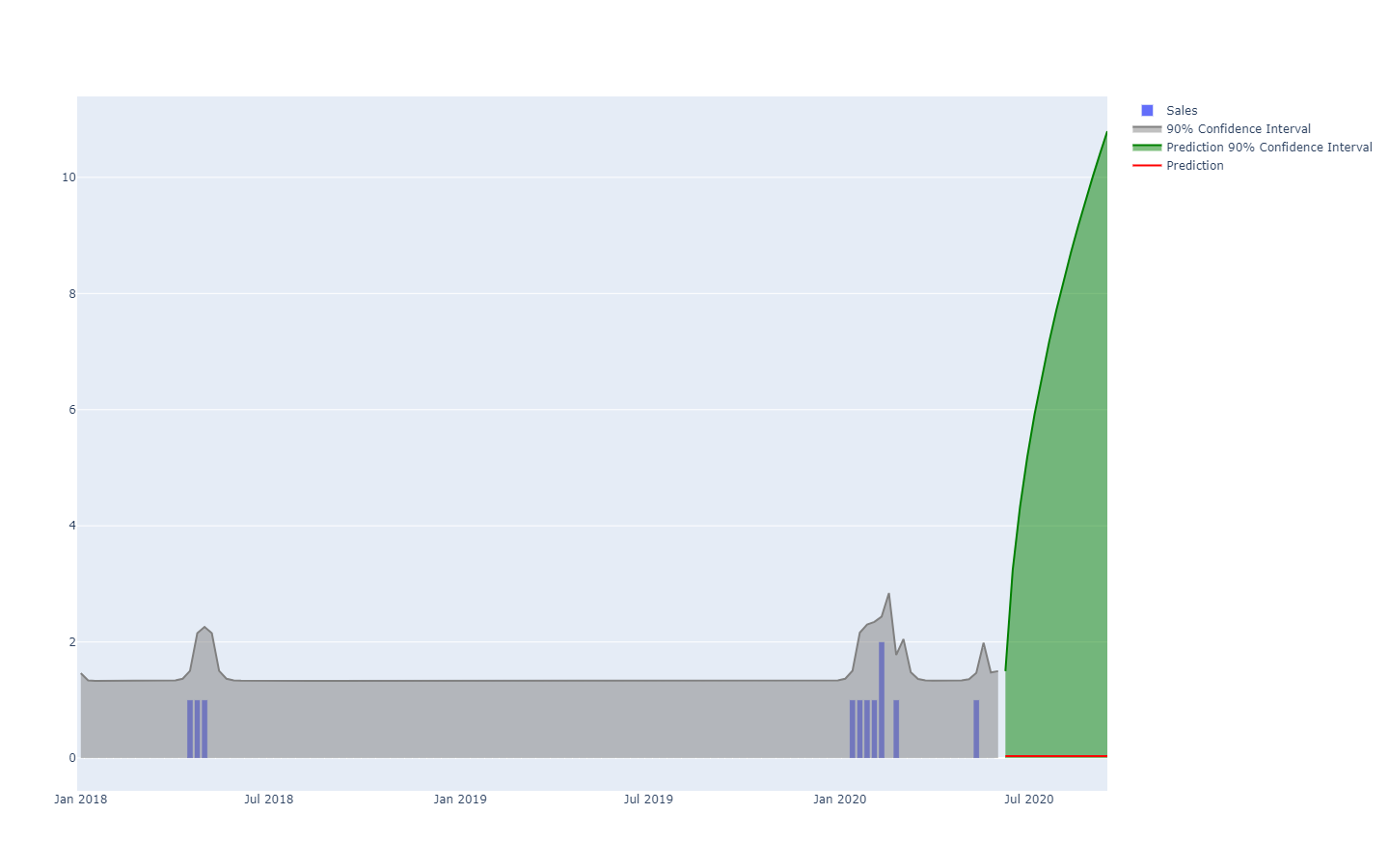 Eine probabilistische Vorhersage, die eine Situation mit einer hohen Ungewissheit darstellt.
Eine probabilistische Vorhersage, die eine Situation mit einer hohen Ungewissheit darstellt.Zeitreihen, eine Menge, die über längere Zeit gemessen wird, sind wahrscheinlich das bekannteste und meistverbreitete Datenmodell. Dieses Datenmodell kann als Prognose für deterministische oder probabilistische Ziele dienen. Dennoch bieten sich viele, häufig aussagekräftigere, alternative Datenmodelle für beide Prognosearten an. Beispielsweise kann ein Unternehmen, das Strahltriebwerke repariert, die genaue Liste von Ersatzteilen voraussagen wollen, die für eine anstehende Wartung erforderlich sein werden. Diese Voraussage kann in Form einer Prognose erfolgen, wird jedoch keine Zeitreihenprognose sein. Die deterministische Prognose, die mit der Wartungsaufgabe zusammenhängt, ist die genaue Liste mit den Ersatzteilen und deren Mengen. Dagegen ist die probabilistische Vorhersage die Wahrscheinlichkeit für jede Kombination der Teile (einschließlich deren Mengen), dass diese bestimmte Kombination tatsächlich die für die Wartung erforderliche Kombination sein wird.
Während sich die Begriffe „Prognose oder Vorhersage“ auf eine Art Schätzung im Voraus beziehen, kann die Idee allgemein auf eine
anhand statistischer Rückschlüsse getroffene Aussage über ein System, sowie auch über seine vergangenen (jedoch unbekannten) Eigenschaften, übertragen werden. Die Anwendung statistischer Prognosen kam im Laufe des 20. Jahrhunderts auf, bevor sich der Ansatz des modernen
statistischen Lernens ausbreitete, der alle datengesteuerte Hochrechnungen umfasst, die unabhängig von jeglicher zeitlichen Dimension erfolgen können. Der Einfachheit halber nutzen wir im Folgenden weiterhin die Begriffe „Prognose und Vorhersage“, auch wenn der zeitliche Aspekt immer der bekannten Vergangenheit und der ungewissen Zukunft gleicht. Beispielsweise kann ein Unternehmen schätzen wollen, wie groß der Absatz eines Produkts in einem Geschäft gewesen wäre, wenn es an diesem Tag nicht vergriffen gewesen wäre. Die Schätzung ist praktisch, um das Ausmaß des Problems in Bezug auf die Qualität der Dienstleistung zu verstehen. Doch, da das Ereignis in der Vergangenheit liegt, lassen sich die „tatsächlichen“ Absatzzahlen nicht mehr beobachten. Geht man jedoch davon aus, dass es nicht beiläufig beobachtet wurde, stellt die statistische Schätzung des vergangenen Bedarfs ein sehr ähnliches Problem zur statistischen Schätzung des künftigen Bedarfs dar.
Probabilistische Vorhersagen sind, was die Information betrifft, gehaltreicher als die deterministischen Prognosen. Während letztere sozusagen die „beste Schätzung“ des künftigen Ereignisses bietet, gibt sie keine Auskunft über die Alternativen. In der Tat kann eine probabilistische Vorhersage immer in eine deterministische umgewandelt werden, indem man den Durchschnitts-, den Median- oder Modalwert, etc. der Wahrscheinlichkeitsverteilung nutzt. Das Gegenteil trifft jedoch nicht zu, so kann aus einer deterministischen Prognose keine probabilistische erstellt werden.
Obwohl probabilistische Vorhersagen der deterministischen deutlich überlegen sind, werden sie weiterhin selten in Supply-Chains eingesetzt. Allerdings sind sie im letzten Jahrzehnt immer beliebter geworden. Historisch betrachtet kamen probabilistische Vorhersagen zu einem später Zeitpunkt auf, da sie deutlich mehr Rechenleistung benötigen. Auch die Anwendung der Ergebnisse aus den probabilistischen Vorhersagen bedarf spezieller Software-Tools, die ebenfalls häufig fehlt.
Anwendung in der Supply-Chain
Bei der Optimierung einer Supply-Chain geht es darum, die „richtigen“ Entscheidungen, aus dem jetzigen Zeitpunkt, zu treffen, die sich am besten auf eine künftige und nicht perfekt einzuschätzende Situation auswirken. Doch die mit diesen künftigen Ereignissen verbundene Ungewissheit lässt sich größtenteils nicht eingrenzen. Aus diesem Grund braucht das Unternehmen robuste Entscheidungen für den Fall, dass die Vorhersage des künftigen Ereignisses, also die Prognose, fehlerhaft ist. Die wird seit der Hälfte des 20. Jahrhunderts
minimal über Analysen des Sicherheitsbestands vorgenommen. Doch, wie wir weiter unten sehen werden, gibt es außer dem historischen Interesse keinen Grund, Sicherheitsbestände „nativen“ probabilistischen Lösungen vorzuziehen.
Die probabilistischen Vorhersage wirft einen radikal anderen Blick auf die Ungewissheit. Dieser Ansatz versucht, die Ungewissheit so gut wie möglich zu
quantifizieren. In Supply-Chains häufen sich die Kosten gewöhnlich in den statistischen Extremfällen: ein unerwartet hoher Bedarf führt zu Fehlbeständen und ein unerwartet niedriger Bedarf führt zu Lagerabschreibungen. Dazwischen findet die Bestandsrotation wie gewohnt statt. Probabilistische Vorhersagen stellen, einfach gesagt, den Versuch dar, mit solchen selten vorkommenden Situationen mit hohen Kosten – die in modernen Supply-Chains allgegenwärtig sind – umzugehen. Probabilistische Vorhersagen können und sollten auch als grundlegender Bestandteil jeglicher Maßnahme im Bereich Risiko-Management der Supply-Chain betrachtet werden.
Viele Aspekte der Supply-Chains eigenen sich hervorragend für probabilistische Vorhersagen, wie etwa:
- Bedarf: Kleidungsstücke, Zubehör, Ersatzteil, sowie auch viele andere Produktarten, die gewöhnlich schwankende und/oder sporadische Bedarfsmuster aufweisen. Produkteinführungen können „ein Hit oder ein Flop“ sein. Aktionen der Konkurrenz können vorübergehend oder sporadisch einen Großteil der Marktanteile kannibalisieren.
- Durchlaufzeit: der Import aus Übersee kann zu jedem Zeitpunkt (Herstellung, Transport, Zollabfertigung, Annahme, etc.) zu Verzögerungen in der Kette führen. Sogar lokale Lieferanten können gelegentlich längere Durchlaufzeiten haben, wenn es zu einem Fehlbestand kommt. Durchlaufzeiten sind meist Verteilungen mit „fetten Enden“.
- Ertrag (Frischkost): die Menge und Qualität der Produktion von Frischkost hängt von verschiedenen Konditionen ab, etwa vom Wetter, über die Unternehmen keine Kontrolle haben. Bei der probabilistischen Vorhersage werden diese Faktoren für die gesamte Saison quantifiziert, was die Möglichkeit bietet, über den relevanten Zeithorizonten der klassischen Wettervorhersagen hinauszugehen.
- Rücksendung (Online-Handel): Bestellt ein Kunde dasselbe Produkt in drei verschiedenen Größen, ist die Wahrscheinlichkeit, dass zwei dieser Größen zurückgesandt werden, ziemlich hoch. Auch wenn es regional unterschiedlich gehandhabt wird, machen Kunden gewöhnlich von kulanten Rückgaberechten Gebrauch. Daher sollte die Wahrscheinlichkeit einer Rücksendung bei jeder Bestellung eingeschätzt werden.
- Ausmusterung (Luftfahrt): reparierbare Teile, oft Rotables oder Umlaufteile genannt, werden manchmal nicht repariert. In diesem Fall wird das Teil ausgemustert, da es zur erneuten Einsetzung in einem Flugzeug nicht mehr geeignet ist. Obwohl man gewöhnlich im Vorfeld nicht wissen kann, ob ein Teil nach der Reparatur wieder einsatzfähig ist oder nicht, sollte die Wahrscheinlichkeit, mit der das Teil ausgemustert wird, eingeschätzt werden.
- Bestand (B2C-Einzelhandel): in einer Einzelhandelsfiliale können Kunden Ware verlagern, beschädigen oder gar stehlen. Daher stellen die elektronischen Bestandshöhen lediglich eine Annäherung zur tatsächlichen Regalverfügbarkeit dar, die die Kunden wahrnehmen. Die Bestandshöhen, wie sie von Kunden wahrgenommen werden, sollten über eine probabilistische Prognose eingeschätzt werden.
- ...
Diese kurze Liste veranschaulicht, dass die vielen Perspektiven, die probabilistische Vorhersagen einnehmen können, die einer reinen herkömmlichen „Bedarfsprognose“ bei Weitem übersteigen. Bei einer gut durchdachten Optimierung der Supply-Chain müssen alle relevanten Quellen von Ungewissheit berücksichtigt werden. Auch wenn sich die Ungewissheit manchmal eingrenzen lässt, wie das Lean Manufacturing unterstreicht, erfordert dies oft wirtschaftliche Kompromisse. Folglich ist ein gewisser Grad an Ungewissheit nicht vermeiden.
Prognosen sind jedoch lediglich auf Information fundierte Meinungen über die Zukunft. Während probabilistischen Vorhersagen als besonders detaillierte Meinungen betrachtet werden können, unterscheiden sie sich in dieser Hinsicht im Wesentlichen nicht von den deterministischen Vorhersagen. Was die Supply-Chain betrifft, liegt der Wert der probabilistischen Vorhersagen in der Art, in der die durch diese feine Struktur gewonnenen Erkenntnisse ausgelesen werden, um gewinnbringendere Entscheidungen zu treffen. Insbesondere wird nicht erwartet, dass probabilistischen Vorhersagen genauer als deterministische sind, wenn deterministische Kennzahlen für die Genauigkeit angewandt werden, um die Qualität der Prognose zu beurteilen.
Zur Verteidigung der Variabilität
Unabhängig davon, dass viele Ansätze die Supply-Chain befürworten, ist die Variabilität gekommen, um zu bleiben. Daher sind probabilistische Prognosen erforderlich. Das erste Missverständnis ist, dass Variabilität für die Supply-Chain zwangsläufig etwas Negatives ist, was nicht der Fall ist. Der zweite Irrglaube ist, dass Variabilität beseitigt werden kann, was jedoch nicht möglich ist.
Variabilität hat in verschiedenen Situationen positive Auswirkungen auf die Supply-Chain. So sind z.B. bedarfsseitig viele Branchen auf Neuheit ausgerichtet, etwa Mode, Kulturprodukte, kurz- und langlebige Luxusgüter – hier kann man von „Hits oder Flops“ reden. Die meisten neuen Produkte bieten keine Erfolge (Flops), aber die erfolgreichen (Hits), bringen gewaltige Erträge. Zusätzliche Variabilität ist gut, weil sie die Wahrscheinlichkeit von überdurchschnittlichen Erträgen erhöht, während sich die Nachteile in Grenzen halten (schlimmstenfalls wird der gesamte Bestand abgeschrieben). Dieser endlose Ansturm von neuen Produkten auf dem Markt sorgt für die ständige Erneuerung von „Hits“, während die alten verschwinden.
Auf der Angebotsseite ist, bei gleichbleibenden Bedingungen, ein Beschaffungsprozess, der für hochvariable Preisangebote sorgt, einem alternativen Prozess, der viel konsistentere (d.h. weniger variable) Preise erzeugt, überlegen. In der Tat wird die preisgünstigste Option ausgewählt, während die anderen abgelehnt werden. Dabei spielt es keine Rolle, ob der „durchschnittliche“ Beschaffungspreis niedrig ist, sondern, dass man auf günstigere Quellen stößt. Daher sollte ein guter Beschaffungsprozess so gestaltet sein, dass er die Variabilität erhöht, beispielsweise indem routinemäßige neue Lieferanten ausfindig gemacht werden, statt den Beschaffungsprozess auf die etablierten Lieferanten zu beschränken.
Manchmal kann die Variabilität aus subtileren Gründen von Vorteil sein. Etwa wenn eine Marke zu vorhersehbar ist, wenn es um ihre Werbeaktionen geht. Die Kunden erkennen das Muster und verzögern so ihren Kauf, da sie wissen, dass eine Werbeaktion kommt und wann diese kommt. Die Variabilität – oder gar Unbeständigkeit – bei den Werbemaßnahmen wirkt diesem Verhalten bis zu einem gewissen Grad entgegen.
Ein weiteres Beispiel sind Faktoren innerhalb der Supply-Chain, die für Verwechselung sorgen. Wenn neue Produkte immer mit einer TV-Kampagne und einer Radiokampagne eingeführt werden, wird es statistisch schwierig, die jeweiligen Wirkungen des Fernsehens und des Radios zu unterscheiden. Variiert man etwas die Intensität der Kampagne im Zusammenhang mit dem genutzten Werbekanal, lassen sich im Nachhinein mehr statistische Informationen aus diesen Maßnahmen extrahieren. Diese liefern Erkenntnisse darüber, wie Marketingressourcen besser eingesetzt werden können.
Selbstverständlich ist nicht jede Variabilität gut. Lean Manufacturing betont zu Recht, dass auf der Produktionsebene der Lieferkette Variabilität in der Regel nachteilig ist, insbesondere wenn es um unterschiedliche Verzögerungen geht. In der Tat können sich versehentlich LiFo-Verfahren (Last-in-First-out) einschleichen, was wiederum die Variabilität der Durchlaufzeit vergrößert. In solchen Situationen sollte die versehentliche Variabilität beseitigt werden. Typischerweise geschieht dies durch ein besseres Verfahren, teils durch eine bessere Ausstattung oder bessere Anlagen.
Variabilität lässt sich oft nicht verringern, gar wenn sie schädlich ist. Wie wir im folgenden Abschnitt sehen werden, folgen Supply-Chains dem Zwei-Drittel-Gesetz. Es ist ein Trugschluss zu glauben, dass auf Filialebene – deterministisch betrachtet – jemals zuverlässig vorhergesagt werden kann, während nicht einmal die Kunden selbst immer wissen, was sie kaufen werden. Allgemein kann gesagt werden, dass die Verringerung der Variabilität immer einen Preis hat (der umso höher wird, desto niedriger die Variabilität wird), während die marginale Verringerung der Variabilität nur geringere Erträge bringt. Selbst wenn die Variabilität, für jegliche Ziele, verringert werden kann, lässt sie sich aufgrund der wirtschaftlichen Auswirkungen nur sehr selten vollständig entfernen.
Das Zwei-Drittel-Gesetz
Das Zwei-Drittel-Gesetz kann in der Supply-Chain wie folgt formuliert werden: „Kleine Zahlen überwiegen entlang der gesamten Kette.“ Dieses Beobachtungsgesetz ergibt sich aus Skaleneffekten und anderen Kräften, die die meisten strukturellen Aspekte von Lieferketten antreiben:
- ein Lieferant, der zehntausende Materialeinheiten täglich liefert, hat wahrscheinlich Mindestbestellmengen (MOQ) oder Preisnachlässe, mit denen die Häufigkeit der Bestellungen gesenkt wird. Die Anzahl von Bestellungen, die an einem beliebigen Tag an einen Lieferanten gemacht werden, übersteigt selten eine einstellige Zahl.
- eine Fabrik, in der zehntausende Einheiten täglich produziert werden, arbeitet wahrscheinlich mit großen Chargen von tausenden Einheiten. Die Produktionsleistung wird wahrscheinlich auf ganzen Paletten verpackt. Die Anzahl der Chargen an einem bestimmten Tag ist höchstens eine kleine, zweistellige Zahl.
- ein Lager, in das zehntausende Einheiten täglich erhalten werden, wird wahrscheinlich von Lkws beliefert, wobei jeder Lkw seine gesamte Ladung im Lager entlädt. Die Anzahl der Lkw-Lieferungen an einem Tag übersteigt selbst bei sehr großen Lagern selten eine zweistellige Zahl.
- ein Einzelhandelsgeschäft, das zehntausende Einheiten auf Lager halten kann, teilt das Sortiment wahrscheinlich in tausende Produktreferenzen auf. Die Anzahl der auf Lager gehaltenen Einheiten jedes Produkt überschreitet sehr selten eine einstellige Zahl.
- ...
Natürlich lassen sich die Zahlen immer durch die Änderung der Maßeinheit aufblähen. Zählen wir beispielsweise statt der Anzahl von Paletten die Anzahl an
Gramm auf den Paletten oder deren Geldwert in USD-Cent, stehen wir vor großen Zahlen. Das Zwei-Drittel-Gesetz sollte jedoch mit der Idee verstanden werden, dass Dingen aus einer sinnvollen Supply-Chain-Perspektive gezählt werden. Auch wenn dieses Prinzip in der Theorie recht subjektiv erscheinen mag, ist es in der Praxis aufgrund der offensichtlich diskreten Anwendbarkeit in modernen Lieferketten nicht der Fall: Bündel, Kisten, Paletten, Container, LKWs ...
Dieses Gesetz ist von großer Relevanz für die Perspektive der probabilistischen Vorhersage. Erstens wird dargelegt, dass „diskrete“ Prognosen im Zusammenhang mit Supply-Chains vorrangig eingesetzt werden, d. h. das zu prognostizieren (oder zu entscheidende) Ergebnis ist eine „ganze Zahl“ statt einer Bruchzahl. Probabilistische Vorhersagen eignen sich besonders für
diskrete Situationen, da für jedes diskrete Ergebnis eine Wahrscheinlichkeit geschätzt werden kann. Im Gegensatz dazu haben deterministische Prognosen mit diskreten Ergebnissen zu kämpfen. Was soll zum Beispiel bedeuten, dass der erwartete Tagesabsatz eines Produkts bei 1,3 Einheiten liegt? Einheiten werden ja nicht in „Bruchteilen“ verkauft. Während aus dieser Aussage sinnvollere „diskrete“ Interpretationen abgeleitet werden können, ist ihr probabilistisches Gegenstück (z. B. eine Wahrscheinlichkeit von 27 % auf einen Bedarf von 0 Einheiten, eine Wahrscheinlichkeit von 35 % für einen Bedarf von 1 Einheit, eine Wahrscheinlichkeit von 23 % für einen Bedarf von 2 Einheiten usw.) viel direkter, weil es sich auf diskrete Natur des konkreten Phänomens bezieht.
An zweiter Stelle kann man sich die Rechenressourcen genauer ansehen. Während probabilistische Prognosen auf den ersten Blick deutlich anspruchsvoller erscheinen können, sind sie es in der Praxis nicht, was gerade auf das Zwei-Drittel-Gesetz zurückzuführen ist. Um auf den o.g. Tagesabsatz zurückzukommen, macht es in der Tat keinen Sinn, die Wahrscheinlichkeit, dass der Bedarf an einem bestimmten Tag über 100 liegt, numerisch zu schätzen. Diese Wahrscheinlichkeiten können auf null bzw. auf einen beliebig winzigen Wert gerundet werden. Die Auswirkung auf die numerische Genauigkeit des Lieferkettenmodells ist zu vernachlässigen. Als Faustregel kann man davon ausgehen, dass probabilistische Prognosen etwa drei Größenordnungen mehr Rechenressourcen benötigen als deterministische Prognosen. Trotz dieses Mehraufwands übersteigen die Vorteile in Bezug auf die Leistung der Supply-Chain die Kosten für die Rechenressourcen bei weitem.
Genauigkeitsmetriken für probabilistische Prognosen
Unabhängig davon, was letztendlich passiert, zeigt eine vernünftige probabilistische Vorhersage, dass die Wahrscheinlichkeit für das Eintreten dieses Ergebnisses in der Tat nicht gleich null war. Das ist faszinierend, weil es auf den ersten Blick so aussehen mag, als wären probabilistische Vorhersagen realitätsfern – wie ein Wahrsager, der vieldeutige Prophezeiungen macht, die sich niemals als falsch erweisen können, da man im Nachhinein stets eine Erklärung über die richtige Interpretation der Prophezeiungen hervorzaubern kann. Tatsächlich gibt es mehrere Möglichkeiten, die Qualität einer probabilistischen Prognose quantitativ zu beurteilen. Einige dieser Möglichkeiten sind „Metriken“, die im Wesentlichen den Metriken zur Beurteilung der Genauigkeit von deterministischen Prognosen ähneln. Andere Möglichkeiten sind im Vergleich zur deterministischen Perspektive radikaler und tiefgründiger.
Sehen wir uns kurz vier verschiedene Ansätze zur Beurteilung der Genauigkeit einer probabilistischen Prognose an:
- Pinball-Loss-Funktion
- Continuous Ranked Probability Score (CRPS)
- Bayesscher Wahrscheinlichkeitsbegriff
- Generative Adversarial Perspective
Die
Pinball-Loss-Funktion liefert eine Genauigkeitsmetrik für eine Quantilschätzung, die aus einer probabilistischen Vorhersage abzuleiten ist. Wenn wir z.B. die Lagermenge abschätzen wollen, die mit einer Wahrscheinlichkeit von 98 % der Nachfrage der Kunden nach einem Produkt in einer Filiale entspricht oder größer ist, kann diese Menge direkt aus den probabilistischen Prognosen erhalten werden, indem einfach die Wahrscheinlichkeiten addiert werden. Dabei beginnt man mit einem Bedarf von 0 Einheit, einem Bedarf von 1 Einheit, ... bis die Wahrscheinlichkeit gerade 98 % überschreitet. Die Pinball-Loss-Funktion misst direkt die Qualität dieser verzerrten Schätzung des zukünftigen Bedarfs. Sie kann als ein Werkzeug betrachtet werden, mit dem die Qualität eines beliebigen Punktes der kumulativen Dichtefunktion der probabilistischen Prognose beurteilt werden kann.
Der
Continuously Ranked Probability Score (CRPS) liefert eine Metrik, die als „Menge der Verschiebung“ der Wahrscheinlichkeitsmaße interpretiert werden kann, der erforderlich ist, um das gesamte Wahrscheinlichkeitsmaß zum beobachteten Ergebnis zu bewegen. Es ist die direkteste Verallgemeinerung des mittleren absoluten Fehlers (MAE) zu einer probabilistischen Perspektive. Der CRPS-Wert ist homogen mit der Maßeinheit des eigentlichen Ergebnisses. Diese Perspektive kann auf beliebige metrische Räume verallgemeinert werden, anstatt auf nur eindimensionale Fälle, was über die so genannte „Transporttheorie“ und den Monge-Kantorowitsch-Abstand geht (die würde jedoch den Rahmen des vorliegenden Dokuments sprengen).
Die Wahrscheinlichkeit und ihre Verwandte,
die Kreuzentropie, nimmt die Bayes'sche Perspektive der
geringsten Überraschung ein: je höher die Wahrscheinlichkeit der beobachteten Ergebnisse, desto besser. Zum Beispiel haben wir zwei probabilistische Modelle A und B: Das Modell A besagt, dass die Wahrscheinlichkeit, einen Bedarf von 0 Einheiten zu beobachten, für einen beliebigen Tag 50 % beträgt; das Modell B besagt, dass die Wahrscheinlichkeit, einen Bedarf von 0 Einheiten zu beobachten, für einen beliebigen Tag 1 % beträgt. Wir beobachten den Bedarf über 3 Tage und erhalten die folgenden Beobachtungen: 0, 0, 1. Das Modell A hatte eine etwa 10 %-ige Chance, diese Beobachtungen zu erzeugen, während diese für das Modell B nur bei groben 0,01 % lag. Somit ist das Modell B im Vergleich zu Modell A mit einer wesentlich geringeren Wahrscheinlichkeit das richtige Modell. Die Wahrscheinlichkeit weicht von der deterministischen Perspektive ab, ein sinnvolles
absolutes Kriterium zur Beurteilung von Modellen zu haben. Stattdessen bietet es einen Mechanismus zum
Vergleich von Modellen, aber numerisch kann der Mechanismus
außer für den Vergleich von Modellen für nichts anderes genutzt werden.
Die Generative Adversarial Perspective stellt die modernste Perspektive auf die Angelegenheit dar (Ian Goodfellow et al., 2014). Im Wesentlichen besagt diese Perspektive, dass das „beste“ probabilistische Modell dasjenige ist, das verwendet werden kann, um Ergebnisse – im Monte-Carlo-Stil – zu generieren, die sich von realen Ergebnissen nicht unterscheiden. Wenn wir z. B. die historische Liste der Transaktionen in einem lokalen Supermarkt betrachten, könnten wir diese Historie zu einem beliebigen Zeitpunkt in der Vergangenheit abschneiden und das probabilistische Modell verwenden, um weitere unechte, aber realistische Transaktionen zu erzeugen. Das Modell würde als „perfekt“ gelten, wenn sich durch statistische Analysen der Zeitpunkt, an dem der Datensatz von „echten“ zu „unechten“ Daten übergeht, nicht mehr feststellen ließe. Sinn des Generative Adversarial Ansatzes ist, die Metriken zu „lernen“, die den Fehler eines probabilistischen Modells verschlimmern. Anstatt sich auf eine bestimmte Metrik zu konzentrieren, nutzt diese Perspektive rekursiv Techniken des maschinellen Lernens, um die Metriken selbst zu „lernen“.
Die Suche nach besseren Möglichkeiten, die Qualität von probabilistischen Vorhersagen zu beurteilen, ist ein aktives Forschungsgebiet. Es gibt keine klare Abgrenzung zwischen den beiden Fragen „Wie kann man eine bessere Prognose erstellen?“ und „Wie kann man feststellen, ob eine Prognose besser ist?“ Durch die neuesten Erkenntnisse sind die Grenzen zwischen den beiden Fragen deutlich gewichen. Wahrscheinlich werden die nächsten Durchbrüche die Art, in der man probabilistische Prognosen überhaupt betrachtet, weiter verändern.
Äußerst minimale Wahrscheinlichkeiten und Log-Likelihood
Sehr kleine Wahrscheinlichkeiten kommen selbstverständlich vor, wenn man mehrdimensionale Fälle aus der Perspektive der probabilistischen Vorhersagen betrachtet. Diese kleinen Wahrscheinlichkeiten sind problematisch, weil Computer keine unendlich genauen Zahlen verarbeiten. Rohe Wahrscheinlichkeitswerte sind häufig „minimal“ in dem Sinne, dass sie aufgrund von Grenzen der numerischen Genauigkeit auf null gerundet werden. Die Lösung für dieses Problem besteht nicht in der Aufrüstung der Software, um beliebig genaue Berechnungen zu erhalten – was von der Rechenleistung her äußerst ineffizient ist –, sondern in der Anwendung des „Log-Tricks“, der Multiplikationen in Additionen umwandelt. Dieser Trick wird – auf irgendeine Weise – von praktisch jeder Software genutzt, die sich mit probabilistischen Vorhersagen beschäftigt.
Nehmen wir an, wir haben $X_1$, $X_2$, ..., $X_n$ Zufallsvariablen, die den Tagesbedarf für alle $n$ verschiedenen Produkte darstellen, die in einem bestimmten Geschäft angeboten werden. $\hat{x}_1$, $\hat{x}_2$, .., $\hat{x}_n$ entspricht dem empirischen Bedarf, der am Ende des Tages für jedes Produkt beobachtet wird. Für das erste Produkt – bestimmt durch $X_1$ – wird die Wahrscheinlichkeit, $\hat{x}_1$ zu beobachten, als $P(X_1 = \hat{x}_1)$ geschrieben. Wir lehnen uns aus dem Fenster und nehmen der Klarheit halber an, dass alle Produkte in Bezug auf den Bedarf streng unabhängig sind. Die Wahrscheinlichkeit für das gemeinsame Ereignis der Beobachtung von $\hat{x}_1$, $\hat{x}_2$, .., $\hat{x}_n$ ist:
$$P(X_1 = \hat{x}_1 \dots X_n = \hat{x}_n) = \prod_{k=1}^n P(X_k = \hat{x}_k)$$
Ist $P(X_k = \hat{x}_k) \approx \frac{1}{2}$ (grobe Näherung) und $n = 10000$ dann liegt die obige gemeinsame Wahrscheinlichkeit in der Größenordnung von $\frac{1}{2^{10000}} \approx 5 * 10^{-3011}$, was einen sehr kleinen Wert darstellt. Dieser Wert stellt einen Unterlauf dar, d.h. es ist zu klein um selbst bei 64-Bit-Gleitkommazahlen, die typischerweise für wissenschaftliche Berechnungen verwendet werden, dargestellt zu werden.
Der „Log-Trick“ besteht darin, mit dem Logarithmus des Ausdrucks zu arbeiten, d.h.:
$$\ln P(X_1 = \hat{x}_1 \dots X_n = \hat{x}_n) = \sum_{k=1}^n \ln P(X_k = \hat{x}_k)$$
Der Logarithmus macht aus der Reihe von Multiplikationen eine Reihe von Additionen, was sich numerisch als wesentlich stabiler erweist als eine Reihe von Multiplikationen.
Der „Log-Trick“ wird häufig verwendet, wenn es um probabilistische Vorhersagen geht. Die „Log-Likelihood“ ist also wörtlich der Logarithmus der Wahrscheinlichkeit (die zuvor eingeführt wurde), gerade weil die rohe Wahrscheinlichkeit in der Regel numerisch nicht darstellbar wäre, wenn man die gängigen Arten von Gleitkommazahlen betrachtet.
Arten von Algorithmen für probabilistische Vorhersagen
Die Frage nach der computergesteuerten Generierung von probabilistischen Prognosen ist fast so umfangreich wie das gesamte Feld des maschinellen Lernens selbst. Die Abgrenzungen zwischen den beiden Bereichen sind, wenn überhaupt, meist eine subjektive Frage. Dennoch wird in diesem Abschnitt eine eher wahllose Liste von herausstechenden algorithmischen Ansätzen vorgestellt, die für die Erstellung probabilistischer Vorhersagen verwendet werden können.
Anfang des 20. Jahrhunderts, möglicherweise schon Ende des 19. Jahrhunderts, kam die Idee des
Sicherheitsbestands auf, bei dem die Ungewissheit um den Bedarf nach einer Normalverteilung modelliert wird. Für andere Wissenschaften, insbesondere für die Physik, waren bereits vorberechnete Standardnormalverteilungstabellen erstellt worden. Somit musste für die Anwendung des Sicherheitsbestandes lediglich ein Bedarfsniveaus mit einem „Sicherheitsbestandskoeffizienten“ multipliziert werden, der aus einer bereits existierenden Tabelle gezogen wurde. Vereinzelt enthielten viele Supply-Chain-Lehrbücher, die bis in die 1990er Jahre geschrieben wurden, in ihren Anhängen noch Standardnormalverteilungstabellen. Leider ist der größte Nachteil dieses Ansatzes die Tatsache, dass „Normalverteilungen“ für Lieferketten nicht sinnvoll sind. An erster Stelle kann man bei Supply-Chains davon ausgehen, dass „nichts“ jemals „normalverteilt“ ist. An zweiter Stelle ist die Normalverteilung eine stetige Verteilung, was im Widerspruch zur diskreten Natur der Ereignisse um die Supply-Chain steht (siehe „Zwei-Drittel-Gesetz“ oben). Während also technisch betrachtet „Sicherheitsbestände“ eine probabilistische Komponente besitzen, sind die zugrundeliegenden Methoden und numerischen Rezepte deterministisch ausgerichtet. Dieser Ansatz wird hier dennoch jedoch der Übersichtlichkeit halber angeführt.
In den frühen 2000er Jahren kamen Ensemblemethoden auf, deren bekannteste Vertreter wohl Random Forests und Gradient Boosted Trees sind. Diese lassen sich relativ einfach von ihrem deterministischen Ursprung auf die probabilistische Perspektive erweitern. Die Schlüsselidee hinter dem Ensemble Learning ist aus der Kombination zahlreicher, schwacher, deterministischer Prädiktoren, wie z. B. Entscheidungsbäumen, einen überlegenen deterministischen Prädiktor zu erstellen. Es ist jedoch möglich, den Mischprozess so anzupassen, dass statt nur ein einzelnes aggregiertes Ergebnis Wahrscheinlichkeiten erhalten werden. Dies macht aus der Ensemblemethode eine probabilistischen Prognosemethode. Diese Methoden sind nichtparametrisch und in der Lage, Verteilungen mit fetten Enden und/oder multimodale Verteilungen einzuschließen, wie sie in der Lieferkette häufig vorkommen. Diese Methoden haben in der Regel zwei bemerkenswerte Nachteile. Erstens enthält die Wahrscheinlichkeitsdichtefunktion, die von dieser Art von Modellen erzeugt wird, von Design aus tendenziell eine Menge Nullen, wodurch jegliche Versuche, die „Log-Likelihood-Metrik“ zu nutzen, verhindert werden. Generell passen diese Modelle nicht wirklich zur Bayes'schen Perspektive, da neuere Beobachtungen häufig vom Modell als „unmöglich“ (d.h. mit einer Wahrscheinlichkeit gleich Null) deklariert werden. Dieses Problem kann jedoch durch Regularisierungsmethoden gelöst werden[1]. Zweitens sind Modelle häufig so groß wie ein beträchtlicher Teil des Eingabedatensatzes, wodurch die „Vorhersageberechnung“ fast so viel Rechenleistung benötigt wie die „Lernberechnung“.
Die hyperparametrischen Methoden, die unter dem Namen „Deep Learning“ bekannt sind und in den 2010er Jahren explosionsartig aufkamen, waren fast „durch Zufall“ probabilistisch. Während sich die überwiegende Mehrheit der Aufgaben, bei denen Deep Learning wirklich glänzt (z.B. Bildklassifizierung), nur auf deterministische Vorhersagen konzentriert, weist die Metrik der Kreuzentropie – eine Variante der oben besprochenen Log-Likelihood – sehr steile Gradienten auf, die häufig gut für den stochastischen Gradientenabstieg (SGD) geeignet sind, auf dem Deep-Learning-Methoden beruhen. Somit sind Deep-Learning-Modelle probabilistisch. Jedoch nicht, weil Wahrscheinlichkeiten von Interesse wären, sondern weil der Gradientenabstieg schneller konvergiert, wenn die Verlustfunktion eine probabilistische Prognose widerspiegelt. Die Supply-Chains sticht dabei in Bezug auf Deep Learning mit ihrem Interesse am eigentlichen probabilistischen Ergebnis des Deep-Learning-Modells hervor, während die meisten anderen Anwendungsfälle die Wahrscheinlichkeitsverteilung auf ihren Mittelwert, Median oder Modus zusammenfassen. Das Mixture Density Networks ist eine Art von Deep-Learning-Netzwerk, das auf das Lernen komplexer Wahrscheinlichkeitsverteilungen ausgerichtet ist. Das Ergebnis selbst ist eine parametrische Verteilung, die möglicherweise aus Gaußschen Werten besteht. Im Gegensatz zu Sicherheitsbeständen kann eine Mischung aus vielen Gaußglocken in der Praxis jedoch das Verhalten der fetten Enden widerspiegeln, das in den Lieferketten zu beobachten ist. Während Deep-Learning-Methoden häufig als Stand der Technik angesehen werden, ist anzumerken, dass das Erreichen der numerischen Stabilität, insbesondere bei Dichtemischungen, nach wie vor eine Art „dunkle Kunst“ darstellt.
Das differenzierbare Programmieren stammt vom Deep Learning ab, das erst in den späten 2010er Jahren beliebt wurde. Es hat viele technische Attribute mit Deep Learning gemeinsam, unterscheidet sich jedoch deutlich in ihrem Fokus. Während beim Deep Learning das Erlernen beliebig komplexer Funktionen (z.B. das Spielen von Go) durch das Stapeln einer großen Anzahl einfacher Funktionen (z.B. Faltungsschichten) im Vordergrund steht, konzentriert sich das differenzierbare Programmieren auf die Feinstruktur des Lernprozesses. Die detaillierteste, ausdrucksstärkste Struktur kann wörtlich als Programm formatiert werden, das Verzweigungen, Schleifen, Funktionsaufrufe usw. beinhaltet. Das differenzierbare Programmieren ist für die Lieferkette von großem Interesse, da Probleme gewöhnlich in hochstrukturierter Form vorkommen, und die Experten diese Strukturen kennen[2]. Zum Beispiel kann der Absatz eines bestimmten Hemdes durch ein anderes Hemd in einer anderen Farbe kannibalisiert werden, aber nicht durch den Absatz eines Hemdes, das drei Größen größer oder kleiner ist. Solche strukturellen Priorverteilungen sind der Schlüssel, um eine hohe Dateneffizienz zu erreichen. In der Tat ist die Datenmenge aus Sicht der Lieferkette tendenziell sehr begrenzt (vgl. das Zwei-Drittel-Gesetz). Daher hilft die strukturelle „Eingrenzung“ des Problems, um sicherzustellen, dass die gewünschten statistischen Muster gelernt werden, selbst wenn nur begrenzte Daten vorliegen. Strukturelle Priorverteilungen helfen auch, Probleme mit der numerischen Stabilität zu lösen. Im Vergleich zu Ensemblemethoden sind strukturelle Priorverteilungen tendenziell weniger zeitaufwändig als das Feature-Engineering; auch die Pflege des Modells wird vereinfacht. Auf der anderen Seite steckt das differenzierbare Programmieren bis heute noch praktisch in den Kinderschuhen.
Mit der Monte-Carlo-Perspektive (1930 / 1940) kann man sich probabilistischen Prognosen aus einem anderen Blickwinkel nähern. Die bisher diskutierten Modelle liefern explizite Wahrscheinlichkeitsdichtefunktionen (PDFs). Aus der Monte-Carlo-Perspektive kann ein Modell jedoch durch einen Generator, oder Sampler, ersetzt werden, der zufällig mögliche Ergebnisse (manchmal auch „Abweichungen“ genannt) erzeugt. PDFs können über den Durchschnitt der Ergebnisse des Generators erstellt werden, obwohl sie häufig ganz umgangen werden, um die Rechenressourcen zu schonen. In der Tat ist der Generator häufig so konzipiert, dass er datenmäßig wesentlich kompakter ist als die PDFs, die er darstellt. Die meisten Methoden des maschinellen Lernens – einschließlich der oben aufgeführten, die sich direkt mit probabilistischen Prognosen befassen – können zum Lernen eines Generators beitragen. Generatoren können in Form von niedrigdimensionalen parametrischen Modellen (z. B. Zustandsraummodelle) oder von hyperparametrischen Modellen (z. B. die LSTM- und GRU-Modelle beim Deep Learning) präsentiert werden. Ensemblemethoden werden aufgrund der hohen Kosten der erforderlichen Rechenleistung für ihre „Vorhersageberechnung“ – die zur Unterstützung des Monte-Carlo-Ansatzes herangezogen werden – selten zur Unterstützung generativer Verfahren eingesetzt.
Einsatz von probabilistischen Vorhersagen
Die Ableitung nützlicher Erkenntnisse und Entscheidungen aus probabilistischen Vorhersagen erfordert spezielle numerische Tools. Im Gegensatz zu deterministischen Prognosen, bei denen es sich um einfache Zahlen handelt, sind die Prognosen selbst entweder explizite Wahrscheinlichkeitsdichtefunktionen oder Monte-Carlo-Generatoren. Die Qualität der probabilistischen Tools ist in der Praxis genauso wichtig wie die Qualität der probabilistischen Vorhersagen. Ohne diese Tools wird die Nutzung der probabilistischen Vorhersagen zu einem deterministischen Prozess (mehr dazu im Abschnitt „Antipatterns“ weiter unten).
So sollten die Tools beispielsweise in der Lage sein, folgende Aufgaben zu erfüllen:
- Die ungewisse Durchlaufzeit der Produktion mit der ungewissen Durchlaufzeit des Transports kombinieren, um die „gesamte“ ungewisse Durchlaufzeit festzustellen.
- Den ungewissen Bedarf mit der ungewissen Durchlaufzeit kombinieren, um den „gesamten“ ungewissen Bedarf festzustellen, der vom zu bestellenden Bestand gedeckt werden soll.
- Die ungewisse Anzahl an Rücksendungen (E-Commerce) mit dem ungewissen Ankunftsdatum der versendeten Lieferantenbestellung kombinieren, um die ungewisse Durchlaufzeit für den Kunden festzustellen.
- Die anhand einer statistischen Methode erstellte Bedarfsprognose um das Extremrisiko erweitern, das manuell aus dem tiefgründigen Verständnis einer Situation abgeleitet wird, die historischer Daten nicht widerspiegeln, wie z. B. eine Pandemie.
- Den ungewissen Bedarf mit dem ungewissen Zustand des Lagerbestands in Bezug auf das Verfallsdatum (Lebensmitteleinzelhandel) kombinieren, um den unsicheren Restbestand am Ende des Tages festzustellen.
- ...
Sobald alle probabilistischen Prognosen – nicht nur die Bedarfsprognosen – richtig kombiniert sind, sollte die Optimierung der Entscheidung in Bezug auf die Supply-Chain erfolgen. Dies schließt eine probabilistische Perspektive auf die Bedingungen sowie auf die Score-Funktion mit ein. Dieser Aspekt des Tools geht jedoch über den Rahmen des vorliegenden Dokuments hinaus.
Es gibt zwei große „Arten“ von Tools für den Einsatz von probabilistischen Vorhersagen: erstens Algebren von Zufallsvariablen, zweitens probabilistische Programmierung. Diese beiden Arten ergänzen sich gegenseitig, da sie unterschiedliche Vor- und Nachteile haben.
Eine Algebra der Zufallsvariablen arbeitet typischerweise mit expliziten Wahrscheinlichkeitsdichtefunktionen. Die Algebra unterstützt die üblichen arithmetischen Operationen (Addition, Subtraktion, Multiplikation usw.), wobei im Kontext der probabilistischen Gegenstücke, Zufallsvariablen häufig als statistisch unabhängig behandelt werden. Die Algebra bietet eine numerische Stabilität, die dem deterministischen Gegenstück (d.h. einfachen Zahlen) fast gleich ist. Alle Zwischenergebnisse können für die spätere Verwendung bestehen bleiben, was sich für die Organisation und Fehlersuche in der Datenpipeline als sehr praktisch erweist. Nachteilig ist die Ausdrucksfähigkeit dieser Algebren, die tendenziell begrenzt ist. So ist es gewöhnlich nicht möglich, alle subtilen konditionellen Abhängigkeiten auszudrücken, die zwischen den Zufallsvariablen bestehen.
Die probabilistische Programmierung betrachtet das Problem aus einer Monte-Carlo-Perspektive. Die Logik wird einmal geschrieben, gewöhnlich mit einem vollständig deterministischen Ansatz, aber mehrere Male durch das Tool (d. h. den Monte-Carlo-Prozess) ausgeführt, um die gewünschten Statistiken zu sammeln. Maximale Ausdrucksfähigkeit wird durch „programmatische“ Konstrukte erreicht: es können beliebige, komplexe Abhängigkeiten zwischen den Zufallsvariablen modelliert werden. Auch das Schreiben der Logik selbst über die probabilistische Programmierung ist im Vergleich zu einer Algebra der Zufallsvariablen tendenziell etwas einfacher, da die Logik nur reguläre Zahlen beinhaltet. Auf der Kehrseite muss stets zwischen der numerischen Stabilität (mehr Iterationen ergeben eine bessere Genauigkeit) und den Rechenressourcen (mehr Iterationen kosten mehr) abgewogen werden. Darüber hinaus sind Zwischenergebnisse typischerweise nicht ohne weiteres zugänglich, da sie nur vorübergehend existieren – gerade um den Bedarf an Rechenressourcen zu mindern.
Neueren Arbeiten im Bereich Deep Learning zufolge gibt es über die beiden oben vorgestellten Ansätze hinaus noch weitere. Beispielsweise bieten Variations-Autoencoder (VAE) die Möglichkeit, Operationen über
latente Räume auszuführen, die beeindruckende Ergebnisse liefern, indem sie sehr komplexe Transformationen über die Daten verfolgen (z.B.: automatische Entfernung von Brillen aus einem Portrait). Obwohl diese Ansätze konzeptionell äußerst faszinierend sind, zeigen sie bis heute keine große praktische Relevanz bei der Lösung von Lieferkettenproblemen.
Visualisierung probabilistischer Vorhersagen
Die einfachste Form, eine diskrete Wahrscheinlichkeitsverteilung zu visualisieren, ist ein Histogramm, bei dem die vertikale Achse die Wahrscheinlichkeit und die horizontale Achse den Wert der gewünschten Zufallsvariablen angibt. Die probabilistische Prognose einer Durchlaufzeit kann z. B. wie folgt dargestellt werden:
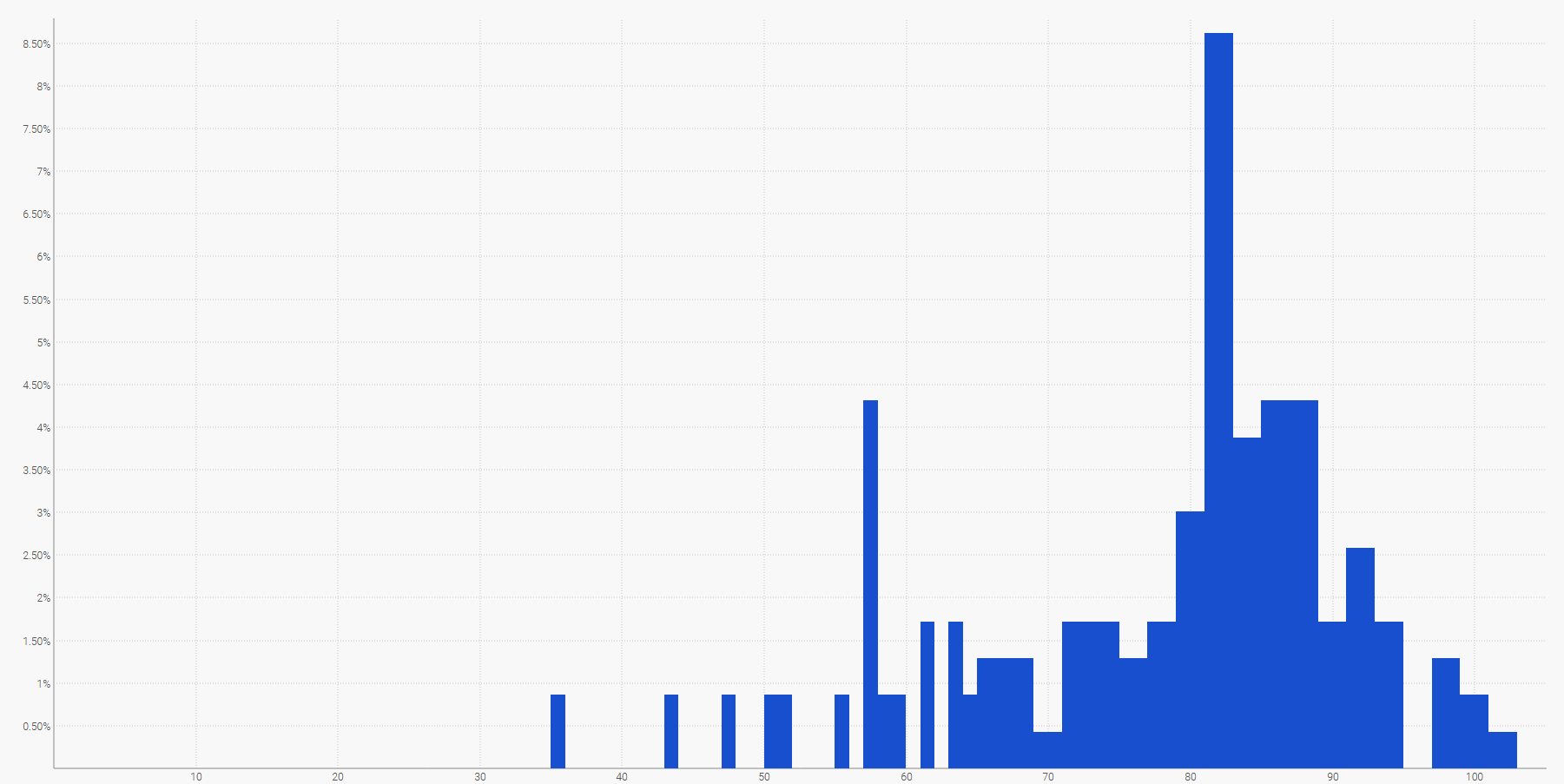 Eine empirische Verteilung der beobachteten Durchlaufzeiten in täglichen Buckets (Klassen).
Eine empirische Verteilung der beobachteten Durchlaufzeiten in täglichen Buckets (Klassen).Auch der zukünftige Bedarf, über einen bestimmten Zeitraum addiert, kann durch ein Histogramm dargestellt werden. Ganz allgemein ist das Histogramm für alle eindimensionalen Zufallsvariablen, die über $\mathbb{Z}$, der Menge der relativen ganzen Zahlen, liegt, gut geeignet.
Die Visualisierung des probabilistischen Version einer Zeitreihe mit gleichen Abständen – also einer über diskrete Zeiträume gleicher Länge variierenden Menge – ist deutlich anspruchsvoller. Tatsächlich gibt es, anders als bei eindimensionalen Zufallsvariablen, keine kanonische Darstellung einer solchen Verteilung. Außerdem darf nicht davon ausgegangen werden, dass die Zeiträume unabhängig voneinander sind. Obwohl es also möglich ist, eine „probabilistische“ Zeitreihe durch Aneinanderreihung von Histogrammen – eines pro Zeitraum – darzustellen, würde diese Darstellung die Art und Weise, in der sich die Ereignisse in einer Lieferkette entfalten, stark verfälschen.
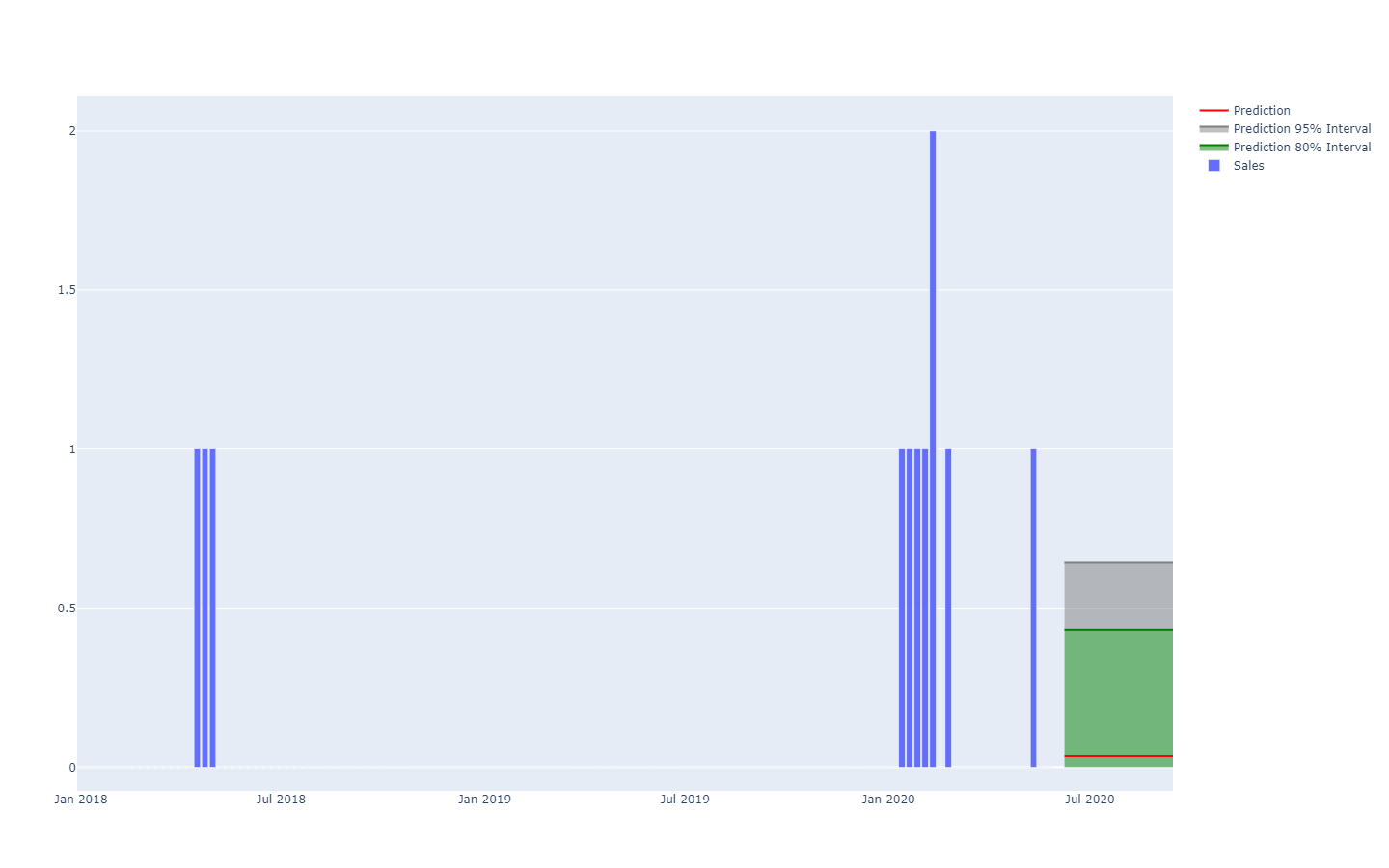 Eine probabilistische Bedarfsprognose über Quantilgrenzen dargestellt.
Eine probabilistische Bedarfsprognose über Quantilgrenzen dargestellt.Beispielweise ist nicht allzu unwahrscheinlich, dass ein neu eingeführtes Produkt gut läuft und ein hohes Absatzvolumen erreicht (ein Hit). Es ist auch nicht allzu unwahrscheinlich, dass das gleiche neu eingeführte Produkt scheitert und mit einem geringen Absatzvolumen verbunden ist (ein Flop). Allerdings sind große tägliche Schwankungen zwischen Absatzzahlen, die sich zwischen einem Hit und einem Flop bewegen, äußerst unwahrscheinlich.
Vorhersageintervalle, wie sie in der Literatur zur Supply-Chain häufig vorkommen, sind etwas irreführend. Sie neigen dazu, Situationen mit geringer Ungewissheit zu betonen, die für tatsächliche Supply-Chain-Fälle nicht repräsentativ sind;
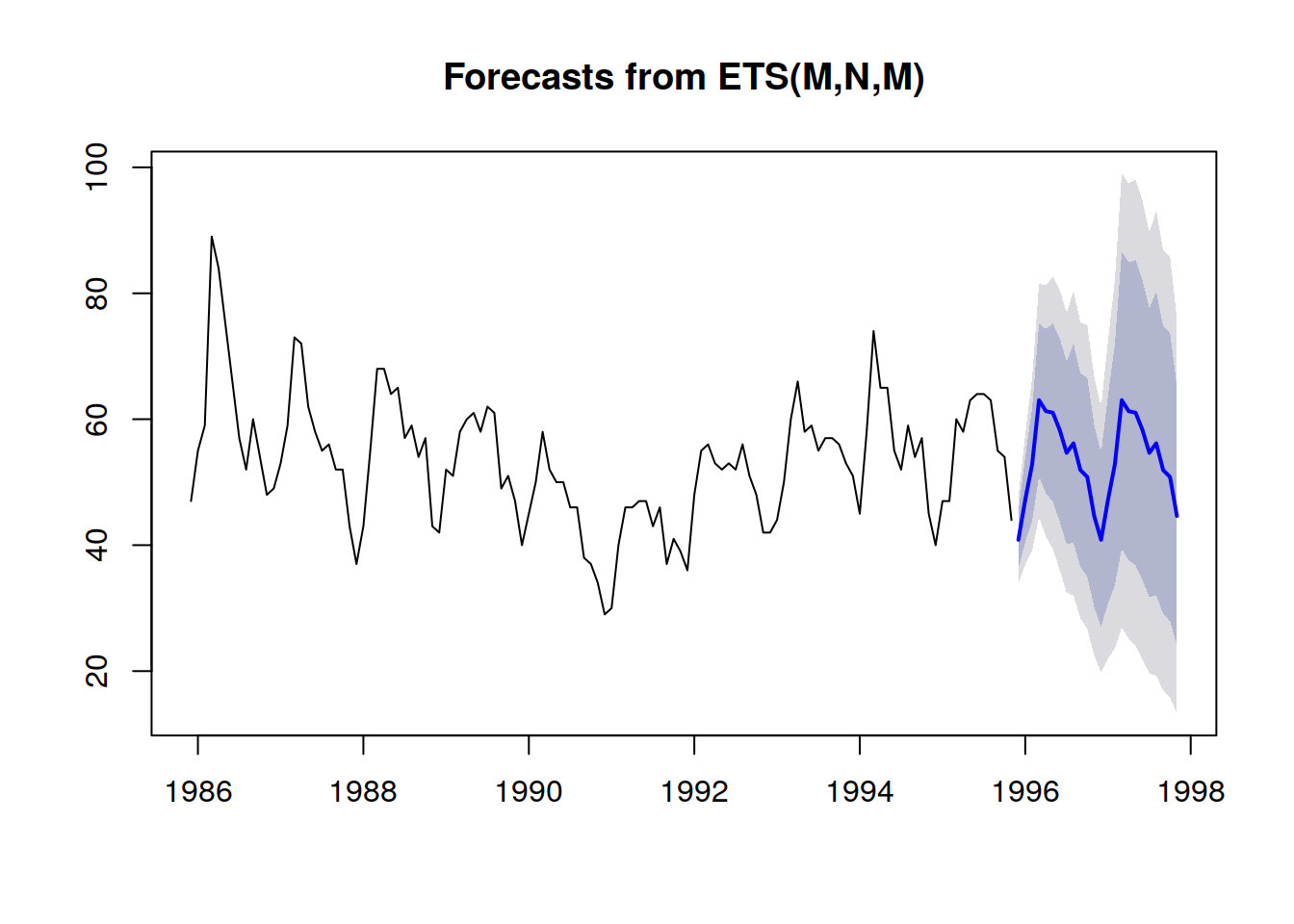 Auszug aus Visualization of probabilistic forecasts, von Rob J Hyndman, 21. November 2014
Auszug aus Visualization of probabilistic forecasts, von Rob J Hyndman, 21. November 2014Beachten Sie, dass es sich bei diesen Vorhersageintervallen genau um die Wahrscheinlichkeitsverteilungen handelt, die mit einem Farbschema nebeneinander gestellt werden, um bestimmte Quantilgrenzen darzustellen.
Eine bessere Darstellung – also eine, die starke Abhängigkeiten innerhalb eines Zeitraums nicht verbessert – ist die Betrachtung der
kumulierten Werte im Laufe der Zeit, wobei die Quantile dieser Werte genommen und dann differenziert werden, um die Erhöhungen pro Zeitraum festzustellen (siehe die erste Darstellung einer probabilistischen Prognose am Anfang dieses Artikels). Die Visualisierung ist die gleiche, aber die zugrundeliegende
Semantik ist unterschiedlich. Wir betrachten nun Quantile über
Szenarien, die die extrem günstigen (bzw. ungünstigen) Szenarien schildern.
Antipatterns in der probabilistischen Vorhersage
Probabilistische Prognosen stellen die Art und Weise, in der viele Menschen „intuitiv“ über die Zukunft denken, in Frage. In diesem Abschnitt behandeln wir einige der am häufigsten missverstandenen Aspekte der probabilistischen Prognose.
So etwas wie „unvorhersehbare“ Ereignisse gibt es nicht
Aus deterministischer Sicht ist es unmöglich, die Lottozahlen vorherzusagen, da die Wahrscheinlichkeit, richtig zu liegen, „eins zu einer Million“ steht. Aus probabilistischer Sicht ist das Problem jedoch trivial: Jedes Los hat eine Gewinnchance von „eins zu einer Million“. Die sehr hohe Varianz des Ergebnisses sollte nicht mit einer bestimmtem „Ungewissheit“ um das eigentliche Phänomen verwechselt werden, das durchaus verstanden werden kann, wie es bei einer Lotterie der Fall ist. Bei der probabilistischen Prognose geht es um die Quantifizierung und Strukturierung der Varianz, nicht um ihre Beseitigung.
So etwas wie „Normalverteilungen“ gibt es nicht
Normalverteilungen, auch als Gauß-Verteilungen bekannt, sind sowohl in Supply-Chain- als auch in Physik-Lehrbüchern allgegenwärtig. Doch was menschlichen Angelegenheiten angeht, ist so gut wie nichts „normalverteilt“. Normalverteilungen sind so konzipiert, dass große Abweichungen (im Vergleich zu den durchschnittlichen Abweichungen) äußerst selten sind, so selten, dass sie vom Modell als schlichtweg unmöglich ausgeschlossen werden – etwa Wahrscheinlichkeiten, die unter als eins zu einer Milliarde liegen. Jedoch sind Bedarf, Durchlaufzeit, Rücksendung viele Muster, die kategorisch nicht normalverteilt sind. Der einzige Vorteil von Normalverteilungen ist, dass sie gute Lehrbuchaufgaben für Studenten darstellen, da sie sich für explizite analytische Lösungen eignen.
Rosinenpickerei bei Wahrscheinlichkeiten
Steht man vor einer Wahrscheinlichkeitsverteilung, ist es verlockend, sich einen Punkt der Verteilung herauszupicken, möglicherweise den Mittelwert oder den Median, und auf Grundlage dieser Zahl weiterzuarbeiten. Dieser Vorgang widerspricht im Wesentlichen dem probabilistischen Aspekt der Prognose. Wahrscheinlichkeiten sollten nicht zu einem einzigen Schätzwert zusammengefasst werden, da dieser Vorgang – unabhängig davon, welcher Punkt gewählt wird – einen massiven Informationsverlust mit sich bringt. Auch wenn es etwas umständlich erscheint, sollten die Wahrscheinlichkeiten so lange wie möglich erhalten bleiben. Der Punkt an dem die Information des zusammengefasst wird ist typischerweise die letzte Entscheidung in der Supply-Chain, die die Rendite bei einer ungewissen Zukunft maximiert.
Statistische Ausreißer entfernen
Die meisten klassischen numerischen Methoden – fest verankert in der deterministischen Perspektive der Prognosen (z.B. gleitende Mittelwerte) – bieten beim Vorliegen statistischer Ausreißer kein gutes Verhalten. Daher führen viele Unternehmen Prozesse ein, um die historischen Daten manuell von diesen Ausreißern zu „bereinigen“. Die Notwendigkeit eines solchen Bereinigungsprozesses veranschaulicht jedoch nur die Unzulänglichkeiten dieser numerischen Methoden. Ganz im Gegenteil sind statistische Ausreißer ein wesentlicher Bestandteil der probabilistischen Prognose, da sie dazu beitragen, ein besseres Bild davon zu bekommen, was "am Ende" der Verteilung passiert. Mit anderen Worten sind diese Ausreißer der Schlüssel, um die Wahrscheinlichkeit zu quantifizieren, mit der man auf weitere Ausreißer stoßen könnte.
Mit dem Schwert zu einer Schießerei
Für die Bearbeitung von Wahrscheinlichkeitsverteilungen sind spezielle Tools erforderlich. Die Erstellung der probabilistischen Prognose stellt dabei nur einen Schritt von vielen dar, um einen tatsächlichen Wert für das Unternehmen zu schöpfen. Viele Supply-Chain-Fachkräfte verwerfen probabilistische Prognosen, da ihnen das geeignete Werkzeuge fehlt, um etwas damit anfangen zu können. Viele Anbieter von Unternehmenssoftware sind auf den Zug aufgesprungen und behaupten nun, „probabilistische Prognosen“ zu unterstützen (zusammen mit „KI“ und „Blockchain“). Oft bieten sie aber außer einer kosmetischen Implementierung einiger probabilistischer Modelle (vgl. den vorangehenden Abschnitt) nichts weiteres. Das Angebot eines probabilistischen Prognosemodells taugt so gut wie nichts, wenn nicht gleichzeitig umfangreiche Tools verfügbar sind, um die numerischen Ergebnisse zu nutzen.
Hinweise
[1]: Die
smooth()-Funktion in Envision ist für die Regularisierung von Zufallsvariablen durch einen diskreten Sampling-Prozess jeglicher Art nützlich.
[2]: Vorwissen über die Struktur des Problems sollte nicht mit Vorwissen über die Lösung selbst verwechselt werden. Die bereits in den 1950er Jahren entwickelten „Expertensysteme“ als Sammlung handgeschriebener Regeln scheiterten, weil menschliche Experten in der Praxis daran scheitern, ihre Intuition wörtlich in numerische Regeln zu übersetzen. Strukturelle Prioritäten, wie sie in der differenzierbaren Programmierung verwendet werden, bieten einen Überblick über das Prinzip der Lösung und nicht über ihre Details.


